 计算机基础知识之汇编语言2
计算机基础知识之汇编语言2
对栈进行push 和 pop
❝程序运行时,会在内存上申请分配一个称为 「栈」 的数据空间。
❞
在栈中,数据在存储时是从内存的下层(大的地址编号)逐渐往上层(小的地址编号)累积,读出时则是按照从上往下的顺序进行。
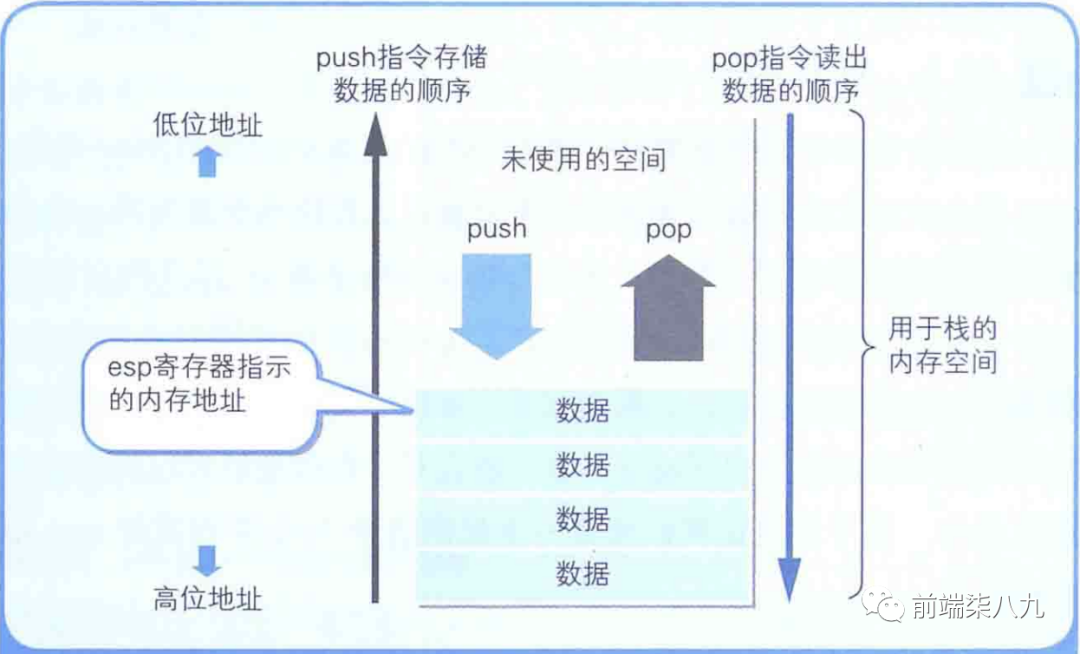
栈是 「存储临时数据的区域」 ,它的特点是通过push指令和pop指令进行数据的存储和读出。push指令和pop指令中只有一个操作数。该操作数表示的是 「push的是什么及pop的是什么」 ,而不需要指定”对哪一个地址编号的内存进行push或pop“。
这是因为,对栈进行读写的内存地址是有esp寄存器(栈指针)进行管理的。push指令和pop指令运行后,esp寄存器的值会 「自动进行更新」 (push指令是-4,pop指令是+4),因而就没有必要指定内存地址了。
函数调用机制
假设存在如下的C语言代码片段。
// 返回两个参数值之和的函数
int AddNum(int a,int b){
return a + b;
}
// 调用AddNum函数的函数
void MyFunc(){
int c;
c = AddNum(123,456);
}
转换成对应的汇编语言的代码如下。

这里我们先介绍(3)~(6)的部分,这对了解函数调用的机制很重要。
(3)和(4)表示的是将传递给AddNum函数的参数通过push入栈。在C语言中,虽然记述为函数AddNum(123,456),但入栈的则会按照456、123这样的顺序,也就是位于 「后面的数值先入栈」 。
(5)的call指令,把程序流程跳转到了操作数中指定的AddNum函数所在的内存地址处。在汇编语言中, 「函数名表示的是函数所在的内存地址」 。AddNum函数处理完毕后,程序流程必须要返回到编号(6)这一行。call指令运行后,call指令的下一行((6)这一行)的内存地址会 「自动」 push入栈。该值会在AddNum函数处理的最后通过ret指令pop出栈,然后程序流程就会返回到(6)这一行。
(6)部分会把栈中存储的两个参数(456和123)进行销毁处理,也就是 「栈清理处理」 。虽然通过使用两次pop指令也可以实现,不过 「采用esp寄存器加8的方式更有效率」 (处理一次)。对栈进行数值的输入输出时,数值的单位是4字节。因此,通过在栈地址管理的esp寄存器加上4的2倍8,就可以达到和运行两次pop命令同样的效果。

AddNum函数调用前后栈的状态变化
函数内部的处理
继续分析执行AddNum函数的源代码部分。
ebp寄存器的值在(1)中入栈,在(5)中出栈。这主要是为了把函数中用到的ebp寄存器的内容,恢复到函数调用前的状态。CPU拥有的寄存器是有数量的限制的。在函数调用前,调用源有可能已经在使用ebp寄存器了。因而, 「在函数内部用的寄存器,要尽量返回到函数调用前的状态」 。
(2)中负责管理栈地址的esp寄存器的值赋值到了ebp寄存器中。这是因为,在mov指令中方括号内的参数,是不允许指定esp寄存器的。因此,这里就采用了不直接通过esp,而是用ebp寄存器来读写栈内容的方法。
(3)是用[ebp+8]指定栈中存储的第1个参数123,并将其读出到eax寄存器中。eax寄存器是负责运算的累加寄存器
通过(4)的add指令,把当前eax寄存器的值同第2个参数相加后的结果存储在eax寄存器中。 「函数的参数是通过栈来传递,返回值是通过寄存器来返回的」 。
(6)中ret指令运行后,函数返回目的地的内存地址会自动出栈。

AddNum函数内部的栈状态变化
全局变量用的内存空间
在一些高级编程语言中,在函数外部定义的变量称为 「全局变量」 ,在函数内部定义的变量称为 「局部变量」 。全局变量可以在源代码的任意部分被引用,而局部变量只能在定义该变量的函数内进行引用。
高级程序语言被编译后,会被归类到名为 「段」 定义的组。
- 初始化的全局变量被汇总到名为
_DATA的段定义中 - 没有初始化的全局变量被汇总到名为
_BSS的段定义中 - 指令被汇总到名为
_TEXT的段定义中
局部变量的内存空间
「局部变量只能在定义该变量的函数内进行引用」 ,这是因为,局部变量是临时保存在寄存器和栈中的。
函数内部利用的栈,在函数处理完毕后会恢复到初始状态,因此局部变量的值也就会被销毁,而寄存器也可能被用于其他目的。因此,局部变量只是在函数处理运行期间临时存储在寄存器和栈上。

用于局部变量的栈空间的申请分配和释放
循环处理的实现方法
假设我们存在如下的代码,将局部变量i作为循环计数器连续进行10次循环的C语言源代码。
// 定义MySub函数
void MySub(){
// 省略部分处理
}
// 定义MyFunc函数
void MyFunc(){
int i;
for(i=0;i<10;i++){
// 重复调用MySub函数10次
MySub();
}
}
将上述的代码转换成汇编语言如下(仅展示for片段)

C语言的for语句是通过在括号中指定 「循环计数器」 的初始值(i=0)、循环的继续条件(i<10)、循环计数器的更新(i++)这3种形式来进行循环处理。与此相对,
❝在汇编语言的源代码中,循环是通过 「比较指令」 (
cmp)和 「跳转指令」 (jl)来实现。❞
具体流程我们就不在这里赘述。这里挑选比较重要的点来分析下。
cmp指令是用来对第一个操作数和第二个操作数的数值进行比较的指令。cmp ebx,10就相当于C语言的i<10这一处理,意思是把ebx寄存器的数值同10进行比较。汇编语言中比较指令的结果,会存储在CPU的 「标志寄存器」 中。
最后一行的jl是jump on less than(小于的话就跳转)的意思。也就是说,jl short @4的意思就是,前面运行的比较指令的结果,若 「小」 的话就跳转到@4这个 「标签」 。
条件分支的实现方式
条件分支的实现方法同循环的实现方法类似,使用的也是cmp指令和跳转指令。
-
cpu
+关注
关注
68文章
10854浏览量
211574 -
计算机
+关注
关注
19文章
7488浏览量
87849 -
C语言
+关注
关注
180文章
7604浏览量
136683 -
编译器
+关注
关注
1文章
1623浏览量
49108
发布评论请先 登录
相关推荐
计算机的基础知识
计算机组成原理与汇编语言程序设计

微机原理与汇编语言程序设计课件

计算机学习教程之指令系统与汇编语言程序设计课件免费下载
计算机的机器语言和汇编语言与高级语言的详细资料介绍
[从零学习汇编语言] - 计算机中的硬件与软件
![[从零学习<b class='flag-5'>汇编语言</b>] - <b class='flag-5'>计算机</b>中的硬件与软件](https://file.elecfans.com/web1/M00/D9/4E/pIYBAF_1ac2Ac0EEAABDkS1IP1s689.png)
构建 4 位计算机:汇编语言和汇编器(第 2 部分)
构建 4 位计算机:汇编语言和汇编器(第 1 部分)
计算机基础知识之汇编语言1





 工商网监
工商网监
评论