 重新审视Prompt优化问题,预测偏差让语言模型上下文学习更强
重新审视Prompt优化问题,预测偏差让语言模型上下文学习更强
LLMs 在 In-context Learning 下取得了良好的表现,但是选取不同的示例会导致截然不同的表现。一项最新的研究工作从预测偏差 (predictive bias) 角度,提出了 prompt 搜索策略,近似找到了最优的示例组合。

研究介绍
大型语言模型在上下文学习中表现出了惊人的能力,这些模型可以通过几个输入输出示例构建的上下文进行学习,无需微调优化直接应用于许多下游任务。然而,先前的研究表明,由于训练样本 (training examples)、示例顺序 (example order) 和提示格式 (prompt formats) 的变化,上下文学习可能会表现出高度的不稳定性。因此,构建适当的 prompt 对于提高上下文学习的表现至关重要。
以前的研究通常从两个方向研究这个问题:1)编码空间中的提示调整 (prompt tuning);2)在原始空间中进行搜索 (prompt searching)。
Prompt tuning 的关键思想是将任务特定的 embedding 注入隐藏层,然后使用基于梯度的优化来调整这些 embeddings。然而,这些方法需要修改模型的原始推理过程并且获得模型梯度,这在像 GPT-3 和 ChatGPT 这样的黑盒 LLM 服务中是不切实际的。此外,提示调整会引入额外的计算和存储成本,这对于 LLM 通常是昂贵的。
更可行且高效的方法是通过在原始文本空间中搜索近似的演示样本和顺序来优化提示。一些工作从 “Global view” 或 “Local view” 构建提示。基于 Global view 的方法通常将提示的不同元素作为整体进行优化,以达到更优异的性能。例如,Diversity-guided [1] 的方法利用演示的整体多样性的搜索,或者试图优化整个示例组合顺序 [2],以实现更好的性能。与 Global view 相反,基于 Local view 的方法通过设计不同的启发式选择标准,例如 KATE [3]。
但这些方法都有各自的局限性:1)目前的大多数研究主要集中在沿着单个因素搜索提示,例如示例选择或顺序。然而各个因素对性能的总体影响尚不清楚;2)这些方法通常基于启发式标准,需要一个统一的视角来解释这些方法是如何工作的;3)更重要的是,现有的方法会全局或局部地优化提示,这可能会导致性能不理想。
本文从 “预测偏差” 的角度重新审视了 NLP 领域中的 prompt 优化问题,发现了一个关键现象:一个给定的 prompt 的质量取决于它的内在偏差。基于这个现象,文章提出了一个基于预测偏差的替代标准来评估 prompt 的质量,该度量方法能够在不需要额外开发集 (development set) 的情况下通过单个前向过程来评估 prompt。
具体来说,通过在一个给定的 prompt 下输入一个 “无内容” 的测试,期望模型输出一个均匀的预测分布(一个 “无内容” 的输入不包含任何有用的信息)。因此,文中利用预测分布的均匀性来表示给定 prompt 的预测偏差。
这与先前的后校准方法 [4] 用的指标类似,但与后校准在固定的 prompt 情况下使用这个 metric 进行概率后校准不同的是,文中进一步探索了其在自动搜索近似 prompt 中的应用。并通过大量实验证实了一个给定 prompt 的内在偏差和它在给定测试集上的平均任务表现之间的相关性。
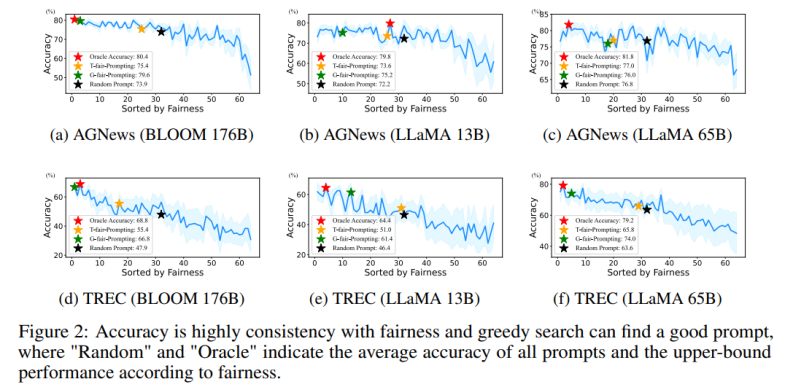
此外,这种基于偏差的度量使该方法能够以 “局部到全局” 的方式搜索合适的 prompt。然而,一个现实的问题是无法通过遍历所有组合的方式搜索最优解,因为它的复杂度将超过 O (N!)。
该工作提出了两种新颖的策略以高效的方式搜索高质量的 prompt:(1) T-fair-Prompting (2) G-fair-Prompting。T-fair-Prompting 使用一种直观的方式,首先计算每个示例单独组成 prompt 的偏差,然后选择 Top-k 个最公平示例组合成最终 prompt。
这个策略相当高效,复杂度为 O (N)。但需要注意的是,T-fair-Prompting 基于这样的假设:最优的 prompt 通常是由偏差最小的示例构建的。然而,这在实际情况下可能并不成立,并且往往会导致局部最优解。
因此,文章中进一步介绍了 G-fair-Prompting 来改善搜索质量。G-fair-Prompting 遵循贪心搜索的常规过程,通过在每个步骤上进行局部最优选择来找到最优解。在算法的每一步,所选择的示例都能使更新的 prompt 获得最佳的公平性,最坏情况时间复杂度为 O (N^2),搜索质量显著提高。G-fair-Prompting 从局部到全局的角度进行工作,其中在早期阶段考虑单个样本的偏差,而在后期阶段则侧重于减少全局预测偏差。
实验结果
该研究提出了一种有效和可解释的方法来提高语言模型的上下文学习性能,这种方法可以应用于各种下游任务。文章验证了这两种策略在各种 LLMs(包括 GPT 系列模型和最近发布的 LMaMA 系列)上的有效性,G-fair-Prompting 与 SOTA 方法相比,在不同的下游任务上获得了超过 10%的相对改进。
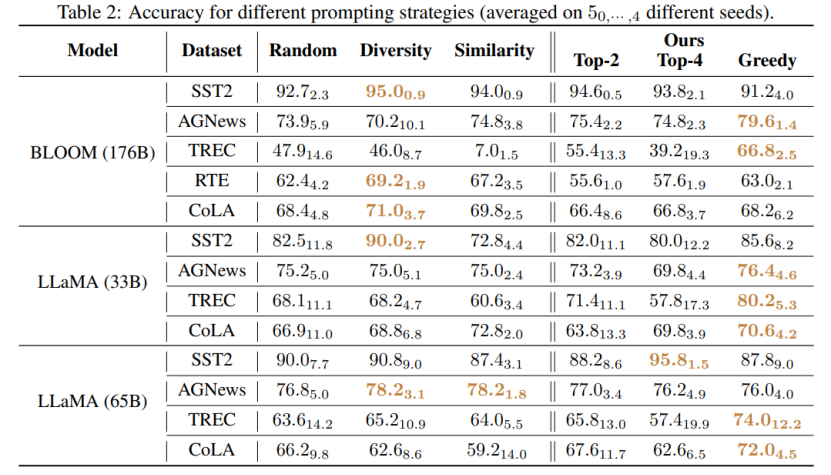
与该研究最相近的是 Calibration-before-use [4] 方法,两者都使用 “无内容” 的输入提高模型的表现。但是,Calibration-before-use 方法旨在使用该标准来校准输出,而该输出仍然容易受到所使用示例的质量的影响。与之相比,本文旨在搜索原始空间找到近似最优的 prompt,以提高模型的性能,而不需要对模型输出进行任何后处理。此外,该文首次通过大量实验验证了预测偏差与最终任务性能之间的联系,这在 Calibration-before-use 方法中尚未研究。

通过实验还能发现,即使不进行校准,该文章所提方法选择的 prompt 也可以优于经过校准的随机选择的 prompt。这表明该方法可以在实际应用中具有实用性和有效性,可以为未来的自然语言处理研究提供启示。
审核编辑 :李倩
-
语言模型
+关注
关注
0文章
550浏览量
10403
原文标题:重新审视Prompt优化问题,预测偏差让语言模型上下文学习更强
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
为什么transformer性能这么好?Transformer的上下文学习能力是哪来的?
关于进程上下文、中断上下文及原子上下文的一些概念理解
进程上下文与中断上下文的理解
基于多Agent的用户上下文自适应站点构架
基于交互上下文的预测方法
终端业务上下文的定义方法及业务模型
基于Pocket PC的上下文菜单实现
基于Pocket PC的上下文菜单实现
基于上下文相似度的分解推荐算法
Web服务的上下文的访问控制策略模型
初学OpenGL:什么是绘制上下文
如何分析Linux CPU上下文切换问题
谷歌新作SPAE:GPT等大语言模型可以通过上下文学习解决视觉任务

首篇!Point-In-Context:探索用于3D点云理解的上下文学习






 工商网监
工商网监
评论