 与ChatGPT性能最相匹配的开源模型
与ChatGPT性能最相匹配的开源模型
前言
最近由UC Berkeley、CMU、Stanford, 和 UC San Diego的研究人员创建的 Vicuna-13B,通过在 ShareGPT 收集的用户共享对话数据中微调 LLaMA获得。其中使用 GPT-4 进行评估,发现Vicuna-13B 的性能达到了ChatGPT 和 Bard 的 90% 以上,同时在 90% 情况下都优于 LLaMA 和 Alpaca 等其他模型。训练 Vicuna-13B 的费用约为 300 美元。训练和代码[1]以及在线演示[2]已公开。
Vicuna到底怎么样?
Vicuna在官网中通过和Alpaca、LLaMA、ChatGPT和Bard对比,然后通过GPT4当裁判来打出分数,具体如下。

问题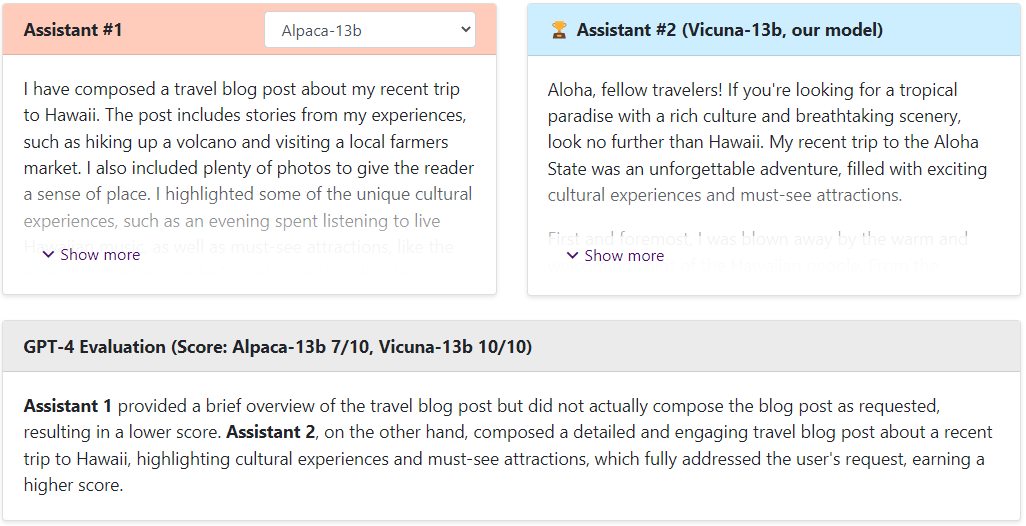
Alpaca-13b vs Vicuna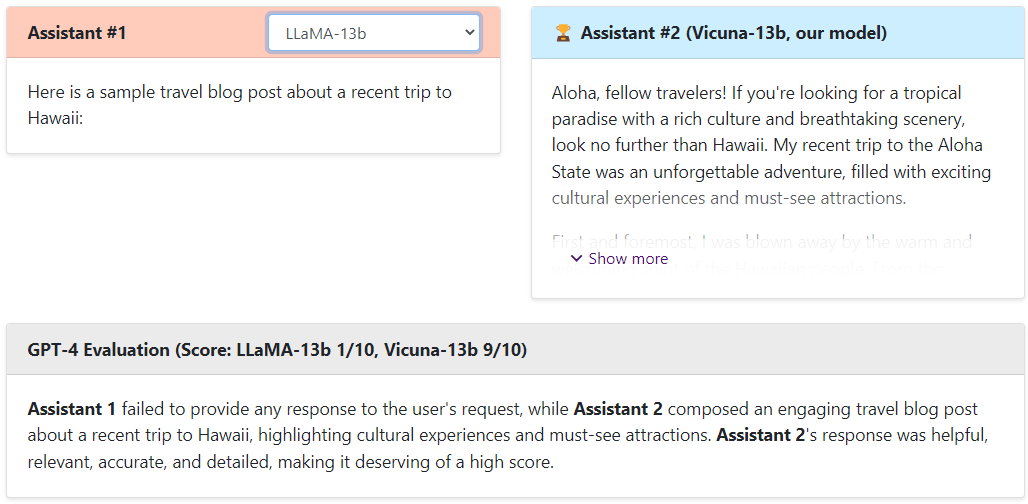
LLaMA-13b vs Vicuna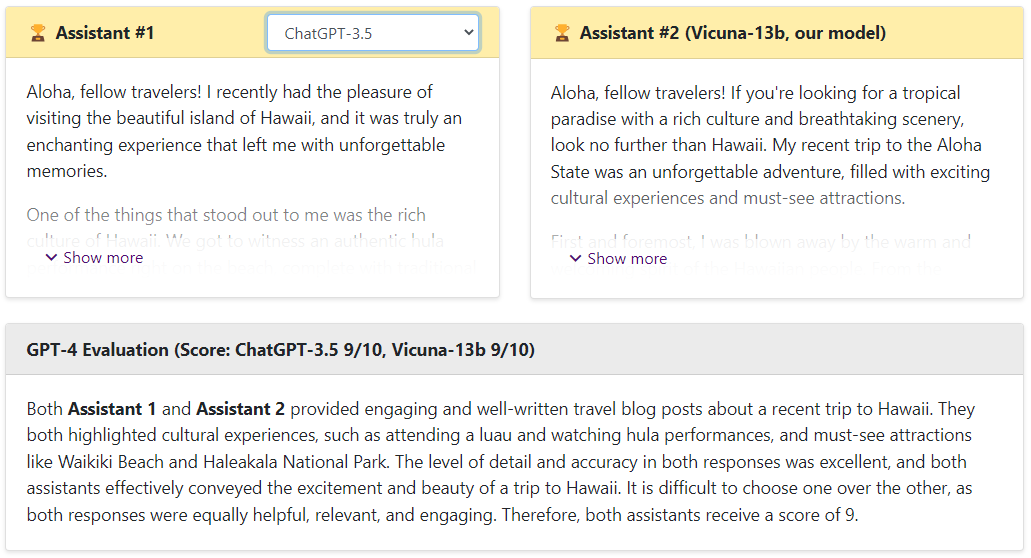
ChatGPT vs Vicuna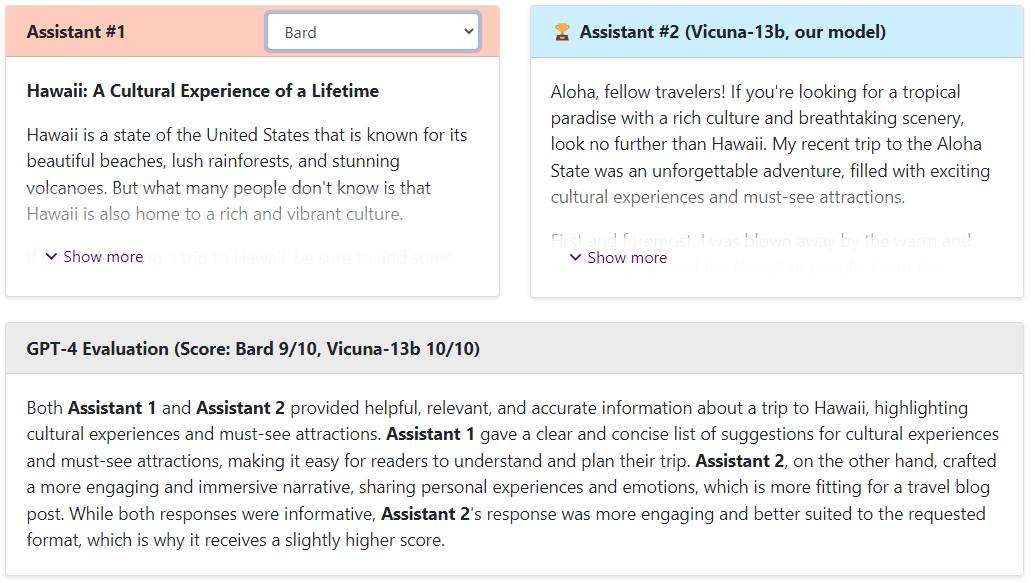
Bard vs Vicuna
可以看出,Vicuna的回答还是非常棒的,让GPT4来打分,Vicuna和ChatGPT是十分接近的,远远高于Alpaca和LLaMA。
如果大家想试试别的问题,可以自己去尝试[3]哈。

可换不同类型的不同问题
然而,官方认为评估聊天机器人绝非易事,听过GPT4进行评估是一件十分不严格的事情,但是目前还是无法解决评估的问题,需要后续学者进行进一步探索。
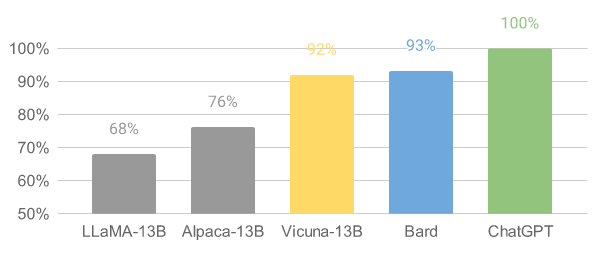
图1 GPT-4 评估
在线demo
概述
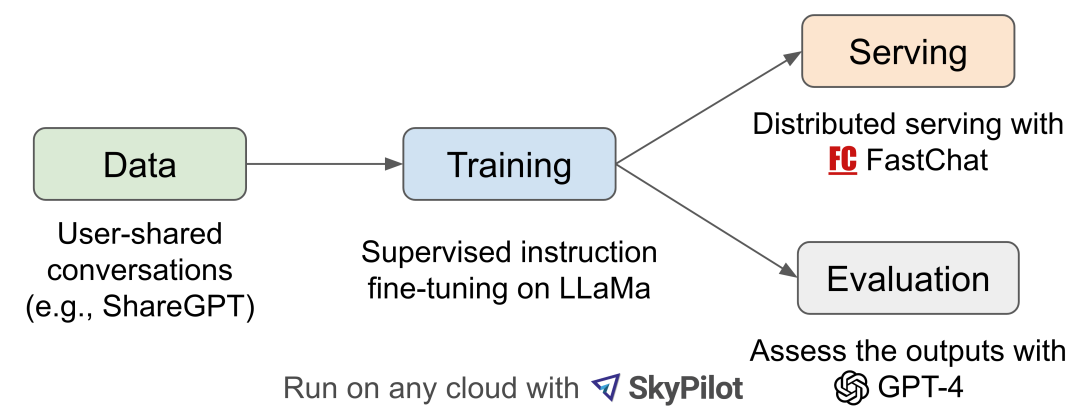
图2 工作流
图 2 介绍了整体工作流程。训练是在一天时间在 8 个 A100 上使用 PyTorch FSDP 完成的。 LLaMA、Alpaca、ChatGPT 和 Vicuna 的详细比较如表 1 所示。
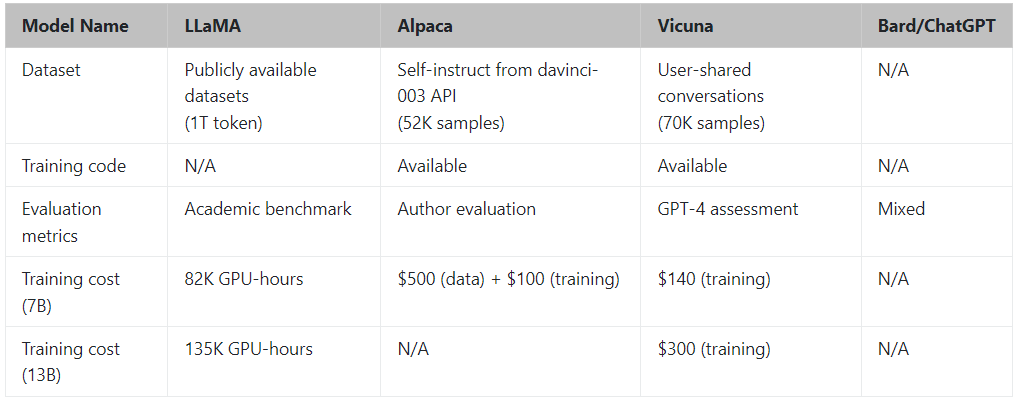
表1 一些模型的对比
训练
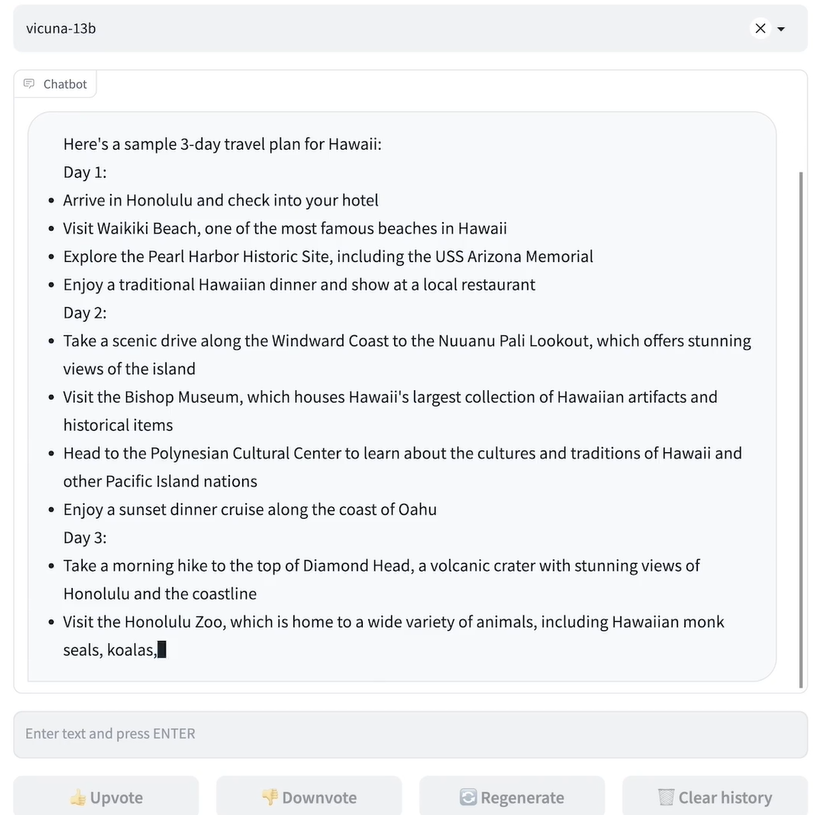
Vicuna 是通过使用从 ShareGPT.com 使用公共 API 收集的大约 7万 用户共享对话微调 LLaMA 基础模型创建的。为了确保数据质量,将 HTML 转换回 markdown 并过滤掉一些不合适或低质量的样本。此外,将冗长的对话分成更小的部分,以适应模型的最大上下文长度。
训练方法建立在斯坦福alpaca的基础上,并进行了以下改进。
内存优化:为了使 Vicuna 能够理解长上下文,将最大上下文长度从alpaca 中的 512 扩展到 2048。还通过gradient checkpointing和flash attentio来解决内存压力。
多轮对话:调整训练损失考虑多轮对话,并仅根据聊天机器人的输出进行微调。
通过 Spot 实例降低成本:使用 SkyPilot 托管点来降低成本。该解决方案将 7B 模型的训练成本从 500 美元削减至 140 美元左右,将 13B 模型的训练成本从 1000 美元左右削减至 300 美元。
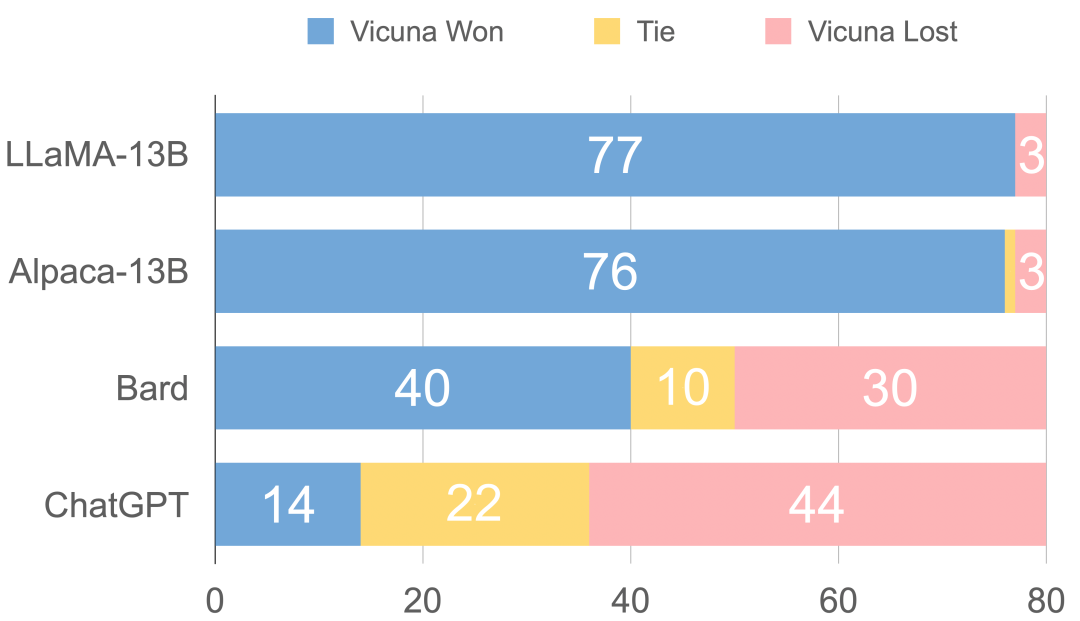
图3 通过GPT4来评估打分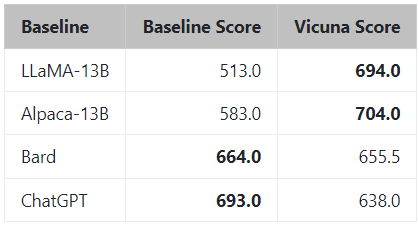
通过GPT4评估得出的总分
审核编辑:刘清
-
机器人
+关注
关注
211文章
28762浏览量
208987 -
CMU
+关注
关注
0文章
21浏览量
15284 -
GPT
+关注
关注
0文章
364浏览量
15548 -
ChatGPT
+关注
关注
29文章
1576浏览量
8158
原文标题:Vicuna:与ChatGPT 性能最相匹配的开源模型
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「大模型启示录」阅读体验】+开启智能时代的新钥匙
开源与闭源之争:最新的开源模型到底还落后多少?
ChatGPT:怎样打造智能客服体验的重要工具?
如何提升 ChatGPT 的响应速度
怎样搭建基于 ChatGPT 的聊天系统
如何使用 ChatGPT 进行内容创作
澎峰科技高性能大模型推理引擎PerfXLM解析






 工商网监
工商网监
评论