 GPT模型成功的背后用到了哪些以数据为中心的人工智能技术?
GPT模型成功的背后用到了哪些以数据为中心的人工智能技术?
人工智能(Artificial Intelligence, AI)最近取得了巨大的进展,特别是大语言模型(Large Language Models, LLMs),比如最近火爆全网的ChatGPT和GPT-4。GPT模型在各项自然语言处理任务上有着惊人的效果。至于具体有多强,这里就不再赘述了。做了这么多年AI研究好久没这么激动过了。没试过的朋友赶紧试一下!
正所谓「大力出奇迹」,把参数量调「大」能提高模型性能已经成为了大家的普遍共识。但是仅仅增加模型参数就够了吗?仔细阅读GPT的一系列论文后就会发现,仅仅增加模型参数是不够的。它们的成功在很大程度上还归功于用于训练它们的大量和高质量的数据。
在本文中,我们将从数据为中心的人工智能视角去分析一系列GPT模型(之后会用Data-centric AI以避免啰嗦)。Data-centric AI大体上可以分文三个目标:训练数据开发(training data development)、推理数据开发(inference data development)和数据维护(data maintenance)。本文将讨论GPT模型是如何实现(或者可能即将实现)这三个目标的。感兴趣的读者欢迎戳下方链接了解更多信息。
综述论文:Data-centric Artificial Intelligence: A Survey
短篇介绍:Data-centric AI: Perspectives and Challenges
GitHub资源(不定期持续更新,欢迎贡献):https://github.com/daochenzha/data-centric-AI
1
什么是大语言模型?
什么又是GPT模型?
这章将简单介绍下大语言模型和GPT模型,对它们比较熟悉的读者可以跳过。大语言模型指的是一类自然语言处理模型。顾名思义,大语言模型指的是比较「大」的(神经网络)语言模型。语言模型在自然语言处理领域已经被研究过很久了,它们常常被用来根据上文来推理词语的概率。例如,大语言模型的一个基本功能是根据上文预测缺失词或短语的出现概率。我们常常需要用到大量的数据去训练模型,使得模型学到普遍的规律。

通过上文来预测缺失词示意图
GPT模型是由OpenAI开发的一系列大语言模型,主要包括GPT-1,GPT-2,GPT-3,InstructGPT以及最近上线的ChatGPT/GPT-4。就像其他大语言模型一样,GPT模型的架构主要基于Transformer,以文本和位置信息的向量为输入,使用注意力机制来建模词之间的关系。
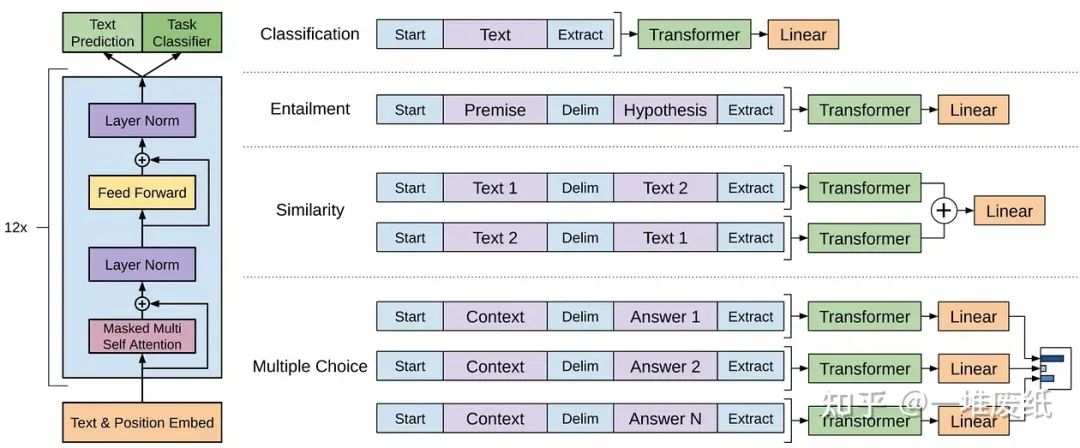
GPT-1模型的网络结构,图片来自原论文 https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
之后的GPT系列模型结构大体上都与GPT-1类似,主要区别在于更多参数(更多层,更多隐含层维度等等)。

GPT系列模型大小比较
2什么是Data-centric AI?
Data-centric AI是一种搭建AI系统的新理念,被@吴恩达老师大力倡导。我们这里引用下他给出的定义
Data-centric AI is the discipline of systematically engineering the data used to build an AI system.
— Andrew Ng
传统的搭建AI模型的方法主要是去迭代模型,数据相对固定。比如,我们通常会聚焦于几个基准数据集,然后设计各式各样的模型去提高预测准确率。这种方式我们称作以模型为中心(model-centric)。然而,model-centric没有考虑到实际应用中数据可能出现的各种问题,例如不准确的标签,数据重复和异常数据等。准确率高的模型只能确保很好地「拟合」了数据,并不一定意味着实际应用中会有很好的表现。
与model-centric不同,Data-centric更侧重于提高数据的质量和数量。也就是说Data-centric AI关注的是数据本身,而模型相对固定。采用Data-centric AI的方法在实际场景中会有更大的潜力,因为数据很大程度上决定了模型能力的上限。
需要注意的是,「Data-centric」与「Data-driven」(数据驱动),是两个根本上不同的概念。后者仅强调使用数据去指导AI系统的搭建,这仍是聚焦于开发模型而不是去改变数据。
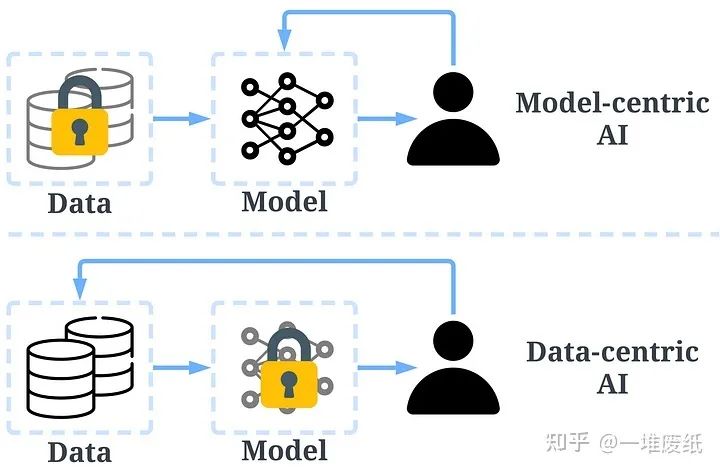
Data-centric AI和model-centric AI的区别,图片来源于https://arxiv.org/abs/2301.04819
Data-centric AI框架包括三个目标:
训练数据开发(training data development)旨在构建足够数量的高质量数据,以支持机器学习模型的训练。
推理数据开发(inference data development)旨在构建模型推理的数据,主要用于以下两个目的:
评估模型的某种能力,比如构建对抗攻击( Adversarial Attacks)数据以测试模型的鲁棒性
解锁模型的某种能力,比如提示工程(Prompt Engineering)
数据维护(data maintenance)旨在确保数据在动态环境中的质量和可靠性。在实际生产环境(production environment)中,我们并不是只训练一次模型,数据和模型是需要不断更新的。这个过程需要采取一定的措施去持续维护数据。
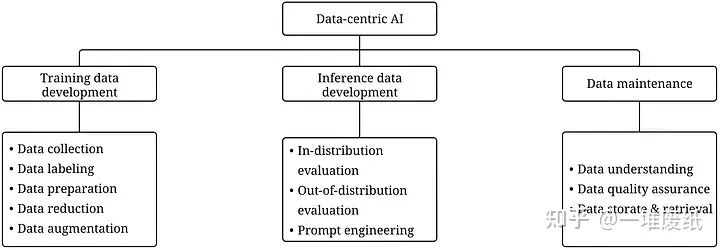
Data-centric AI框架第二层是目标,第三层是子目标,图片来源于 https://arxiv.org/abs/2303.10158
3 为什么Data-centric AI是GPT模型取得成功的重要原因?
数月前,Yann LeCun发文称ChatGPT在技术上并不是什么新鲜事物。的确如此,ChatGPT和GPT-4中使用的方法,比如Transformer、「从人类反馈中进行的强化学习」(Reinforcement Learning from Human Feedback,RLHF)等都不是什么新技术。即便如此,ChatGPT还是取得了以前的模型无法企及的惊人效果。那么,是什么推动了它的成功?

毋庸置疑,增加模型参数的数量对GPT模型的成功至关重要,但这只是其中的一个原因。通过详细阅读GPT-1、GPT-2、GPT-3、InstructGPT和ChatGPT/GPT-4论文中有关数据的描述,我们可以明显看出OpenAI的工程师们花了极大心血去提高数据的质量和数量。以下,我们用Data-centric AI框架从三个维度进行分析。
训练数据开发:从GPT-1到ChatGPT/GPT-4,通过更好的数据收集(data collection)、数据标注(data labeling)和数据准备(data preparation)策略,用于训练GPT模型的数据数量和质量都得到了显著提高。以下括号中标识了每个具体策略对应到Data-centric AI框架中的子目标。
GPT-1:训练使用了BooksCorpus数据集。该数据集包含4629.00 MB的原始文本,涵盖了各种类型的书籍,如冒险、奇幻和浪漫等。
用到的Data-centric AI策略:
无。
结果:
预训练之后,在下游任务微调可以提高性能。
GPT-2:训练使用了WebText数据集。这是OpenAI的一个内部数据集,通过从Reddit上抓取出站链接创建而成。
用到的Data-centric AI策略:
仅筛选并使用Reddit上至少获得3个karma及以上的链接(数据收集)
用Dragnet和Newspaper这两个工具去提取纯文本(数据收集)
用了一些启发式策略做了去重和数据清洗,具体策略论文没有提到(数据准备)
结果:
经过筛选后,获得了40 GB的文本(大概是GPT-1所用数据的8.6倍)。
GPT-2即便在没有微调的情况下也能取得很不错的效果。
GPT-3:训练主要使用了Common Crawl,一个很大但质量不算很好的数据集。
用到的Data-centric AI策略:
训练一个分类器来过滤掉低质量的文档。
这里比较有意思的是,OpenAI把WebText当作标准,基于每个文档与WebText之间的相似性来判断质量高低(数据收集)
使用Spark的MinHashLSH对文档进行模糊去重(数据准备)
把之前的WebText扩展下也加了进来,还加入了books corpora和Wikipedia数据(数据收集)
结果:
在对45TB的纯文本进行质量过滤后,获得了570GB的文本(仅选择了1.27%的数据,可见对质量把控的力度很大,过滤完后的文本大约是GPT-2的14.3倍)。
训练得到的模型比GPT-2更强了。
InstructGPT:在GPT-3之上用人类反馈去微调模型,使得模型与人类期望相符。
用到的Data-centric AI策略:
使用人类提供的答案来用有监督的方式微调模型。
OpenAI对标注人员的选择极为严苛,对标注者进行了考试,最后甚至会发问卷确保标注者有比较好的体验。
要是我的研究项目需要人工标注,能有人理我就不错了,更别谈考试和问卷(数据标注)
收集比较数据(人类对产生的答案根据好坏程度排序)来训练一个奖励模型,然后基于该奖励模型使用「从人类反馈中进行的强化学习」(Reinforcement Learning from Human Feedback,RLHF)来微调(数据标注)
结果:
InstructGPT产生的结果更加真实、有更少的偏见、更符合人类的预期。
ChatGPT/GPT-4:至此,产品走向了商业化,OpenAI不再「Open」,不再披露具体细节。已知的是ChatGPT/GPT-4在很大程度上遵循了以前GPT模型的设计,并且仍然使用RLHF来调整模型(可能使用更多、更高质量的数据/标签)。鉴于GPT-4的推理速度比ChatGPT慢很多,模型的参数数量大概率又变多了,那么也很有可能使用了一个更大的数据集。
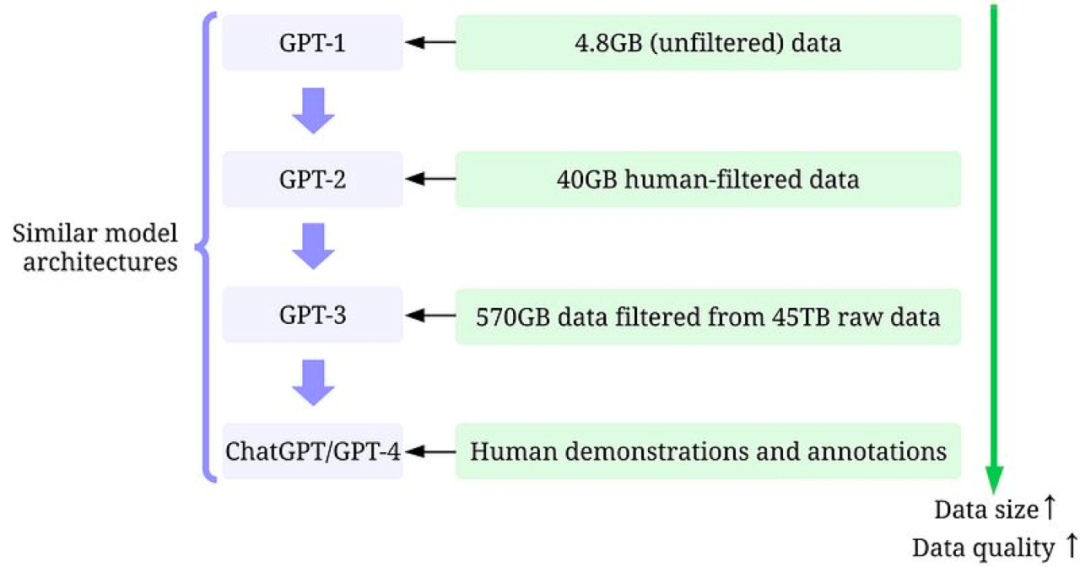
从GPT-1到ChatGPT/GPT-4,所用的训练数据大体经历了以下变化:小数据(小是对于OpenAI而言,对普通研究者来说也不小了)->大一点的高质量数据->更大一点的更高质量数据->高质量人类(指能通过考试的标注者)标注的高质量数据。模型设计并没有很显著的变化(除了参数更多以顺应更多的数据),这正符合了Data-centric AI的理念。从ChatGPT/GPT-4的成功,我们可以发现,高质量的标注数据是至关重要的。在AI的任何子领域几乎都是如此,即便是在很多传统上的无监督任务上,标注数据也能显著提高性能,例如弱监督异常检测。OpenAI对数据和标签质量的重视程度令人发指。正是这种执念造就了GPT模型的成功。这里顺便给大家推荐下朋友做的可视化文本标注工具Potato,非常好用!
推理数据开发:现在的ChatGPT/GPT-4模型已经足够强大,强大到我们只需要调整提示(推理数据)来达到各种目的,而模型则保持不变。例如,我们可以提供一段长文本,再加上特定的指令,比方说「summarize it」或者「TL;DR」,模型就能自动生成摘要。在这种新兴模式下,Data-centric AI变得更为重要,以后很多AI打工人可能再也不用训练模型了,只用做提示工程(prompt engineering)。

提示工程示例,图片来源于https://arxiv.org/abs/2303.10158
当然,提示工程是一项具有挑战性的任务,它很大程度上依赖于经验。这篇综述很好地总结了各种各样的方法,有兴趣的读者可以继续阅读。与此同时,即使是语义上相似的提示,输出也可能非常不同。在这种情况下,可能需要一些策略去降低输出的方差,比如Soft Prompt-Based Calibration。
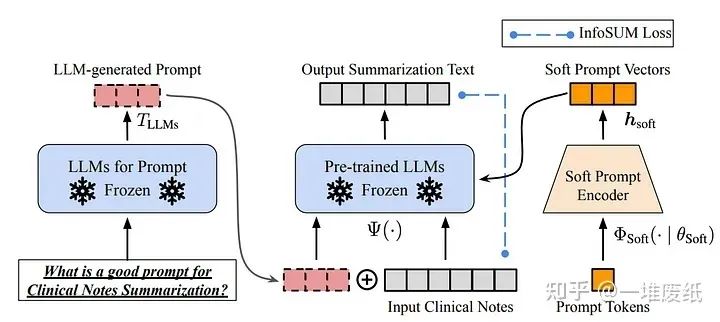
Soft prompt-based calibration,图片来源于https://arxiv.org/abs/2303.13035v1
大语言模型的推理数据开发研究仍处于早期阶段。我相信在不久的将来,很多其他任务中用到过的推理数据开发方法也会逐渐被迁移到大语言模型中,例如构建对抗攻击(Adversarial Attacks)数据以测试模型的鲁棒性。
数据维护:作为一款商业产品,ChatGPT/GPT-4一定不是仅仅训练一次就结束了,而是会被持续更新和维护。我们在外部没办法知道OpenAI数据维护具体是如何进行的。因此,我们只能推测。OpenAI可能采取了如下策略:
持续数据收集:当我们使用ChatGPT/GPT-4时,我们输入的提示和提供的反馈可以被OpenAI用来进一步提升他们的模型。在此过程中,模型开发者需要设计监测数据质量的指标和维护数据质量的策略,以收集更高质量的数据。
数据理解工具:开发各种工具来可视化和理解用户数据可以帮助更好地理解用户需求,并指导未来的改进方向。
高效数据处理:随着ChatGPT/GPT-4用户数量的迅速增长,高效的数据管理系统需要被开发,以帮助快速获取相关数据进行训练和测试。

ChatGPT/GPT-4 会收集用户反馈
4 从大语言模型的成功中我们能学到什么?
大语言模型的成功可以说是颠覆性的。展望未来,我做几个预测:
Data-centric AI变得更加重要。经过了多年的研究,模型设计已经相对比较成熟,特别是在Transformer出现之后(目前我们似乎还看不到Transformer的上限)。提高数据的数量和质量将成为未来提高AI系统能力的关键(或可能是唯一)途径。此外,当模型变得足够强大时,大多数人可能不需要再训练模型。相反,我们只需要设计适当的推理数据(提示工程)便能从模型中获取知识。因此,Data-centric AI的研究和开发将持续推动未来AI系统的进步。
大语言模型将为Data-centric AI提供更好的解决方案。许多繁琐的数据相关工作目前已经可以借助大语言模型更高效地完成了。例如,ChatGPT/GPT-4已经可以编写可以运行的代码来处理和清洗数据了。此外,大语言模型甚至可以用于创建训练数据。例如,最近的研究表明,使用大语言模型合成数据可以提高临床文本挖掘模型的性能。
数据和模型的界限将变得模糊。以往,数据和模型是两个分开的概念。但是,如今当模型足够强大后,模型成为了一种「数据」或者说是数据的「容器」。在需要的时候,我们可以设计适当的提示语,利用大语言模型合成我们想要的数据。这些合成的数据反过来又可以用来训练模型。这种方法的可行性在GPT-4上已经得到了一定程度的验证。在报告中,一种被称作rule-based reward models(RBRMs)的方法用GPT-4自己去判断数据是否安全,这些标注的数据反过来又被用来训练奖励模型来微调GPT-4。有种左右手互搏的感觉了。我不经在想,之后的模型会通过这种方式实现自我进化吗?细思极恐……
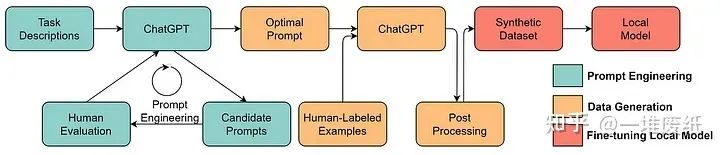
用ChatGPT来合成数据训练下游模型,图片来源于 https://arxiv.org/abs/2303.04360
回想起五年前,我还在纠结「如何才能提高文本分类的准确率」,多次失败的经历曾让我一度怀疑自然语言处理和AI没有半点关系。如今ChatGPT/GPT-4惊人的能力让我提前见证了历史!
未来AI的发展将走向何方?大语言模型的进展日新月异,经常看到一些研究自然语言处理的朋友们担心大模型的出现会不会让AI科研无路可走了。我认为完全不需要有这种担心。技术永远是不断进步的。新技术的出现不可避免会取代旧的技术(这是进步),但同时也会催生更多新的研究方向。比如,近年来深度学习的飞速发展并没有让传统机器学习的研究无路可走,相反,提供了更多的可供研究的方向。
同时,AI一个子领域的突破势必会带动其他子领域的蓬勃发展,这其中就有许多新的问题需要研究。比如,以ChatGPT/GPT-4为代表的大模型上的突破很可能会带动计算机视觉的进一步提升,也会启发很多AI驱动的应用场景,例如金融、医疗等等。无论技术如何发展,提高数据的质量和数量一定是提高AI性能的有效方法,Data-centric AI的理念将越来越重要。
那么大模型就一定是达成通用人工智能的方向吗?我持保留态度。纵观AI发展历程,各个AI子领域的发展往往是螺旋上升、相互带动的。这次大模型的成功是多个子领域的成功碰撞出的结果,例如模型设计(Transformer)、Data-centric AI(对数据质量的重视)、强化学习(RLHF)、机器学习系统(大规模集群训练)等等,缺一不可。在大模型时代,我们在AI各个子领域依然都大有可为。比如,我认为强化学习相比大模型可能有更高的上限,因为它能自我迭代,可能不久的将来我们将见证由强化学习引领的比ChatGPT更惊艳的成果。对强化学习感兴趣的读者可以关注下我之前的文章DouZero斗地主AI深度解析,以及RLCard工具包介绍。
在这个AI发展日新月异的时代,我们需要不断学习。我们对Data-centric AI这个领域进行了总结,希望能帮助大家快速高效地了解这个领域,相关链接见本文开头。鉴于Data-centric AI是一个很大的领域,我们的总结很难面面俱到。欢迎感兴趣的读者去我们的GitHub上指正、补充。
审核编辑 :李倩
-
人工智能
+关注
关注
1791文章
47208浏览量
238295 -
语言模型
+关注
关注
0文章
521浏览量
10268 -
GPT
+关注
关注
0文章
354浏览量
15347
原文标题:GPT 模型成功的背后用到了哪些以数据为中心的人工智能(Data-centric AI)技术?
文章出处:【微信号:AI智胜未来,微信公众号:AI智胜未来】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论