 CPU是怎么实现加速的?
CPU是怎么实现加速的?
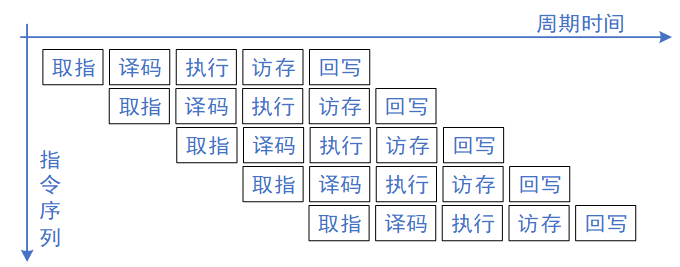
软件在CPU上执行,采用一定的流水线执行指令,通常有取指(Instruction Fetch)、译码(Instruction Decode)、执行(Execute)、访存(Memory)、写回(Write Back)这几步操作。如下图所示,为5个阶段的顺序执行的处理器指令流,即CPU执行指令按照流水线,有一定的先后顺序,单线程同一时刻只能计算出一个结果。

那么,我们再深入探讨一下CPU的体系结构,不外乎下图的几种:冯.诺依曼体系结构、哈佛体系结构、改进的哈佛体系结构,这几种结构有其各自的优势,应用于不同的产品中,也有各自的优缺点,其中X86最典型的冯.诺依曼结构,广泛应用于个人电脑、工作站、服务器等;而ARM是最典型的哈佛结构,广泛应用于单片机、ARM芯片等终端芯片,如手机、平板等,终端设备等。关于具体的细分,详见下方思维导图。
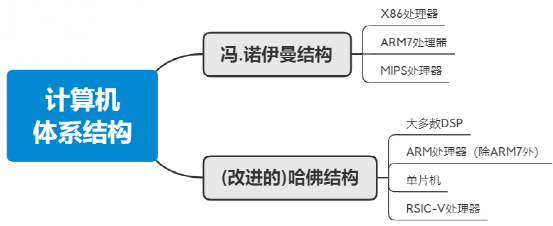
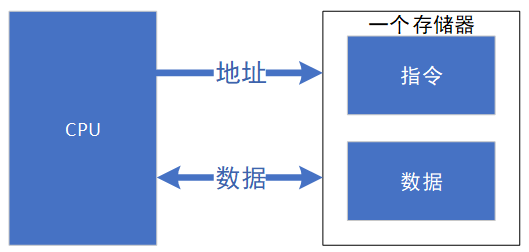
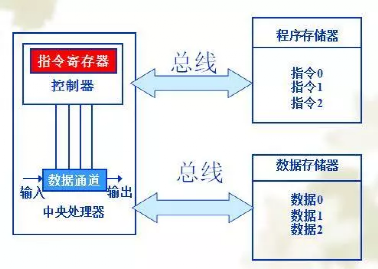
冯.诺依曼结构(von Eeumann Architecture),也称普林斯顿结构,如下图所示,是一种将程序指令和数据合并在一起的存储器结构。该结构中指令和数据共用一条总线,通过分时复用的方式进行读写操作,结构相对简单,总线面积较小,但缺点是效率低,无法同时取指令和数据,成为了执行的瓶颈。
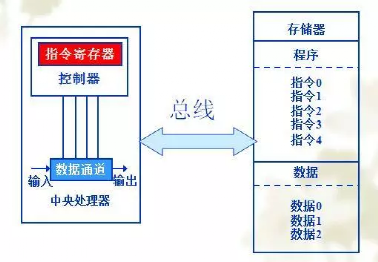
为了解决冯.诺依曼结构无法并行取指令和数据,提高计算的效率,在此基础上提出了哈佛结构(Harvard Architecture),这是一种将程序指令和数据分开的存储器结构,如今下图所示。该结构由于程序的指令和数据存储在两个独立的存储器,各自有独立的访问总线,因此提供了更大的存储器带宽,减轻了程序运行时访问内存的瓶颈。但相应的也需要独立的存储器,以及更大的总线面积,其中ARM就是典型的哈佛结构。
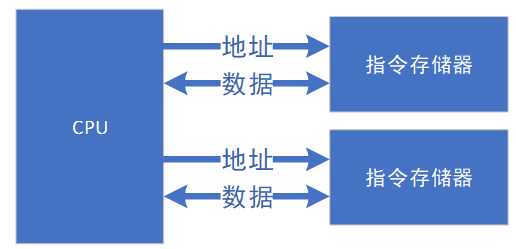
同样采用流水线,相对于冯.诺依曼结构,哈佛结构的指令效率更高。哈佛结构在当前指令译码的时候,可以进行下一条指令的取指,然后在执行下一条指令的同时,又开始了第三条指令的取指。这一过程,通过指令预取,加快了原先5个步骤的流水线结构,提高了流水线的并行度。
实际上计算机体系结构发展到现在,冯.诺伊曼结构,和哈佛结构的界限已经没有那么清晰。比如改进型的哈佛结构,指令和数据还是一起存储在主存中,但CPU有额外的指令Cache和数据Cache(如下图所示),在主存带宽足够允许的前提下,使得CPU可以同时去取指令和数据Cache,所以可以认为结构上对外是冯.诺伊曼结构,对内是哈佛结构,这就是改进型的哈佛结构。
由于本章仅在高层次上,对CPU架构设计带来的加速进行基础的描述,这块就不再深入。那么,我们继续探讨,如何可以让CPU流水线计算地更快。
1)采用更先进的工艺
从28nm到5nm/3nm,更先进的工艺使得允许我们可以在更高的频率下进行工作,当然也意味着更高的流片成本。典型的以28nm为例,A53可以跑到1.5GHz,而在16nm工艺下,A53可以跑到2.3GHz的主频(以上数据仅供参考,跟具体优化有关)。
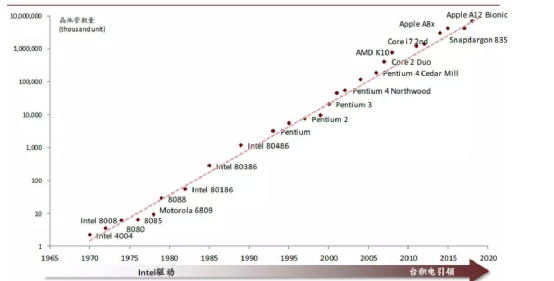
但摩尔定律的终结,意味着一味地通过工艺的升级来提高主频,变得越来越困难,除了单纯的提升工艺,增加核数量,我们还得从微架构上探索,如何跑的更快。
2)超级流水线处理器
由于时钟频率受流水线中计算耗时最大的的,即我们的主频需要满足各阶段的setup/hold time,如果将每一步计算拆分为更细的颗粒度,那么我们更容易满足setup/hold time,因而可以跑在更高的主频下——这就是超级流水线处理器/深流水线。
如下图所谓,为细分后的超级流水线示意图。

3)标量流水线处理器
用更细的计算颗粒,我们可以运行在更高的主频,这是提高了流水的速率。
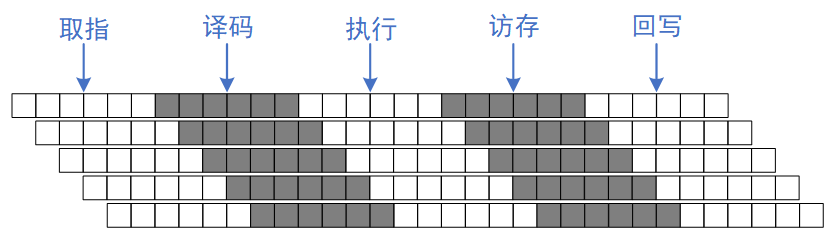
换个思路,大力出奇迹:如果我们拥有多条河流,那我们可以成倍的提高流水的效率,这就是标量流水线处理器,如下图所示:
在上图中,每条流水线执行仍然需要5个周期,但上下两个流水线可以重叠执行。图中用9个周期,完成了5条指令,但即当流水线满载时,每个周期都可以完成一条指令,相比于单流水线,提高了5倍的效率。当然我们拥有了5条河流来提高速率,也是付出了面积的代价,即FPGA中常用的面积换速度的思维。
4)超标量流水线处理器
结合超级流水线,以及标量流水线的特性,也自然有了超级标量流水线结构的处理器,其流水结构如下图所示:
超标量流水线处理器指令流
即采用了多条流水线的结构,增加了并行计算性能;同时通过流水线每一阶段的颗粒度,提高了运行的主频。当然,相对于两个种优化的结构,超标量流水线结构也是以更大的面积为代价。目前市场上几乎所有处理器,都是超标量流水处理器结构。
5)采用多核CPU结构
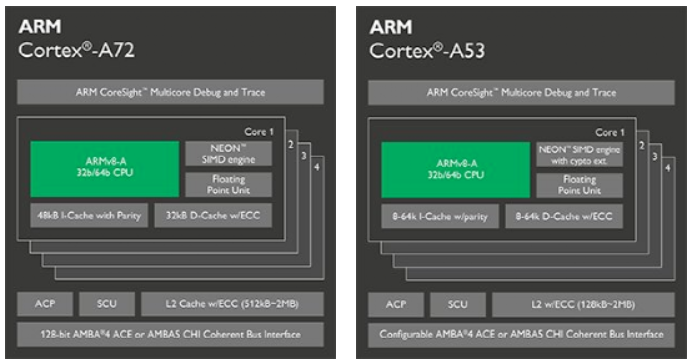
当在确定的工艺,以及一定的超标量流水线结构的处理器下,单核CPU的性能很难再实现质的飞跃,那么多核处理器的结构,再次通过面积换速度,成倍的提升了CPU的硬件性能。典型的以下图为例,为***处理器中,4核A72 + 4核A53的大小核结构。多核处理器,在进行SOC设计时,给架构师提出了更高的挑战;同时在软件应用时,也对多核并行处理提出了更高的要求,如下图所示,为AR72/A53的多核结构。
-
ARM
+关注
关注
134文章
9098浏览量
367720 -
存储器
+关注
关注
38文章
7493浏览量
163881 -
cpu
+关注
关注
68文章
10870浏览量
211911 -
流水线
+关注
关注
0文章
120浏览量
25755 -
指令
+关注
关注
1文章
607浏览量
35733
原文标题:CPU是怎么实现加速的?
文章出处:【微信号:处芯积律,微信公众号:处芯积律】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【FPGA干货分享六】基于FPGA协处理器的算法加速的实现
涡轮加速升压(Turbo-boost)充电器可为CPU涡轮加速模式提供支持

涡轮加速升压 (Turbo-boost) 充电器可为 CPU 涡轮加速模式提供支持
Javascript如何实现GPU加速?
使用FPGA实现CPU设计的毕业论文总结
如何使用FPGA实现八位RISC CPU的设计
为什么FPGA主频比CPU慢,但却可以用来帮CPU做加速
Intel Sapphire Rapids CPU,吹响反攻DPU的号角

音视频解码器硬件加速:实现更流畅的播放效果






 工商网监
工商网监
评论