 CV迎来GPT-3时刻:Meta开源“万物可分割AI”模型
CV迎来GPT-3时刻:Meta开源“万物可分割AI”模型

通过单击、交互式点击即可分割图像或视频
英伟达 AI 科学家 Jim Fan 在 Twitter 上惊呼,Meta 发布的 SAM 让计算机视觉(CV)迎来 GPT-3 时刻。更不可思议的是,模型和数据(1100万张图像,10亿个掩码)都已经基于 Apache 2.0 许可开源。
今日,Meta 发布首个可“任意图像分割”的基础模型 Segment-Anything Model(SAM)和最大规模的“任意分割 10 亿掩码数据集「Segment Anything 1-Billion mask dataset (SA-1B)」,将自然语言领域的 prompt 范式引入了 CV 领域,进而为 CV 基础模型提供更广泛的支持与深度研究。
SAM Demo:https://segment-anything.com/
开源地址:https://github.com/facebookresearch/segment-anything
论文地址:https://ai.facebook.com/research/publications/segment-anything/
SA-1B数据集:https://ai.facebook.com/datasets/segment-anything/
1. 图片、视频皆可分割
分割,作为 CV 领域的核心任务,被广泛应用在科学图像到编辑照片等应用程序员中,但是,为特定任务创建准确的分割模型通常需要技术专家进行高度专业化的工作,并且需要访问 AI 培训基础设施和大量精心注释领域内方面的数据能力。
SAM 通过 prompt 工程能力即可分割任意想分割的图像。

截图自SAM论文
SAM 已经学会了物体的一般概念,并且可以为任何图像或视频中的任何对象生成掩模,甚至包括在训练期间没有遇到过的对象和图像类型。
SAM 足够通用,可以涵盖广泛的用例,并且可以直接在新的图像“领域”上使用——无论是水下照片还是细胞显微镜——都不需要额外的训练(这种能力通常称为零样本迁移)。
之前,为了解决分割问题,一般会采用两种分类方法:
第一种是交互式分割,可以对任何类别的对象进行分割,但需要人员通过迭代地细化掩模来指导该方法。
第二种是自动分割,允许预先定义特定对象类别(例如猫或椅子)的分割,但需要大量手动注释的对象进行训练(例如数千甚至数万个已经过分割处理的猫示例),以及计算资源和技术专业知识来训练分割模型。这两种方法都没有提供通用、完全自动化的分割方法。
SAM 集合了上面两种方法,成为一个单一模型,可以轻松执行交互式分割和自动分割。
1、SAM 允许用户通过单击、交互式点击或边界框提示来分割对象;
2、当面临关于正在分割的对象歧义时,SAM可以输出多个有效掩码,这是解决现实世界中分割问题所必需的重要能力;
3、SAM可以自动查找并遮罩图像中的所有对象;
4、在预计算图像嵌入后,SAM 可以为任何提示生成实时分割掩码,从而允许与模型进行实时交互。
SAM 在超过 10亿个掩码组成的多样化高质量数据集上进行训练(作为该项目的一部分),从而使其能够推广到训练期间未观察到的新类型对象和图像之外。这种推广能力意味着,总体来说,从业者将不再需要收集自己的分割数据并微调用于他们用例场景中的模型。
2. SAM 背后的技术
Meta AI 团队在官博中直言到,SAM 的研发灵感来自于自然语言和计算机视觉中的 “prompt 工程”,只需对新数据集和任务执行零样本学习和少样本学习即可使其能够基于任何提示返回有效的分割掩模。其中,提示可以是前景/背景点、粗略框或掩模、自由文本或者一般情况下指示图像中需要进行分割的任何信息。有效掩模的要求意味着即使提示不明确并且可能涉及多个对象(例如,在衬衫上的一个点既可能表示衬衫也可能表示穿着它的人),输出应该是其中一个对象合理的掩模。这项任务用于预训练模型,并通过提示解决通用下游分割任务。
研发人员观察到预训练任务和交互式数据收集对模型设计施加了特定的限制。特别是,为了使标注员能够在实时交互中高效地进行标注,模型需要在 Web 浏览器上以实时方式运行于 CPU 上。虽然运行时间约束意味着质量和运行时间之间存在权衡,但他们发现,简单的设计在实践中产生良好的结果。
在模型设计中,图像编码器为图像生成一次性嵌入,而轻量级编码器实时将任何提示转换为嵌入向量。然后,在轻量级解码器中将这两个信息源组合起来以预测分割掩模。计算出图像嵌入后,SAM 可以在 Web 浏览器中仅用 50 毫秒的时间根据任何提示生成一个段落。
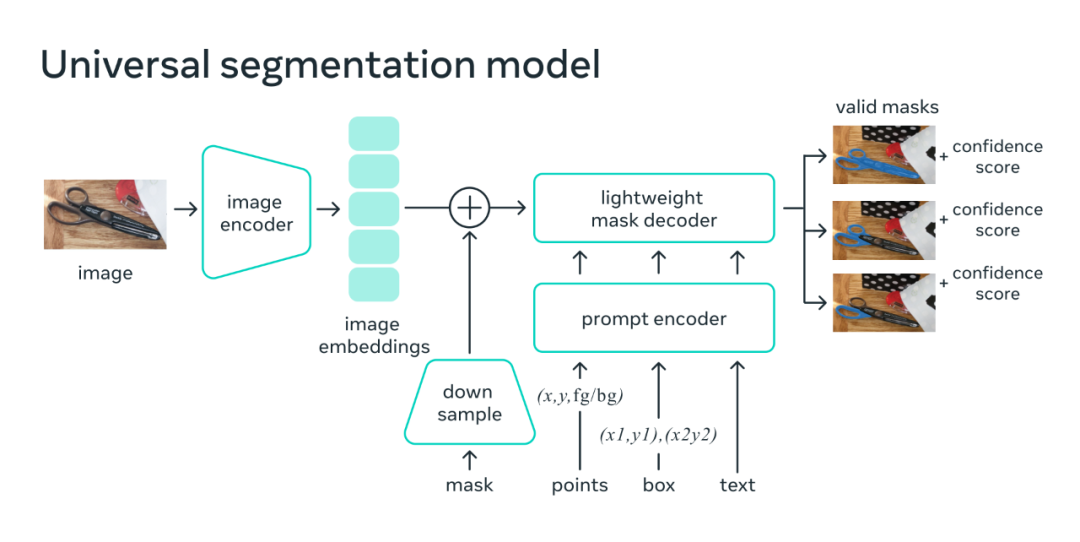
在 Web 浏览器中,SAM 高效地将图像特征和一组提示嵌入映射到生成分割掩模。
3. 超 1100 万张照片,1B+掩码
数据集来自 SAM 收集,而在训练起初,并无任何数据,而今天发布的数据集已是迄今为止最大的数据了。注释员使用 SAM 交互式地注释图像,然后新注释的数据反过来用于更新 SAM,彼此相互作用,重复执行此循环来改善模型和数据集。
使用 SAM 收集新分割掩码比以往任何时候都更快,仅需约 14 秒即可交互式地注释掩码。相对于标记边界框所需时间约 7 秒钟(使用最快速度标记接口),每个掩码标记流程只慢 2 倍左右。与之前大规模分割数据收集努力相比,该模型比 COCO 完全手动基于多边形遮罩注释快 6.5 倍,比先前最大的数据注释工作快了 2 倍,并且是基于模型协助完成任务 。
尽管如此,交互式的标记掩码依然无法扩展创建 10 亿个掩码数据库,于是便有了用于创建 SA-1B 数据库的“引擎”。该引擎有三个“档位”。
在第一档中,模型协助注释员,相互作用;
第二档是完全自动化的注释与辅助注释相结合,有助于增加收集到的掩码的多样性;
数据引擎的最后一个档位是完全自动遮罩创建,进而使数据库可以扩展。
最终,数据集在超过 1100 万张经过许可和隐私保护的图像上收集到了超过 11 亿个分割掩模。SA-1B 比任何现有的分割数据集多 400 倍,经人类评估验证,这些掩模具有高质量和多样性,在某些情况下甚至可以与以前规模小得多、完全手动注释的数据集中的掩模相媲美。
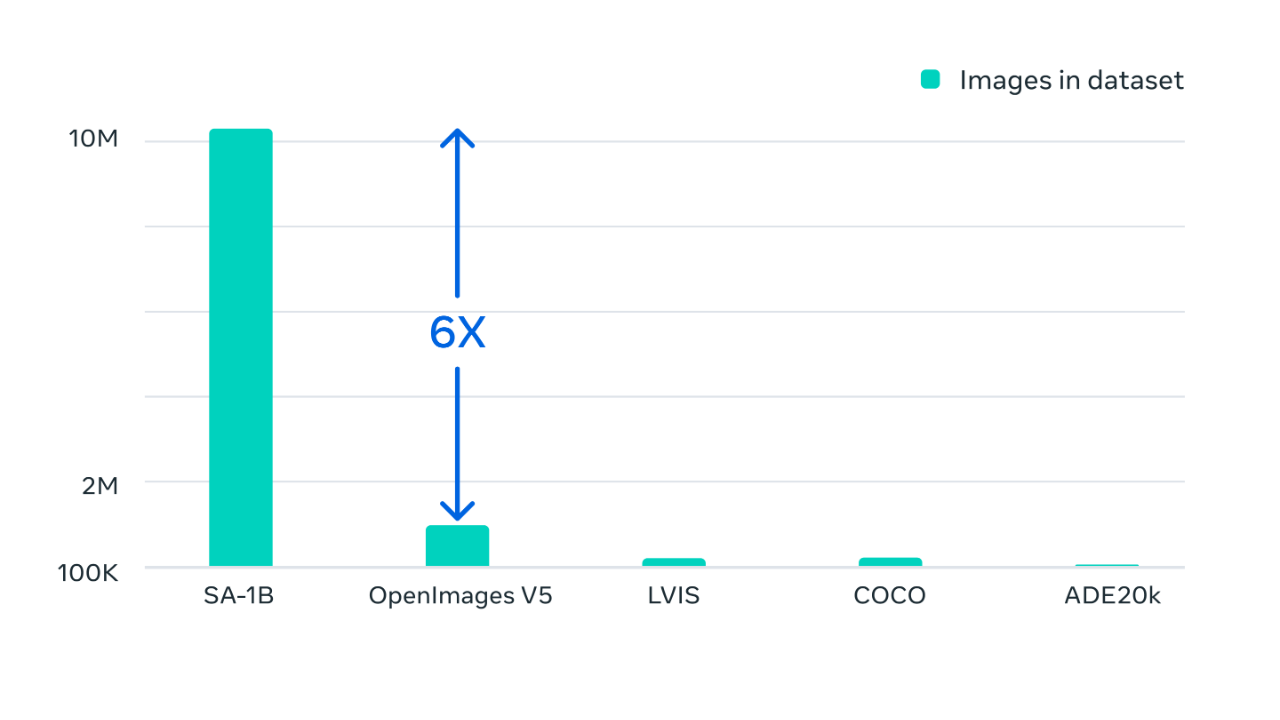
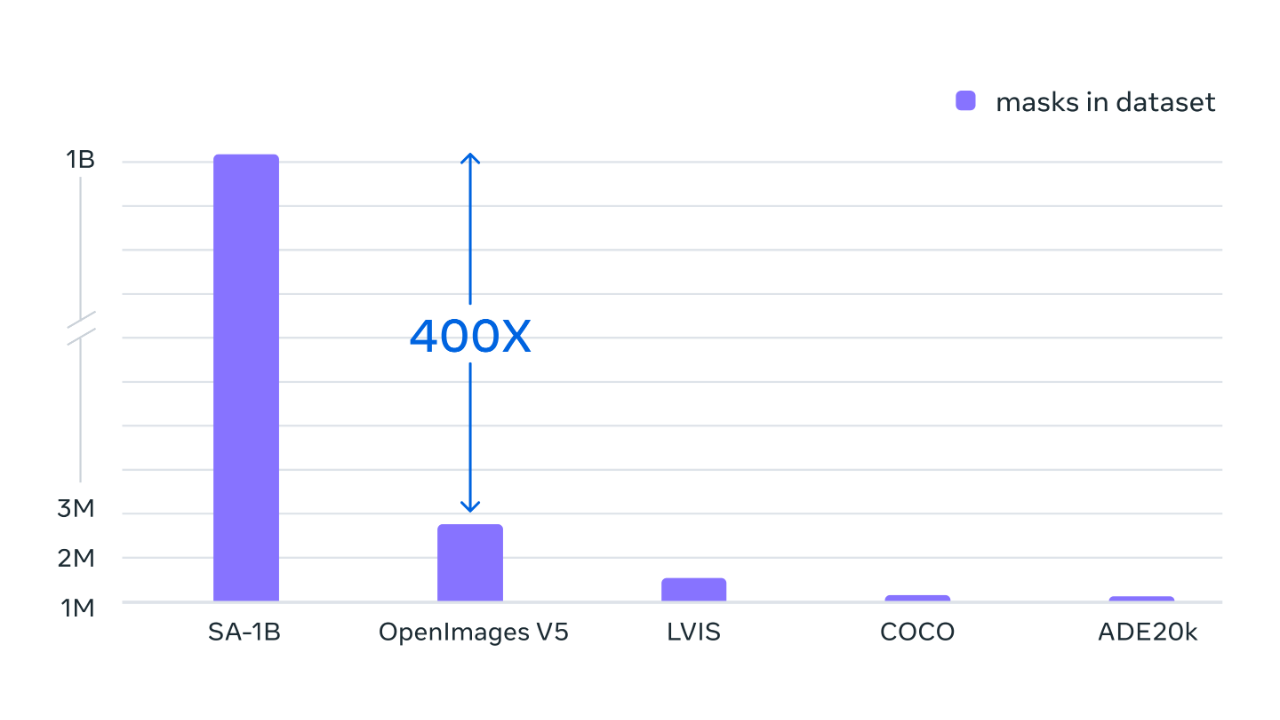
Segment Anything 是通过使用数据引擎收集数百万张图像和掩模进行训练,从而得到一个超 10 亿个分割掩模的数据集,这比以往任何分割数据集都大400倍。
将来,SAM 可能被用于任何需要在图像中找到和分割任何对象的领域应用程序。
对于 AI 研究社区或其他人来说,SAM 可能更普遍理解世界、例如理解网页视觉和文本内容等更大型 AI 系统中组件;
在 AR/VR 领域,SAM 可以根据用户注视选择一个对象,然后将其“提升”到 3D;
对于内容创作者来说,SAM 可以改进诸如提取碎片或视频编辑等创意应用程序;
SAM 也可用来辅助科学领域研究,如地球上甚至空间自然现象, 例如通过定位要研究并跟踪视频中的动物或物体。


最后,SAM 团队表示,通过分享他们的研究和数据集,来进一步加速分割更常见的图像和视频。可提示式分割模型可以作为较大系统中的组件执行分割任务。未来,通过组合系统可扩展单个模型使用,通过提示工程等技术实现可组合系统设计,进而使得比专门针对固定任务集训练的系统能够得更广泛的领域应用。
审核编辑 :李倩
-
AI
+关注
关注
87文章
32012浏览量
270869 -
开源
+关注
关注
3文章
3442浏览量
42829 -
CV
+关注
关注
0文章
53浏览量
16920 -
计算机视觉
+关注
关注
8文章
1701浏览量
46182
原文标题:CV 迎来 GPT-3 时刻:Meta 开源“万物可分割 AI ”模型
文章出处:【微信号:软件质量报道,微信公众号:软件质量报道】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文解析人工智能中GPT-3 到底有多厉害?
技术与市场:AI大模型的“Linux时刻”降临
线下活动 | 开源工作坊第2期——开源与万物互联
史上最大AI模型GPT-3你要开始收费了 接下去可能用不起它了

微软获得AI神器 GPT-3 独家授权,引来马斯克等业内人士怒怼
GPT-3引发公众的遐想 能根据文字产生图片的AI!
史上最大AI模型GPT-3强势霸榜Github
GPT系列的“高仿” 最大可达GPT-3大小 自主训练
谷歌开发出超过一万亿参数的语言模型,秒杀GPT-3

Eleuther AI:已经开源了复现版GPT-3的模型参数
第一篇综述!分割一切模型(SAM)的全面调研







 工商网监
工商网监
评论