 清华&美团提出稀疏Pairwise损失函数!ReID任务超已有损失函数!
清华&美团提出稀疏Pairwise损失函数!ReID任务超已有损失函数!

ReID任务的目的是从海量图像中检索出与给定query相同ID的实例。
Pairwise损失函数在ReID 任务中发挥着关键作用。现有方法都是基于密集采样机制,即将每个实例都作为锚点(anchor)采样其正样本和负样本构成三元组。这种机制不可避免地会引入一些几乎没有视觉相似性的正对,从而影响训练效果。为了解决这个问题,我们提出了一种新颖的损失范式,称为稀疏Pairwise (SP) 损失,在ReID任务中针对mini-batch的每一类筛选出少数合适的样本对来构造损失函数(如图1所示)。基于所提出的损失框架,我们进一步提出了一种自适应正挖掘策略,可以动态地适应不同类别内部的变化。大量实验表明,SP 损失及其自适应变体AdaSP 损失在多个ReID数据集上均优于其他成对损失方法,并取得了state-of-the-art性能。
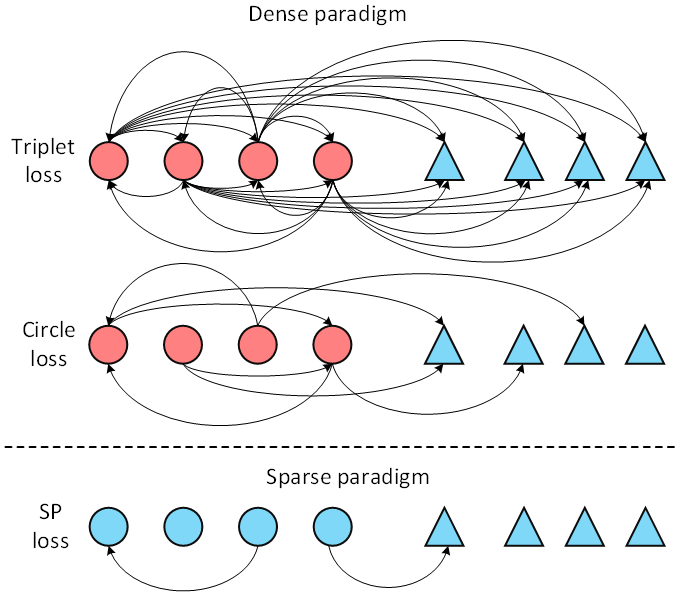
图1. Sparse pairwise损失与Dense pairwise损失之间的差异

Adaptive Sparse Pairwise Loss for Object Re-Identification
论文地址:https://arxiv.org/abs/2303.18247
Github地址(已开源):
https://github.com/Astaxanthin/AdaSP
研究动机:
ReID任务中的由于光照变化、视角改变和遮挡等原因会造成同一类中不同实例的视觉相似度很低(如图2所示),因此由视觉相似度很低的实例(我们称之为harmful positive pair)构成的正样本对会对特征表示的学习过程带来不利的影响,从而使训练收敛至局部极小点。现有的方法都是以每个样本作为锚(anchor)密集采样正样本对来构造度量损失函数,不可避免的会引入大量坏对影响训练结果。基于此,我们提出了稀疏Pairwise损失函数以降低对坏对的采样概率,从而减轻坏对在训练过程的不利影响。
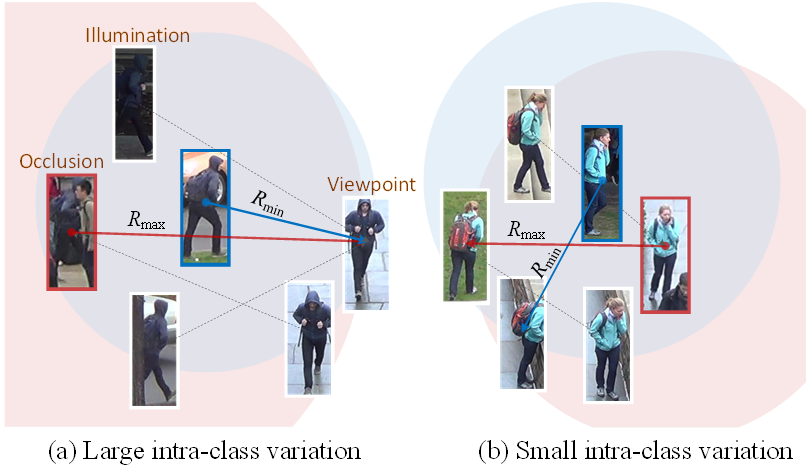
图2. 行人ReID数据集上不同级别的类内差异
方法介绍:我们提出的稀疏Pairwise损失函数(命名为SP loss)针对每一类仅采样一个正样本对和一个负样本对。其中负样本对为该类别与其他所有类别间最难的负样本对,而正样本对为所有样本的hard positive pair集合中的最不难positive pair(least-hard mining):
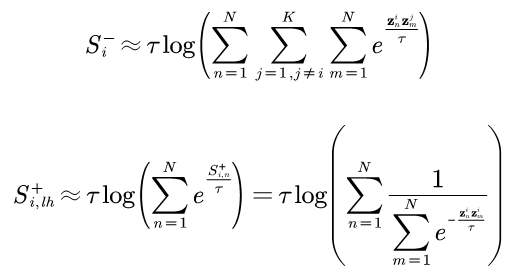
从几何角度看,以最难positive pair的距离作为半径的超球面是能够覆盖所有类内样本的最大球,而以hard positive pair集合中最不难positive pair的距离作为半径的超球面是能够副高所有类内样本的最小球,如图3所示。利用最小球能够有效的避免过于难的harmful positive pair对于训练过程的影响,我们从理论上证明了针对一个mini-batch,我们的方法采样得到的正样本对中harmful positive pair的期望占比小于Triplet-BH和Circle等密集采样方法。
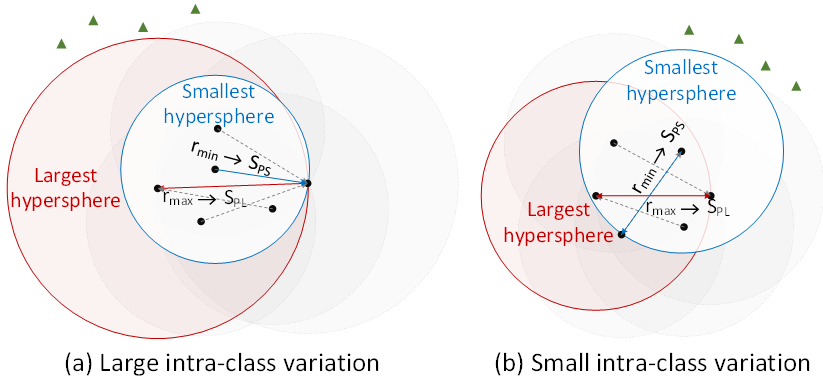
图3. 不同级别类内差异差异下的最大和最小覆盖球。
为了适应不同类别可能具有不同的类内差异,我们在SP loss的基础上增加了自适应策略构成AdaSP loss:
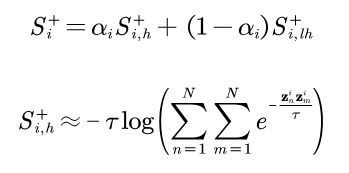

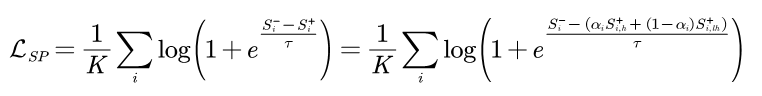
该loss通过动态调整构造loss所用到的正样本对相似度以适应不同的类内差异。
实验结果:
我们在多个行人ReID数据集(包括MSMT17,Market1501,DukeMTMC,CUHK03)和车辆ReID数据集(包括VeRi-776,VehicleID,VERIWild)上验证了AdaSP loss的有效性。实验结果显示AdaSP loss在单独使用时超过Triplet-BH,Circle,MS,Supcon,EP等已有度量损失函数,如表1所示;AdaSP loss在不同骨干网络(包括ResNet-50/101/152,ResNet-IBN,MGN,ViT,DeiT)上的ReID性能均优于Triplet-BH;此外,AdaSP loss结合分类损失函数在ReID任务上达到了State-of-the-art的性能。
表1. 在不同数据集上不同度量损失函数的性能比较
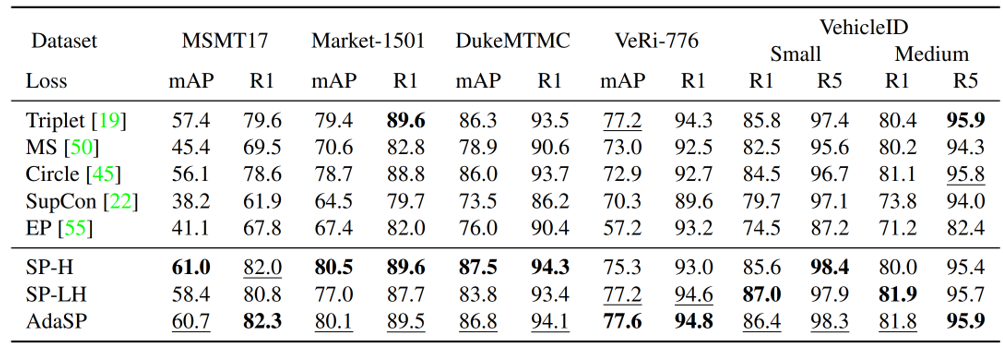
具体细节可以参考原文。
审核编辑 :李倩
-
函数
+关注
关注
3文章
4422浏览量
67876 -
数据集
+关注
关注
4文章
1240浏览量
26264 -
REID
+关注
关注
1文章
18浏览量
11170
原文标题:CVPR 2023 | 清华&美团提出稀疏Pairwise损失函数!ReID任务超已有损失函数!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
对象检测边界框损失函数–从IOU到ProbIOU介绍
keras常用的损失函数Losses与评价函数Metrics介绍
神经网络中的损失函数层和Optimizers图文解读
机器学习经典损失函数比较
机器学习实用指南:训练和损失函数
三种常见的损失函数和两种常用的激活函数介绍和可视化
深度学习的19种损失函数你了解吗?带你详细了解
计算机视觉的损失函数是什么?
损失函数的简要介绍
机器学习和深度学习中分类与回归常用的几种损失函数
表示学习中7大损失函数的发展历程及设计思路
详细分析14种可用于时间序列预测的损失函数
语义分割25种损失函数综述和展望




评论