 看看使用芯片验证随机带来的六宗罪
看看使用芯片验证随机带来的六宗罪
以前看到不少验证技术书籍都在说验证环境中随机怎么怎么好,然后为了随机,UVM,SV 提供了什么什么支持。
但是最近的一些工作小编发现在验证中采用随机存在很多缺点。下面小编带大家看看使用随机带来的六宗罪。
第一宗罪:难以debug
出现fail的test,当debug完,对设计和验证环境做了改动,可能无法复现fail的场景。
如何确保发现的testbench的问题,或者RTL的问题有真的修掉?一般的做法是用同样的seed,然后跑一遍之前的fail的test。但是有很多时候,由于环境的文件,约束等改变,再用同样的seed 跑fail 的test 和之前的行为不一致,从而错误的认为问题已经修掉。
第二宗罪:难以覆盖到特定场景
有些场景通过随机撞到的概率非常低。
如下图所示,C=A &&B,在下图场景中想通过 随机到 (A==1)&&(B==1)的 场景,非常难。
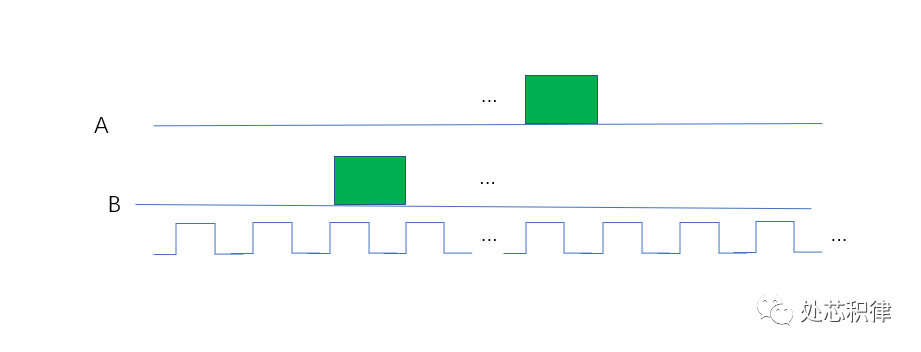
第三宗罪:验证时间不确定
回归结果不可靠。一次通过率100%,不代表次次回归100%。
一次回归可能100%,第二次回归又变成90%。连续10次回归100%,第十一次回归又出现fail的test。
第四宗罪:重复测试用例很多
浪费太多license 和服务器资源。
因为单次regression不能保证没有问题,所以要周周跑,月月跑,一直跑到tapout,这浪费了很多license和服务器资源。特别是有些test 打到的场景重复,做一些无效验证,给公司资源造成极大浪费。
第五宗罪:覆盖率收集耗费资源
coverage 收敛比较耗时间和资源。
由于随机约束造成不同场景出现的概率不一样,通过随机测试将代码覆盖率和功能覆盖率补全需要经过大量的回归测试。coverage的收敛速度没有直接测试来得快。
下面是一个案例,在跑完一版regression后,功能覆盖率是80.49%。
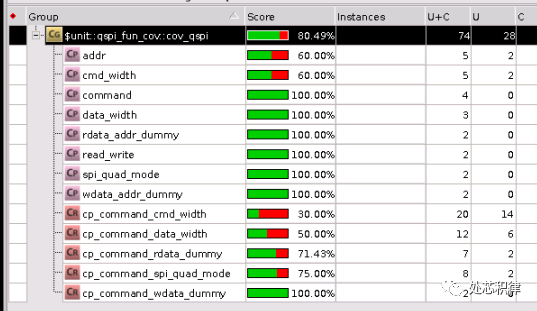
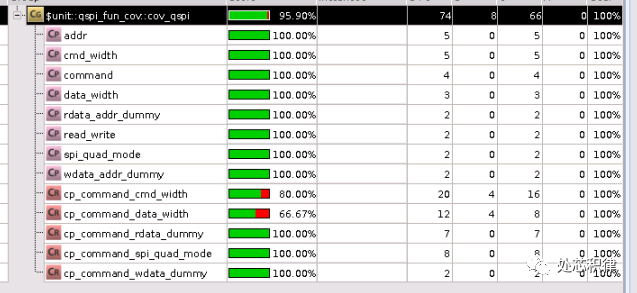
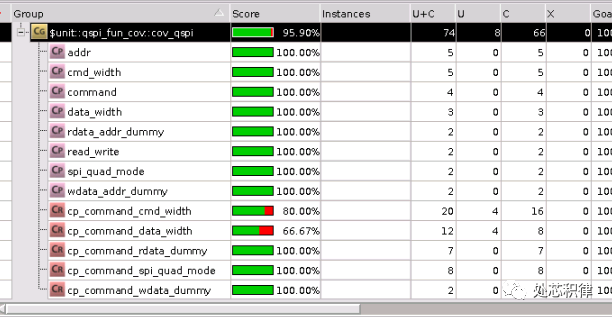
我们想将该功能覆盖率补全,采用直接测试用例,我们调用了5次测试,可以将覆盖率打到95.90% ,剩下的部分可以waive掉。
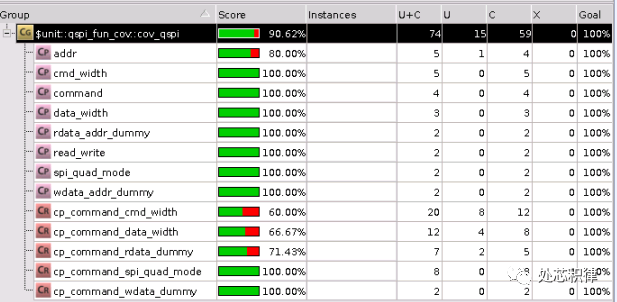
当我们采用随机测试,调用了5次随机测试,覆盖率为90.62%。
当我们采用随机测试,调用了10次随机测试,覆盖率为93.97%。
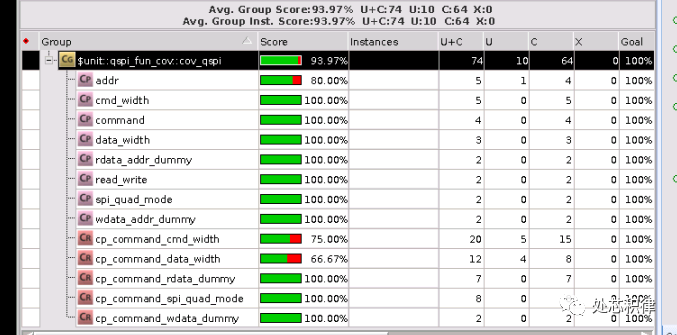
当我们采用随机测试,调用了20次随机测试,覆盖率为95.90%,达到了和直接测试同样的效果。
第六宗罪:场景打不全
随机验证打不全所有场景
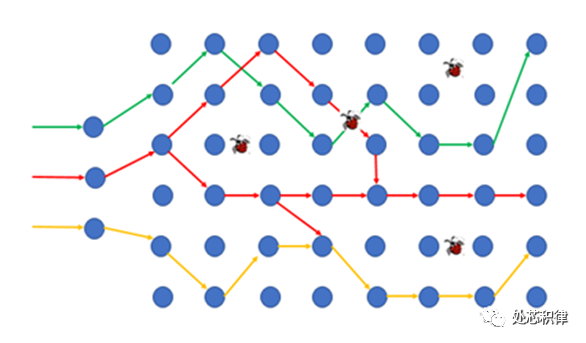
如上图所示,随机的行为很难将所有的测试路径都打到。
随机有没有好处呢?当然有,比如
探索更多的场景:随机验证可以探索更多的测试场景,覆盖更多的状态空间。这可以帮助发现设计中的潜在问题和漏洞,从而提高验证的质量。
发现意外错误:随机测试可以揭示一些设计者未曾考虑的异常情况,以及在正常测试中可能被忽略的边缘情况。这有助于找到并修复一些潜在的设计错误。
减少人为偏见:手动创建测试用例可能受到验证工程师的认知偏见和经验限制的影响。随机验证方法可以降低这种偏见对验证结果的影响,从而提高验证的可靠性。
减少人工编写测试用例的时间和精力:随机验证方法可以自动生成大量测试用例,从而减少人工编写测试用例的时间和精力。这有助于缩短验证周期,提高验证效率。
更好地应对复杂性:随着芯片设计变得越来越复杂,人工创建足够多的测试用例以覆盖所有可能的场景变得越来越困难。随机验证方法可以在面对复杂设计时自动生成更多的测试用例,从而更好地应对这种复杂性。
虽然使用随机验证存在很多问题,但它在许多情况下仍然是一种非常有效的验证方法。为了克服这些缺点,可以将随机验证与其他验证方法(如指导性验证、形式验证等)相结合,以实现更全面、有效的芯片验证。
审核编辑:刘清
-
RTL
+关注
关注
1文章
385浏览量
60013 -
UVM
+关注
关注
0文章
182浏览量
19240
原文标题:芯片验证随机(random)的六宗罪
文章出处:【微信号:处芯积律,微信公众号:处芯积律】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
关于功能验证、时序验证、形式验证、时序建模的论文
【云智易试用体验】开箱与初评六宗罪
怎么设计基于USB和FPGA的随机数发生器验证平台?
设计验证中的随机约束
选购低价笔记本:不得不说的五宗罪
基于OVM验证平台的IP芯片验证
基于System Verilog的可重用验证平台设计及验证结果分析






 工商网监
工商网监
评论