 港中大IDEA开源首个大规模全场景人体数据集Human-Art
港中大IDEA开源首个大规模全场景人体数据集Human-Art
编者按:
自古以来,人类形象已被广泛记录在绘画、雕塑等形式多样的艺术作品中,但目前大多数以人为中心的计算机视觉任务,都仅仅关注了现实世界中的真实照片,而忽略了人在虚拟场景下的表征。
针对于此,IDEA 研究院的 CVPR 2023 入选论文之一“Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes”,提出了首个同时包含现实和虚拟场景的大规模全场景人体数据集 Human-Art,现已正式开源。
本期《IDEA有研知》为你详细介绍Human-Art 数据集及下游任务表现。另外,本文作者在博士阶段首篇投稿论文即中CVPR,文末“科研有门道”环节将带你一同听听她的科研心得~
话不多说
先来看看 Human-Art 辅助训练的模型效果
天马行空的儿童简笔画,大人未必数得清
用Human-Art训练的模型能轻松辨认计算
创作中国传统皮影画,已有模型束手无策?
用Human-Art训练一下,一键即可生成
左:原始Stable Diffusion模型生成图
右:使用包含Human-Art数据微调后的模型生成图
上图给定文本:
“一张描述了三个人坐在中国亭子的皮影戏图片”
上图给定文本:
“一张描述了三个女人走路的色彩丰富的皮影戏图片”
Human-Art 数据集现已正式开源
涵盖5个真实场景和15个虚拟场景
代码地址:
https://github.com/IDEA-Research/HumanArt
项目主页:
https://idea-research.github.io/HumanArt/
5万张图像,超12.3万个人物形象,
Human-Art为CV领域拓展虚拟场景
在照相机发明前,人类形象已在各类艺术创作载体上被记录和呈现。从古代的壁画到纸上的水墨画、油画,以及姿态丰富的人体雕塑,再到如今AIGC创作出各种各样的虚拟人物,大量的艺术作品同样提供了与人体相关的、丰富多样的视觉数据。
然而,现有的计算机视觉任务、训练的数据集等大多只关注到了真实世界的照片,这导致相关模型在更丰富的场景下,常常出现性能下降甚至完全失效的问题。即使是SOTA性能的人体检测模型,面对虚拟场景的人体数据时也往往令人大失所望,检测准确率不足20%。
已有工作关注到了虚拟场景数据集稀缺的问题,如ClassArch、Sketch2Pose、People-Art等数据集纳入了人造场景下的数据,但都存在数据规模小(最多的ClassArch也仅收集了1513张照片),仅能支持单一场景的人体检测任务等不足。
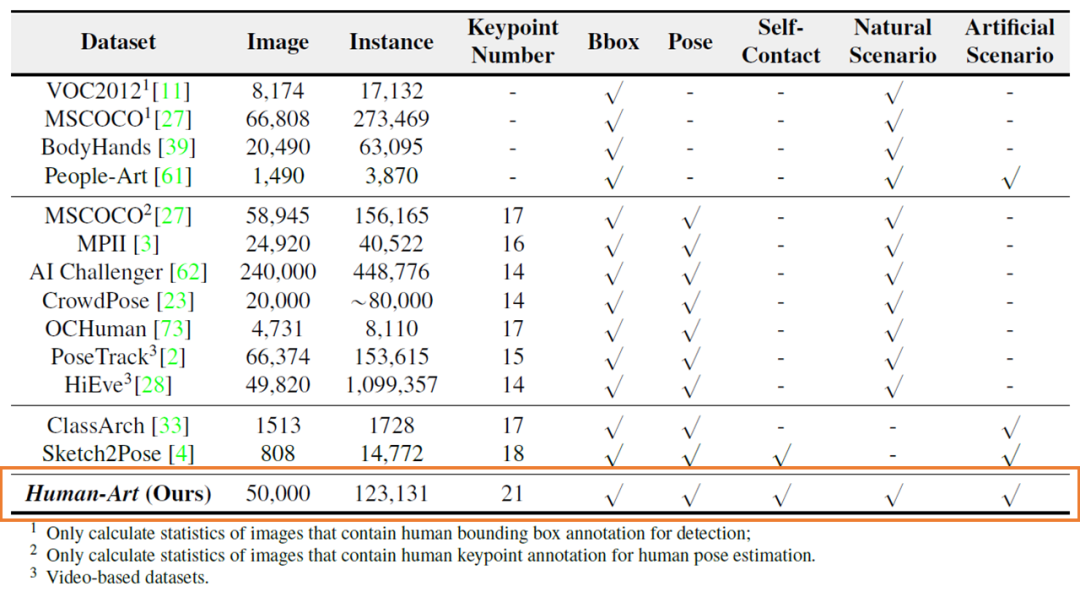
Human-Art数据集与常用数据集的对比
经过近半年的工作,本文研究团队收集了来自5个现实场景和15个虚拟场景的5万张高质量图像,提出了首个同时包含现实和虚拟场景,具有人体框、人体关键点、自接触点及文本描述的多场景大规模数据集Human-Art,弥补了先前数据集场景不足等问题。
Human-Art选取的场景,包括3个3D虚拟场景和12个2D虚拟场景。图片风格除了常见的油画、水墨画等绘画外,还有线条简单的儿童简笔画、素描画,形象大小各异的卡通画,造型和服装繁复的手办模型,以及中国传统的皮影等等。不同的场景都存在一定的数据处理难题,部分场景如雕塑、壁画的人物形象残缺或极难辨认等,需要研究团队耗费大量时间和人力解决。(小编:听说搭建数据集初期收集了近100万张图片,需要靠作者肉眼快速辨认才完成初筛……)经年累月斑驳褪色、细节难辨的壁画
也是Human-Art数据集涵盖的场景之一
Human-Art 每张图片标注了人体框、21 个人体关键点、自接触点及文本描述信息。为方便学术界和工业界的使用,Human-Art定义的21个人体关键点扩展了真实人体数据集MSCOCO中定义的17个关键点,新增4个脚趾尖、手指尖关键点。
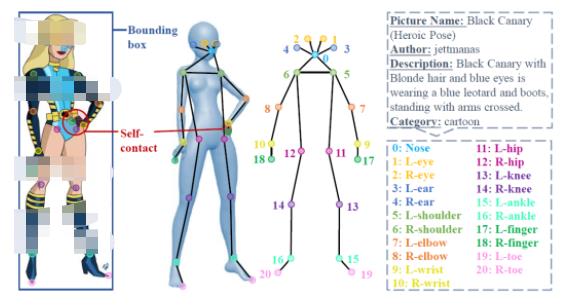
Human-Art的21个标注点信息
Human-Art 可支持多项人体相关的计算机视觉任务,如全场景人体检测、全场景人体 2D/3D 姿态估计、全场景人体图片生成,并为各项下游任务提供基准结果。相信未来将有助于提升各类模型在虚拟场景下训练的性能,也可以为更多研究方向如 out-of-distribution(OOD)问题等提供帮助,为学术界带来更多思考。
支持多项以人为主的下游视觉任务,
经Human-Art训练的模型表现如何?
下游任务一:人体检测
人体检测(Human Detection)是从场景中识别并框出人物。过往的检测方案存在两个问题:一是大多选用通用的物体数据集训练,没有特别针对人做检测,二是使用的数据集通常仅仅包含现实场景,人体检测器在虚拟风格上的泛化性极差。
Human-Art中的图片均以人为中心,支持对风格更具包容性的人体检测器训练。为了论证Human-Art数据集对于多风格训练的作用,研究团队在四个检测器(Faster R-CNN、YOLOX、Deformable DETR、DINO)上进行了实验。
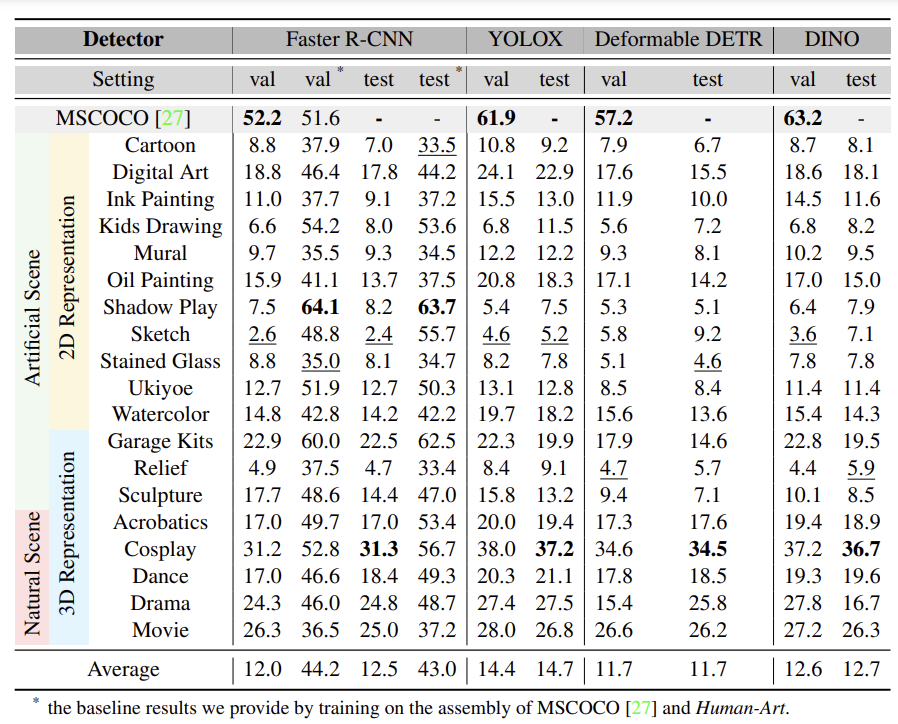
四种主要检测器
使用Human-Art训练测试结果
可以看到,未经过Human-Art训练的检测器在多风格人体数据上表现极差,而经过训练后,Faster R-CNN检测准确率在皮影风格上的提升可以高达56%,平均准确率提升达到31%。
下游任务二:2D人体姿态估计
人体姿态估计(Human Pose Estimation)是通过图片还原其中人体关键点的位置,主要划分为2D人体姿态估计和3D人体姿态估计。复杂姿态、遮挡和多样化的背景,使其仍然相当具有挑战性。
2D人体姿态估计可以被主要分为三类:自顶向下的方法(top-down)、自底向上的方法(bottom-up),以及单阶段方法(one-stage)。与人体检测类似,人体姿态识别也存在在虚拟风格上的泛化性问题。
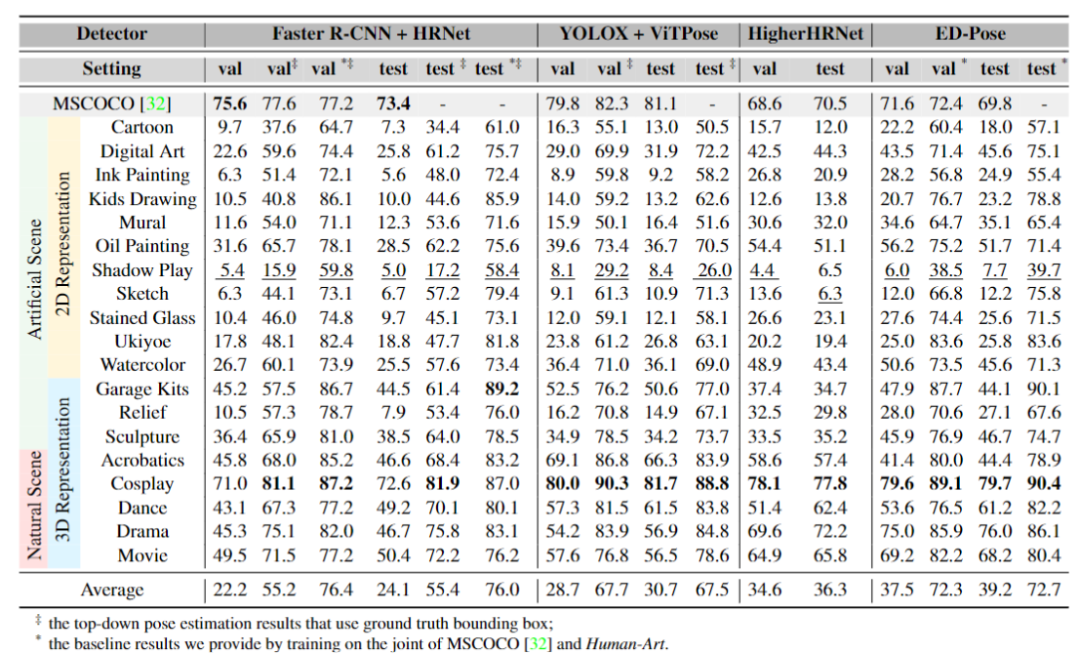
2D人体姿态估计中
使用Human-Art训练前后对比
研究团队在实验中对比了三类方法在Human-Art上的结果。由于自顶向下的方法严重依赖于检测器,使用未经训练的人体姿态检测器直接测试后的表现较难提升。相比之下,自底向上和单阶段方法训练的检测器达到了更高精度,如自底向上方法HigherHRNet在多风格数据上的结果相比自顶向下的SOTA方法ViTPose有约6个点的提升,单阶段方法ED-Pose框架训练的模型准确率更是高出近10个点。(拓展了解:ICLR 2023入选论文ED-Pose)
下游任务三:3D人体姿态估计
单目3D人体姿态估计的深度信息检测一直是任务难题,Human-Art标注的自接触点信息能优先缓解这一问题。自接触点通过合理的深度优化,将接触区域映射到粗略SMPL模型(一种常用3D人体姿态的表征方法)的顶点上,最小化接触顶点之间的距离。
Human-Art标注的自接触关键点
能帮助优化3D人体姿态估计
下游任务四:图片生成
Stable Diffusion等模型的提出,让图片生成任务成为领域内外的话题热点。然而现有生成的人物类图像,仍存在如多手多脚/少手少脚、肢体位置错乱等问题,且无法更为精准地控制生成地人体姿态等。
Human-Art提供了丰富的以人为中心的图片及对应标注,能为生成具有合理结构人体的图片提供了良好先验。同时,由于其丰富的标注,Human-Art可以有效辅助可控生成(如Text2Image、Pose & Text2Image),例如使用姿态信息(Pose)和文本(Text)信息训练作为条件指导生成。
Pose & Text2Image模型效果对比
图中Ours为基于Stable Diffusion改进的模型
在Human-Art及其他数据上共同训练的结果
审核编辑 :李倩
-
计算机视觉
+关注
关注
8文章
1703浏览量
46249 -
数据集
+关注
关注
4文章
1212浏览量
25004
原文标题:CVPR 2023 | 港中大&IDEA开源首个大规模全场景人体数据集Human-Art
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论