 保护模式下的内存管理
保护模式下的内存管理
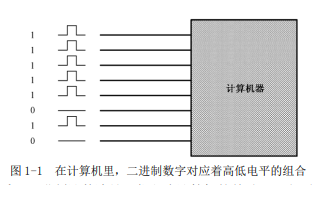
我们知道,内存可以看做一个非常大的数组,我们想要查找内存中某个元素的话,会通过数组的下标来指定,内存也是如此,不过这有一个前提是这个数组是由一组有序的字节组成的,在这个有序的字节数组中,每个字节都有一个唯一的地址,这个地址也叫做内存地址。
内存中存储着很多对象,每个对象是由不同字节组成的,比如一个 char 对象,一个 byte 对象,一个 int 对象等等,它们都分部在内存的各个位置中,CPU 对内存中这些对象的地址进行定位的操作就叫做内存寻址。内存从 0 地址处开始编址,总共能查找到多少位的内存地址呢?答:是根据总线宽度来定位的。由于 80X86 是 32 位的,所以总线宽度也是 32 位,因此一共有 2 ^ 32 个内存地址,所以总共可以存放 4GB 的内存地址。由于内存地址是连续的,于是可以连续的取出多个字节的数据类型,例如 int、long、double。
虽然能够寻址到对象,但是这些对象存放的字节顺序是不同的,这里分为两种存放方式,即大端法和小端法。
比如现在有一个 int 类型的对象,位于地址 0x100 处,它的十六进制数值是 0x01234567,我给你画一幅图你就明白这两个存放顺序的区别了。
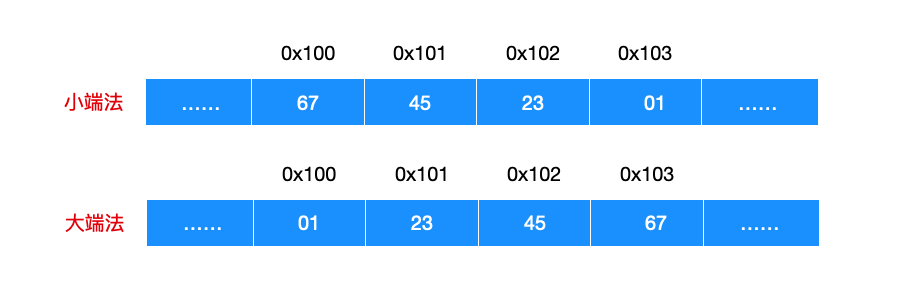
这个其实很好理解,0x01234567 的 int 数据类型可以拆分为 01 23 45 67 个字节,并且 01 是高位,67 是低位,于是可以解释小端法和大端法的存储顺序:即小端法是低位在前,而大端法是高位在前。大端法和小端法只是存储顺序的区别,和对象的位数、数值无关。大多数 Intel 机器都采用的是小端模式,所以 80X86 也是小端存储,而一些 IBM 和 Oracle 的大多数机器都是使用的大端存储方式。
由于计算机是无法直接将内存中的数据一次性全部寻址完毕,因为它相对实在太过庞大,所以内存一般会进行分段,这里就涉及一个疑问:即内存为什么要分段。我上面只是笼统的介绍了下。
内存为什么要分段?
分段机制把内存空间分成一个或多个段的线性区域,这部分线性区域可以使用段基址 + 段内偏移来确定。段基址部分由 16 位的段选择符来指定,其中 14 位是可以选择 2 ^ 14 次方即 16384 个段,段内偏移地址部分使用 32 位的值来指定,因此段内地址可以是 0 - 4G ,一个段的最大长度是 4 GB,这也就和上面所说的 4 GB 的内存地址相呼应。由 16 位段和 32 位段内偏移构成的 48 位地址或长指针称为一个逻辑地址,逻辑地址就是虚拟地址。
X86 有几个专门存放段基址的寄存器:CS、DS、ES、SS、FS 和 GS。其中 CS 用于寻址代码段,SS 用于寻址堆栈段,其他寄存器用于寻址数据段。在任何指定时刻由 CS 寻址的段称为当前代码段。此时 EIP 寄存器中就包含了当前代码段内下一条需要执行指令的偏移地址。此时的段基址:偏移地址就可以表示为 CS:EIP 了。
由段寄存器 SS 寻址的段称为当前堆栈段,栈顶由 ESP 寄存器给出,在任何时刻 SS:ESP 都指向栈顶,并且没有例外情况,其他四个是通用数据段寄存器,当指令中默认没有数据段时,由 DS 给出。
地址转换
一个完整的内存管理系统一般都会包含两部分:访问保护和地址转换。访问保护是为了防止一个应用程序访问的内存地址是另一块程序所使用的;地址转换就是给不同的应用程序提供一个动态的地址分配方式。访问保护和地址转换是相辅相成的。
地址转换通常以内存块作为基本单位,这里解释下什么是块,大家知道在 Linux 中,一切都是文件,而文件就是由一个个的块构成的,块(block)是用于描述文件系统的组成单位,也是数据处理的基本单位。虽说块是基本单位,但是其本质也是由一个个扇区构成的,常见的块有 512B、1KB、4KB 等。
地址转换有两种实现方式:分段机制和分页机制。x86 在内存管理的实现方式结合了分段和分页机制,下面是虚拟地址经过分段和分页后转换为物理地址的映射图
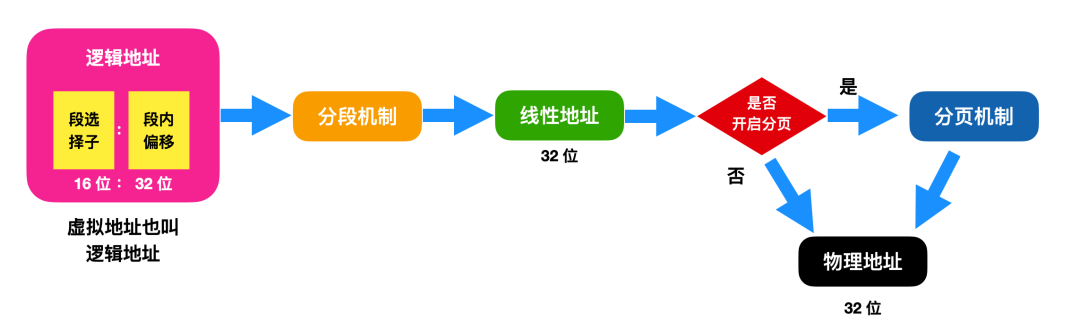
针对这张图,有必要解释一下:
首先,这张图包含三个地址和这三个地址的转换过程,从大体上来看,逻辑地址会经过分段基址转换后变为线性地址,线性地址是保护模式下的段基址 + 段内偏移,因此这张图是保护模式下的地址转换图。线性地址会经过分页机制后转换为物理地址,前提是需要开启分页机制;如果没有开启分页机制,线性地址 = 物理地址。
需要再说一下逻辑地址,逻辑地址里面包含段选择子和段内偏移,段选择子这个概念我刚开始接触也比较模糊,简单一点来说可以把它理解为是保护模式下的段基址,大家知道段基址是 16 位的,而段内偏移是 32 位的。
很多书或者文章中都提到了段选择符,其实段选择子就是段选择符,这完全是翻译问题,英文都是 selector。
后面会提到段描述符,段描述符和段选择子不是一回事,但段选择子是一个 16 位的段描述符。
再和大家说一下这个图上没有写出来的内容,现在大家知道逻辑地址可以转换为线性地址,线性地址可以转换为物理地址,那么根源是如何转换的呢?实际上这里使用的方式是 MMU(内存管理单元)进行转换;而线性地址转换为物理地址使用的是分页单元的硬件电路。具体的转换过程不是此篇文章讨论的重点,我们把重点还是放在分段和分页这两个机制上。
下面来详细聊一聊分段和分页这两个机制。
分段机制
这里推荐大家先看一下我写的 "内存为什么要分段" 的那段描述。
分段提供了隔绝代码、数据和堆栈区域的机制,这才使得多个程序能够运行在同一个内存空间中不会相互干扰。如果 CPU 中有多个程序或者任务正在运行,那么每个程序都可以分配各自的一套段(包含程序代码、数据和堆栈),CPU 通过加强段之间的界限来达到防止应用程序相互干扰的目的。
一个系统中所有使用的段都包含在 CPU 的线性地址空间中。为了定位指定段中的字节,程序必须提供逻辑地址才能进行转换。逻辑地址包含段选择子和段内偏移,每个段都有一个段描述符,段描述符用于指出段的大小、访问权限和段的特权级、段类型以及段第一个字节在线性地址空间中的位置(段基址)。逻辑地址的偏移量部分加到段基址上就可以定位段中某个字节的位置,因此段基址 + 偏移量形成了 CPU 线性地址空间中的地址。
线性地址空间与物理地址空间具有相同的结构,但是它们所能容纳的段相差甚远,虚拟地址也就是逻辑地址空间可包含最多 16 K 的段,而每个段可容纳的大小为 4 GB ,所以虚拟地址总共能查找到 64TB(2 ^ 46) 的段,线性地址和物理地址的空间是 4GB (2 ^ 32)。所以,如果禁用了分页机制,那么线性地址空间就是物理地址空间。
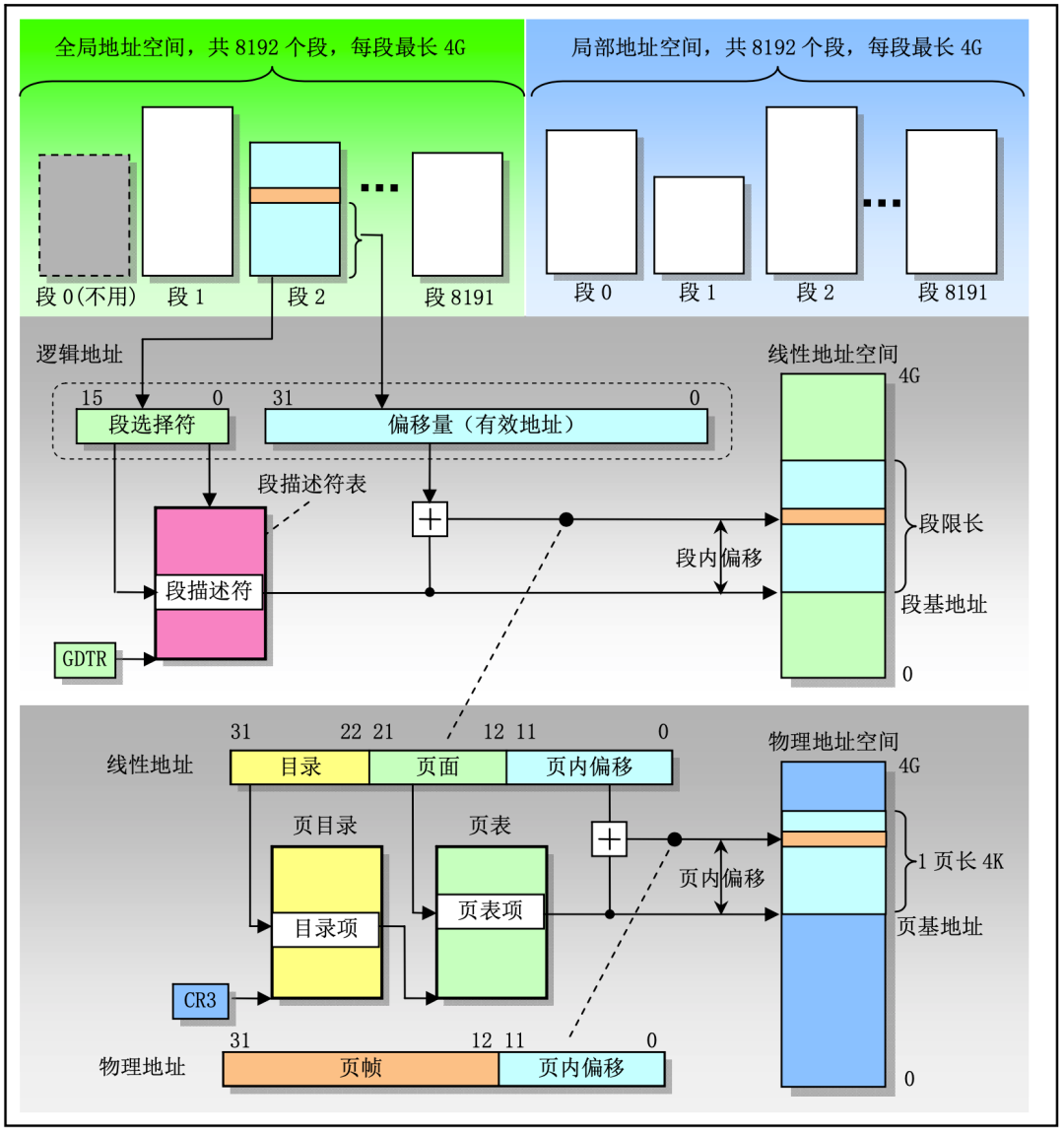
这幅图就是逻辑地址 -> 线性地址 -> 物理地址的映射图,GDT 表和 LDT 表各占一半的地址空间,各为 8192 个段,每个段最长为 4 G,从 GDT 表还是 LDT 表查询,具体从哪个表查还是要看段选择子的 TI 属性,段选择子的结构如下所示

段选择子总共分为三个部分:
RPL(Request Privilege Level):请求特权级,表示进程应该以什么权限来访问段,数值越大权限越小。
TI(Table Indicator):表示应该查询哪个表,TI = 0 查 GDT 表;TI = 1 查 LDT 表。
Index:CPU 会自动将 Index * 8,在加上 GDT 和 LDT 中的段基址,就是要加载的段描述符。
这里没有太细致的详解一下段描述符,因为此篇还是偏向于内存管理,没有太执着于某个细节。
逻辑地址由两部分组成,段选择子和偏移量,段选择字可以合成段描述符,然后它们会直接保存在 GDTR 中。段选择子和段内偏移经过 MMU 后可以转换成为线性地址。
分页机制
上面我们说到,线性地址是由逻辑地址转换过来的,如果禁用了分页机制,线性地址就是物理地址,如果开启分页机制,线性地址和逻辑地址空间的数量还是不同的。一般程序都是多任务的,而多任务通常定义的线性地址空间要比物理内存容量大得多,为什么呢?地址转换映射图上画着明明线性地址和物理地址都是 4G 的大小啊。那是因为,线性地址被虚拟存储技术所虚拟化了。
虚拟存储是一种内存管理技术,使用这项技术可以让我们产生内存空间要比实际的物理内存容量大的多的错觉,其本质是把内存虚拟化了,就是说内存可能只有 4G,但是你以为内存有 64 G,所以我为什么能开那么多应用程序的原因。
分页机制其实就是虚拟化的一种实现,在虚拟化的环境中,大量的线性地址空间会映射到一小块物理内存(RAM 或者 ROM)中。当使用分页时,每个段被划分成页面(一般为 4K),这个页面会存储在物理内存或硬盘上。操作系统通过使用一个页目录和页表来维护这些页面。当程序试图访问线性地址空间中的某一个地址位置时,CPU 就会使用页目录和页表把这个线性地址转换成物理地址,再存储在物理内存上。
如果当前访问的页面不在物理内存中,CPU 就会执行中断,一般错误就是页面异常,然后操作系统会把这个页面从硬盘上读入物理内存中,然后继续从中断处执行程序。操作系统经常会进行频繁的页面换入换出操作,这也是一个性能瓶颈所在。
分段中的每个段长度是不固定的,最大位 4G,而分页中的每个页面大小是固定的。不论在物理内存还是磁盘上,使用固定大小的页面更适合管理物理内存;而分段机制使用大小可变的块更适合处理复杂系统的逻辑分区。
虽然分段和分页是两种不同的地址转换机制,但是它们对整个地址变换是独立处理的,每个过程都是独立的。这两种机制都使用了一种中间表来存储表项映射,但是这个中间表的结构是不同的。段表存在线性地址空间中,页表则存储在物理地址空间。
保护机制
80x86 包含两种保护机制,第一种是为每个任务分配不同的虚拟地址空间来完全隔离各个任务。这是通过给每个任务逻辑地址到物理地址的不同变换得到的,每个应用程序只能访问自己虚拟空间内的数据和指令,只能通过它自己的映射得到物理地址;第二种机制是保护任务,保护操作系统的内存段和一些特殊寄存器不会被应用程序所访问。下面我们就来具体探讨一下这两个任务。
任务之间的保护
每个任务会单独的放在自己的虚拟地址空间中,再经过硬件映射成为物理地址,不同的虚拟地址会变换成为不同的物理地址,不会存在 A 的虚拟地址会映射到 B 所在的物理地址的范围内,这样就会把所有的任务都隔绝开,且不同任务之间不会相互干扰。
每个任务都有各自的映射表、段表和页表,当 CPU 切换不同的应用程序或任务时,这些表也会进行切换。
虚拟地址是操作系统的抽象,也就是说虚拟地址完全是操作系统所抽象出来能够更好管理应用程序和任务的一个载体,每个任务都可以把逻辑地址映射成为虚拟地址,这也表明每个任务都可以访问操作系统,操作系统可以被所有的任务所共享。这个所有任务都具有相同虚拟地址空间的部分被称为全局地址空间(Global address space),Linux 就使用到了全局地址空间。
全局地址空间中每个任务都有自己的唯一的虚拟地址空间,这个虚拟地址空间叫做局部地址空间(Local address space)。
内存段和寄存器的特殊保护
如果说操作系统在不同任务之间的保护是横向的话,那么对内存段和寄存器的等级保护就是纵向的。操作系统定义了 4 个特权级来对每个任务提供保护,来限制对任务中各段的访问。
优先级分为 4 个等级,0 最高,3 最低。一般最敏感的数据会被赋予最高优先级,它们只能被任务中最受信任的部分访问,不太敏感的数据会赋予低优先级;内核操作系统访问一般是 0 级,应用程序数据一般是 3 级。每个内存段都与一个特权级相关联。
我们知道 CPU 通过 CS 从段中取得指令和数据执行,从段中取得的指令和数据是具有特权级的,一般用当前特权级(Current Privilege Level)来访问,CPL 就是当前活动代码的特权级。每当有应用程序试图访问段时,就会与这个特权级进行比较,只有比段的特权级低才能够访问。
-
寄存器
+关注
关注
31文章
5377浏览量
121403 -
cpu
+关注
关注
68文章
10922浏览量
213322 -
内存
+关注
关注
8文章
3071浏览量
74421 -
内存管理
+关注
关注
0文章
168浏览量
14205 -
数组
+关注
关注
1文章
417浏览量
26041
原文标题:保护模式下的内存管理
文章出处:【微信号:cxuangoodjob,微信公众号:程序员cxuan】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TPA3255上电后直接进入欠压保护模式,是什么原因?
TAS5630B M1、M2、M3到底是设置硬件模式的还是保护模式的?
LED开关电源有哪些重要的保护模式
DOS下保护模式的汇编示范源程序(使用Tasm3.0)
80386保护模式编程深入学习

嵌入式远程调试器保护模式下调试功能
汇编语言学习课件_32位CPU及Windows基础
汇编语言学习课件_保护模式及其应用
如何在DOS实模式下直接访问整个4GB内存空间
X86汇编语言从实模式到保护模式PDF电子书免费下载





 工商网监
工商网监
评论