 决策规划:行为决策常用算法
决策规划:行为决策常用算法
作为L4级自动驾驶的优秀代表Robotaxi,部分人可能已经在自己的城市欣赏过他们不羁的造型,好奇心强烈的可能都已经体验过他们的无人“推背”服务。作为一个占有天时地利优势的从业人员,我时常在周末选一个人和的时间,叫个免费Robotaxi去超市买个菜。
刚开始几次乘坐,我的注意力全都放在安全员的双手,观察其是否在接管;过了一段时间,我的注意力转移到中控大屏,观察其梦幻般的交互方式;而现在,我的注意力转移到了智能上,观察其在道路上的行为决策是否足够聪明。
而这一观察,竟真总结出不少共性问题。比如十字路口左转,各家Robotaxi总是表现的十分小心谨慎,人类司机一脚油门过去的场景,Robotaxi总是再等等、再看看。且不同十字路口同一厂家的Robotaxi左转的策略基本一致,完全没有人类司机面对不同十字路口、不同交通流、不同天气环境时的“随机应变”。
面对复杂多变场景时自动驾驶行为决策表现出来的小心谨慎,像极了人类进入一个新环境时采取的猥琐发育策略。但在自动驾驶终局到来的那天,自动驾驶的决策规划能否像人类一样,在洞悉了人情社会的生活法则之后,做到“见人说人话”、“见人下饭”呢?
在让自动驾驶车辆的行为决策变得越来越像老司机的努力过程中,主要诞生了基于规则和基于学习的两大类行为决策方法。
基于规则的方法 在基于规则的方法中,通过对自动驾驶车辆的驾驶行为进行划分,并基于感知环境、交通规则等信息建立驾驶行为规则库。自动驾驶车辆在行驶过程中,实时获取交通环境、交通规则等信息,并与驾驶行为规则库中的经验知识进行匹配,进而推理决策出下一时刻的合理自动驾驶行为。
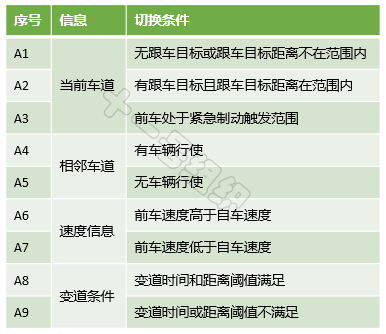
正如全局路径规划的前提是地图一样,自动驾驶行为分析也成为基于规则的行为决策的前提。不同应用场景下的自动驾驶行为不完全相同,以高速主干路上的L4自动驾驶卡车为例,其自动驾驶行为可简单分解为单车道巡航、自主变道、自主避障三个典型行为。
单车道巡航是卡车L4自动驾驶系统激活后的默认状态,车道保持的同时进行自适应巡航。此驾驶行为还可以细分定速巡航、跟车巡航等子行为,而跟车巡航子行为还可以细分为加速、加速等子子行为,真是子子孙孙无穷尽也。
自主变道是在变道场景(避障变道场景、主干路变窄变道场景等)发生及变道空间(与前车和后车的距离、时间)满足后进行左/右变道。自主避障是在前方出现紧急危险情况且不具备自主变道条件时,采取的紧急制动行为,避免与前方障碍物或车辆发生碰撞。其均可以继续细分,此处不再展开。
上面列举的驾驶行为之间不是独立的,而是相互关联的,在一定条件满足后可以进行实时切换,从而支撑起L4自动驾驶卡车在高速主干路上的自由自在。现将例子中的三种驾驶行为之间的切换条件简单汇总如表2,真实情况比这严谨、复杂的多,此处仅为后文解释基于规则的算法所用。
表2 状态间的跳转事件
在基于规则的方法中,有限状态机(FiniteStateMaechine,FSM)成为最具有代表性的方法。2007年斯坦福大学参加DARPA城市挑战赛时的无人车“Junior”,其行为决策采用的就是有限状态机方法。
有限状态机是一种离散的数学模型,也正好符合自动驾驶行为决策的非连续特点,主要用来描述对象生命周期内的各种状态以及如何响应来自外界的各种事件。有限状态机包含四大要素:状态、事件、动作和转移。事件发生后,对象产生相应的动作,从而引起状态的转移,转移到新状态或维持当前状态。
我们将上述驾驶行为定义为有限状态机的状态,每个状态之间在满足一定的事件(或条件)后,自动驾驶车辆执行一定的动作后,就可以转移到新的状态。比如单车道巡航状态下,前方车辆低速行驶,自车在判断旁边车道满足变道条件要求后,切换到自主变道状态。自主变道完成后,系统再次回到单车道巡航状态。
结合表2中的切换条件,各个状态在满足一定事件(或条件)后的状态跳转示意图如图25所示。
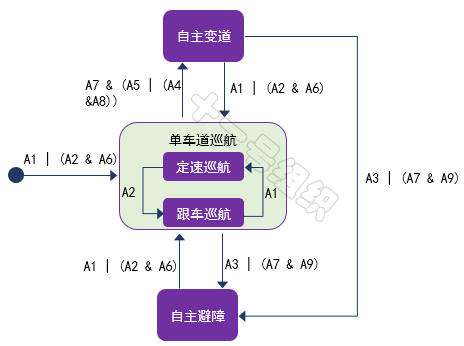
图25 状态跳转示意图
基于有限状态机理论构建的智能车辆自动驾驶行为决策系统,可将复杂的自动驾驶过程分解为有限个自动驾驶驾驶行为,逻辑推理清晰、应用简单、实用性好等特点,使其成为当前自动驾驶领域目前最广泛使用的行为决策方法。
但该方法没有考虑环境的动态性、不确定性以及车辆运动学以及动力学特性对驾驶行为决策的影响,因此多适用于简单场景下,很难胜任具有丰富结构化特征的城区道路环境下的行为决策任务。
基于学习的方法
行为决策水平直接决定了车辆的智能化水平,同时伴随着自动驾驶等级的提高,人们不仅要求其在复杂场景下做出正确的决策,还要求在无法预测的突发情况下做出正确的决策,更过分的是还要求在无法完全感知周围交通环境的情况下,进行合理的决策。
上文介绍的基于规则的行为决策方法依靠专家经验搭建的驾驶行为规则库,但是由于人类经验的有限性,智能性不足成为基于规则的行为决策方法的最大制约,复杂交通工况的事故率约为人类驾驶员的百倍以上。鉴于此,科研工作者开始探索基于学习的方法,并在此基础上了诞生了数据驱动型学习方法和强化学习方法。
数据驱动型学习是一种依靠自然驾驶数据直接拟合神经网络模型的方法,首先用提前采集到的老司机开车时的自然驾驶数据训练神经网络模型,训练的目标是让自动驾驶行为决策水平接近老司机。而后将训练好的算法模型部署到车上,此时车辆的行为决策就像老司机一样,穿行在大街小巷。读者可参见端到端自动驾驶章节中介绍的NVIDIA demo案例。
强化学习方法通过让智能体(行为决策主体)在交互环境中以试错方式运行,并基于每一步行动后环境给予的反馈(奖励或惩罚),来不断调整智能体行为,从而实现特定目的或使得整体行动收益最大。通过这种试错式学习,智能体能够在动态环境中自己作出一系列行为决策,既不需要人为干预,也不需要借助显式编程来执行任务。
强化学习可能不是每个人都听过,但DeepMind开发的围棋智能AlphaGo(阿尔法狗),2016年3月战胜世界围棋冠军李世石,2017年5月后又战胜围棋世界排名第一柯洁的事,大家应该都有所耳闻。更过分的是,半年后DeepMind在发布的新一代围棋智能AlphaZero(阿尔法狗蛋),通过21天的闭关修炼,就战胜了家族出现的各种狗子们,成功当选狗蛋之王。
而赋予AlphaGo及AlphaZero战胜人类棋手的魔法正是强化学习,机器学习的一种。机器学习目前有三大派别:监督学习、无监督学习和强化学习。监督学习算法基于归纳推理,通过使用有标记的数据进行训练,以执行分类或回归;无监督学习一般应用于未标记数据的密度估计或聚类;
强化学习自成一派,通过让智能体在交互环境中以试错方式运行,并基于每一步行动后环境给予的反馈(奖励或惩罚),来不断调整智能体行为,从而实现特定目的或使得整体行动收益最大。通过这种试错式学习,智能体能够在动态环境中自己作出一系列决策,既不需要人为干预,也不需要借助显式编程来执行任务。
这像极了马戏团训练各种动物的过程,驯兽师一个抬手动作(环境),动物(智能体)若完成相应动作,则会获得美味的食物(正反馈),若没有完成相应动作,食物可能换成了皮鞭(负反馈)。时间一久,动物就学会基于驯兽师不同的手势完成不同动作,来使自己获得最多数量的美食。
大道至简,强化学习亦如此。一个战胜人类围棋冠军的“智能”也仅由五部分组成:智能体(Agent)、环境(Environment)、状态(State)、行动(Action)和奖励(Reward)。强化学习系统架构如图26所示,结合自动驾驶代客泊车中的泊入功能,我们介绍一下各组成的定义及作用。
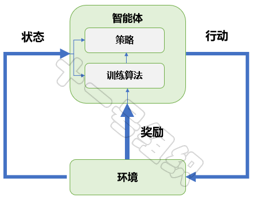
图26 强化学习系统架构
代客泊车泊入功能的追求非常清晰,就是在不发生碰撞的前提下,实现空闲停车位的快速泊入功能。这个过程中,承载强化学习算法的控制器(域控制器/中央计算单元)就是智能体,也是强化学习训练的主体。智能体之外的整个泊车场景都是环境,包括停车场中的立柱、车辆、行人、光照等。
训练开始后,智能体实时从车载传感器(激光雷达、相机、IMU、超声波雷达等)读取环境状态,并基于当前的环境状态,采取相应的转向、制动和加速行动。如果基于当前环境状态采用的行动,是有利于车辆快速泊入,则智能体会得到一个奖励,反之则会得到一个惩罚。
在奖励和惩罚的不断刺激下,智能体学会了适应环境,学会了下次看到空闲车位时可以一把倒入,学会了面对不同车位类型时采取不同的风骚走位。
从上述例子,我们也可以总结出训练出一个优秀的“智能”,大概有如下几个步骤:
(1)创建环境。定义智能体可以学习的环境,包括智能体和环境之间的接口。环境可以是仿真模型,也可以是真实的物理系统。仿真环境通常是不错的起点,一是安全,二是可以试验。
(2)定义奖励。指定智能体用于根据任务目标衡量其性能的奖励信号,以及如何根据环境计算该信号。可能需要经过数次迭代才能实现正确的奖励塑造。
(3)创建智能体。智能体由策略和训练算法组成,因此您需要:
(a)选择一种表示策略的方式(例如,使用神经网络或查找表)。思考如何构造参数和逻辑,由此构成智能体的决策部分。
(b)选择合适的训练算法。大多数现代强化学习算法依赖于神经网络,因为后者非常适合处理大型状态/动作空间和复杂问题。
(4)训练和验证智能体。设置训练选项(如停止条件)并训练智能体以调整策略。要验证经过训练的策略,最简单的方法是仿真。
(5)部署策略。使用生成的 C/C++ 或 CUDA 代码等部署经过训练的策略表示。此时无需担心智能体和训练算法;策略是独立的决策系统。
强化学习方法除了具有提高行为决策智能水平的能力,还具备合并决策和控制两个任务到一个整体、进行统一求解的能力。将决策与控制进行合并,这样既发挥了强化学习的求解优势,又能进一步提高自动驾驶系统的智能性。实际上,人类驾驶员也是具有很强的整体性的,我们很难区分人类的行为中哪一部分是自主决策,哪一部分是运动控制。
现阶段强化学习方法的应用还处在摸索阶段,应用在自动驾驶的潜力还没有被完全发掘出来,这让我想起了母校的一句校歌:“能不奋勉乎吾曹?”
审核编辑 :李倩
-
神经网络
+关注
关注
42文章
4789浏览量
101528 -
算法
+关注
关注
23文章
4644浏览量
93670 -
自动驾驶
+关注
关注
787文章
13992浏览量
167632
原文标题:决策规划:行为决策常用算法
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
粒子群算法对决策变量和适应度函数的约束问题
关于决策树,这些知识点不可错过
基于决策论的Agent个性化行为选择
一个基于粗集的决策树规则提取算法
无人驾驶汽车决策技术
配电网规划决策中的可计算性问题研究
强化学习与智能驾驶决策规划
决策规划系列:运动规划常用算法
自动驾驶决策规划算法第一章笔记






 工商网监
工商网监
评论