 英伟达Jetson设备上的YOLOv8性能基准测试
英伟达Jetson设备上的YOLOv8性能基准测试

我们将谈论在不同的NVIDIA Jetson 系列设备上运行YOLOv8 模型的性能基准测试。我们特别选择了3种不同的Jetson设备进行测试,它们是 Jetson AGX Orin 32GB H01套件、使用Orin NX 16GB构建的reComputer J4012,以及使用Xavier NX 8GB构建的reComputer J2021。
什么是 YOLOv8 ?
YOLOv8 由 Ultralytics 公司开发,是一个尖端的、最先进的(SOTA)模型,它建立在以前的 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提高性能和灵活性。YOLOv8 被设计为快速、准确和易于使用,使其成为广泛的物体检测、图像分割和图像分类任务的绝佳选择。
YOLOv8 模型
YOLOv8有不同的模型类型,基于参数的数量,将关系到模型的准确性。因此,模型越大,它就越准确。例如,YOLOv8x是最大的模型,它在所有模型中具有最高的准确性。
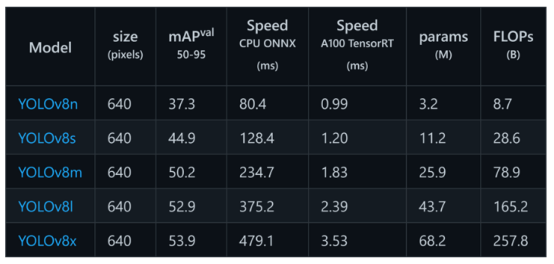
为什么我们需要进行性能基准测试 ?
通过运行性能基准,你可以知道在特定设备上运行的特定模型类型可以获得多大的推理性能。这对于NVIDIA Jetson平台等嵌入式设备来说更为重要,因为如果你知道你的应用程序想要使用的确切模型类型,你就可以决定哪种硬件适合运行该模型。
为什么我们需要 TensorRT基准测试 ?
TensorRT是由NVIDIA开发的一个库,用于在NVIDIA GPU上提高推理速度。TensorRT建立在CUDA之上,与运行PyTorch和ONNX等本地模型相比,在许多实时服务和嵌入式应用中,它的推理速度可以提高2到3倍。
在NVIDIA Jetson 设备上安装YOLOv8
第1步:按照Wiki中的介绍步骤,在Jetson设备中安装JetPack 系统。
第2步:按照wiki的 "安装必要的软件包 "和 "安装PyTorch和Torchvision "部分,在Jetson设备上安装YOLOv8。
如何运行基准测试 ?
当你在NVIDIA Jetson设备上安装带有SDK组件的NVIDIA JetPack时,会有一个名为trtexec的工具。该工具实际上位于随SDK组件安装而来的TensorRT内。这是一个使用TensorRT的工具,无需开发自己的应用程序。
trtexec工具有三个主要用途
在随机或用户提供的输入数据上对网络进行基准测试。
从模型中生成序列化的引擎。
从构建器中生成一个序列化的时序缓存。
在这里,我们可以使用trtexec工具对不同参数的模型进行快速基准测试。但首先,你需要有一个ONNX模型,我们可以通过使用Ultralytics YOLOv8来生成这个ONNX模型。
第1步:使用ONNX模型建立:
yolo mode=export model=yolov8s.pt format=onnx
这将下载最新的yolov8s.pt模型并转换为ONNX格式。
第2步:使用trtexec建立引擎文件,如下所示:
cd /usr/src/tensorrt/bin ./trtexec --onnx=--saveEngine=
比如说:
./trtexec --onnx=/home/nvidia/yolov8s.onnx -- saveEngine=/home/nvidia/yolov8s.engine
这将输出性能结果,如下所示,同时生成一个.引擎文件。默认情况下,它将把ONNX转换为FP32精度的TensorRT优化的文件,你可以看到输出如下:
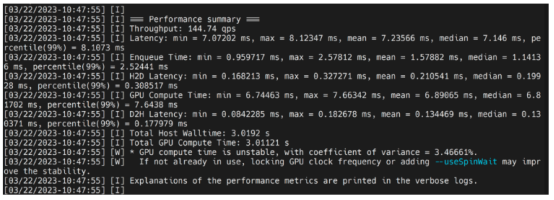
在这里,我们可以把平均延迟看作是7.2ms,换算成139FPS。
然而,如果你想要INT8精度,提供更好的性能,你可以执行上述命令,如下所示:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine --int8
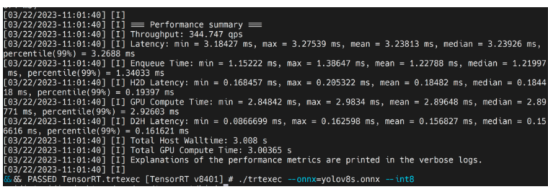
在这里,我们可以把平均延迟看作是3.2ms,换算成313FPS。
如果你也想在FP16精度下运行,你可以执行如下命令:
./trtexec --onnx=/home/nvidia/yolov8s.onnx --saveEngine=/home/nvidia/yolov8s.engine --fp16
要检查YOLOv8模型的默认PyTorch版本的性能,你可以简单地运行推理并检查延迟,如下所示:
yolo detect predict model=yolov8s.pt source='<>'
在这里,你可以根据本页面上的表格来改变来源。
另外,如果你不指定来源,它将默认使用一个名为 "bus.jpg "的图像。
基准测试结果
在进入基准测试结果之前,我将快速强调我们用于基准测试过程的每台设备的AI性能。
| Jetson Device | AGX Orin 32GB H01 Kit | reComputer J4012 built with Orin NX 16GB | reComputer J2021 built with Xavier NX 8GB |
| AI Performance | 200TOPS | 100TOPS | 21TOPS |
现在我们将看一下基准图,以比较YOLOv8在单个设备上的性能。我已经用640×640的默认PyTorch模型文件进行了所有的基准测试,如上文所解释的那样转换为ONNX格式。
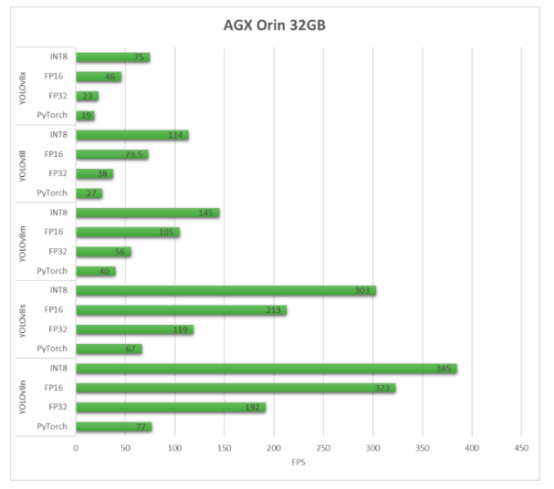
AGX Orin 32GB H01 Kit
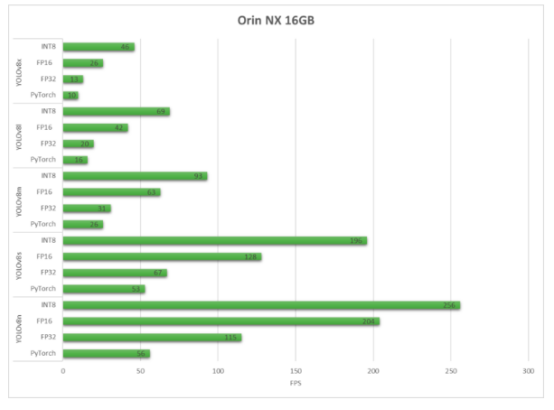
reComputer J4012 built with Orin NX 16GB
reComputer J2021 built with Xavier NX 8GB
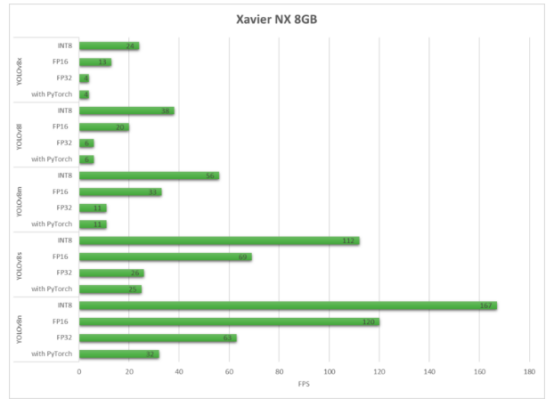
正如我们所看到的,TensorRT可以带来性能上的大幅提升。
接下来,我们将从不同的角度看一下基准图,在不同的设备上比较每个YOLOv8模型的性能。
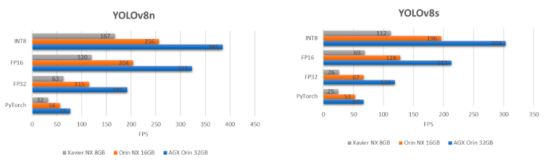
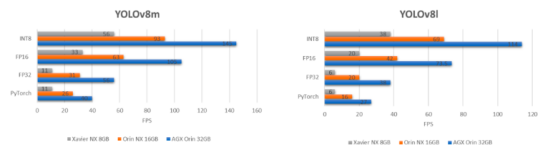
如果我们比较一下最大的YOLOv8模型,即在上述3个设备上运行的YOLOv8x,我们会得到以下结果:
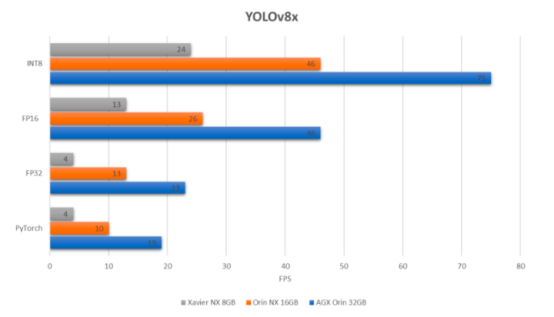
正如你所看到的,在最大的YOLOv8x模型上使用INT8精度,我们可以在AGX Orin 32GB上实现约75的FPS,这对于一个嵌入式设备来说是非常令人印象深刻的!我们可以看到,在AGX Orin 32GB上的FPS为1.5,而在AGX Orin 32GB上的FPS为2.5!
AI 边缘计算盒子
reComputer J2021-Edge AI 设备
J2021是一款采用Jetson Xavier NX 8GB模块的边缘AI设备,可提供高达21TOPS算力,丰富的IO端口包括USB 3.1端口(4x)、用于WIFI的M.2接口、用于SSD的M.2接口、RTC、CAN、树莓派 GPIO 40针扩展接口等;外壳采用铝合金材质带冷却风扇,预装JetPack系统,可以作为NVIDIA Jetson Xavier NX Dev Kit的替代品,为您的AI应用开发和部署提供支持。
reComputer J4012-Edge AI 边缘计算设备
reComputer J4012是一款采用NVIDIA Jetson Orin NX 16GB模块的边缘AI设备,可提供高达100 TOPS算力的AI性能,并拥有丰富的IO接口,包括USB 3.2端口(4x)、HDMI 2.1、用于WIFI的M.2接口、用于SSD的M.2接口、RTC、CAN、树莓派GPIO 40针接口等;外壳采用铝合金材质自带散热风扇,预装NVIDIA JetPack的Jetpack系统。作为NVIDIA Jetson生态系统的一部分,reComputer J4012可以为您的AI应用开发和部署提供支持。
写在最后
根据上述所有基准测试,多年来,在英伟达Jetson Orin平台等嵌入式设备上,推理性能似乎有了显著提高,现在我们几乎可以用这种紧凑的设备来匹配服务器级别的性能了!
-
AI
+关注
关注
91文章
41101浏览量
302579 -
基准测试
+关注
关注
0文章
21浏览量
7815 -
模型
+关注
关注
1文章
3818浏览量
52265 -
英伟达
+关注
关注
23文章
4115浏览量
99613 -
边缘计算
+关注
关注
22文章
3560浏览量
53688
原文标题:边缘计算 | 英伟达Jetson设备上的YOLOv8性能基准测试
文章出处:【微信号:ChaiHuoMakerSpace,微信公众号:柴火创客空间】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型

YOLOv8版本升级支持小目标检测与高分辨率图像输入
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型

教你如何用两行代码搞定YOLOv8各种模型推理

三种主流模型部署框架YOLOv8推理演示
解锁YOLOv8修改+注意力模块训练与部署流程
如何修改YOLOv8的源码
日本yolov8用户案例

基于YOLOv8的自定义医学图像分割

基于OpenCV DNN实现YOLOv8的模型部署与推理演示
RV1126 yolov8训练部署教程
使用ROCm™优化并部署YOLOv8模型



评论