 在视觉语言表示学习中建立编码器间的桥梁
在视觉语言表示学习中建立编码器间的桥梁
0. Take-away messages
提出了一个简单有效的视觉语言模型架构,BridgeTower,通过在顶层单模态层和每个跨模态层之间建立桥梁,成功地引入了不同语义层次的视觉和文本表示,从而提高了跨模态编码器中注意力头的多样性,并在各种任务上实现了突出的性能改进。
在公平的评估设置下,与Two-Tower架构的METER模型相比,BridgeTower显著地提高了模型的多模态表示能力。
仅使用400万张图片进行视觉语言预训练,BridgeTower在各种视觉语言下游任务上取得了十分强大的性能,击败了许多用更多数据和参数进行预训练的强大模型。
BridgeTower可以适用于不同的视觉、文本或跨模态编码器。
1. 背景与动机

视觉语言任务示例
图源:12-in-1: Multi-Task Vision and Language Representation Learning
视觉语言研究的目标,是训练一个能够理解图像和文本的智能AI系统。上图展示了一些流行的视觉语言任务。视觉问答是其中最著名的任务之一,它需要根据输入图像来回答和图片相关的问题。
各类视觉语言模型
自2019年以来,在大规模图像-文本对的自监督预训练的帮助下,基于Transformer的视觉语言模型取得了显著的进展。其中,具有双塔结构的视觉语言 (VL) 模型在视觉语言表示学习中占主导地位。基于不同的文本和视觉编码器,人们提出了各种模型架构和预训练目标。从模型架构的角度来看,近期大多数的VL工作,可以看作是由三个模块组成的双塔架构,即文本编码器、视觉编码器,以及在它们之上的跨模态融合模块。不同的VL模型在这三个模块的设计上有所不同。
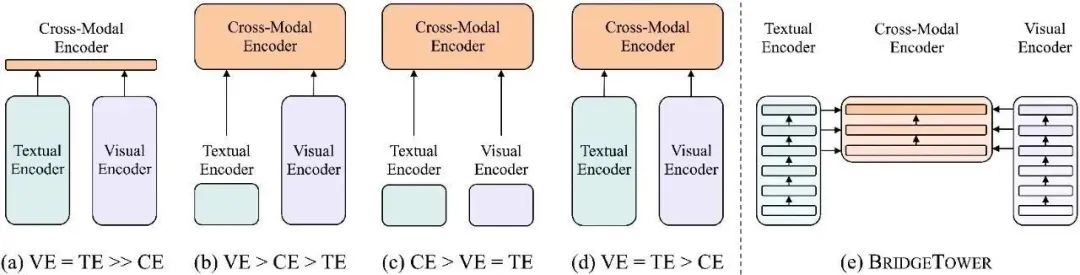
视觉语言模型架构简述
图(a)-(d)是目前的四类视觉语言模型。图(e)简要说明了BridgeTower的模型结构。VE、TE和CE分别是视觉编码器、文本编码器和跨模态编码器的简称。每个矩形的高度代表其相对计算成本。本图受到了ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision的启发。
目前的VL模型要么使用轻量级的单模态编码器,并学习在深度跨模态编码器中同时提取、对齐和融合两种模态,要么将预训练的深层单模态编码器的最后一层单模态表示,送入顶部的跨模态编码器中。这两种方法都有可能限制视觉-语言表示的学习,并进一步限制模型的性能。
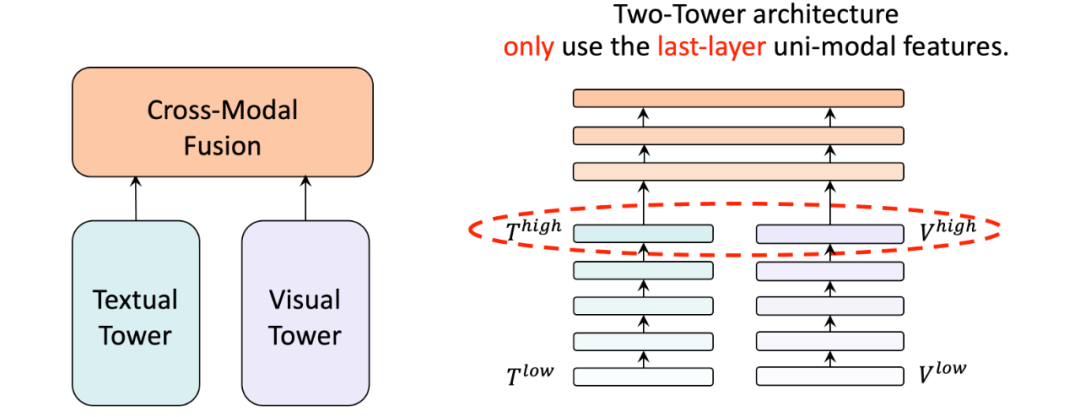
动机
如果我们深入双塔结构的单模态塔 (编码器) ,例如METER模型。我们可以发现他们只将最后一层的单模态特征直接送入顶部的跨模态融合模块,忽略了深层单模态塔的不同层的语义信息。我们自然地想到,能否在不同层的预训练单模态塔和跨模态融合模块之间建立起桥梁,以充分利用多层单模态特征?
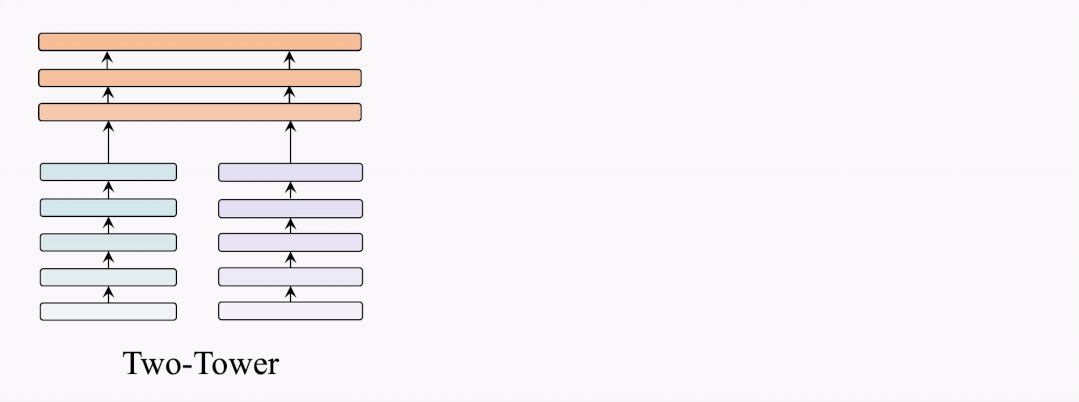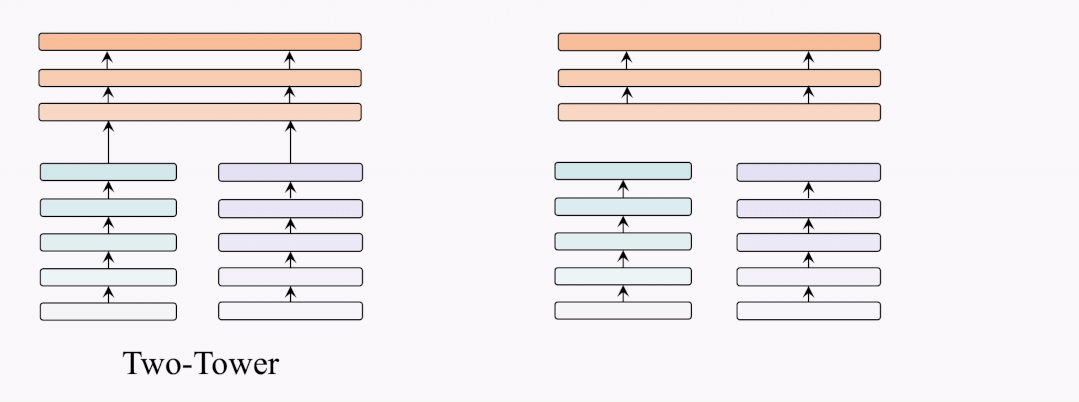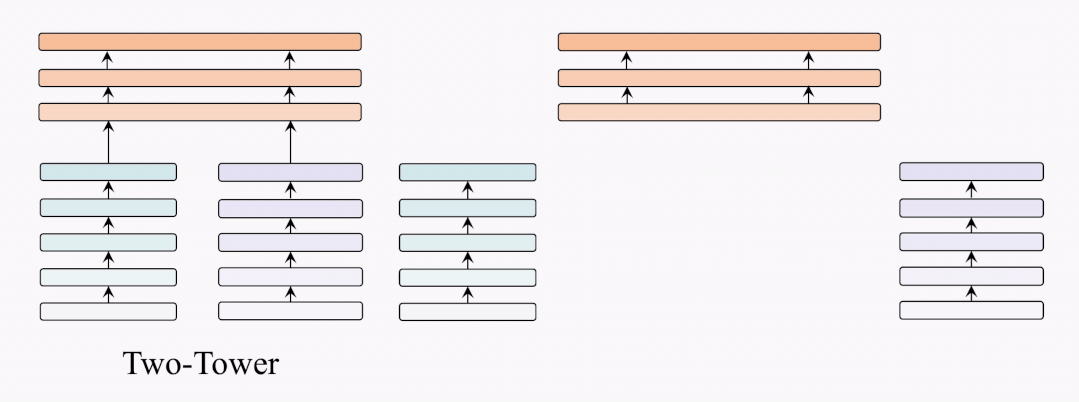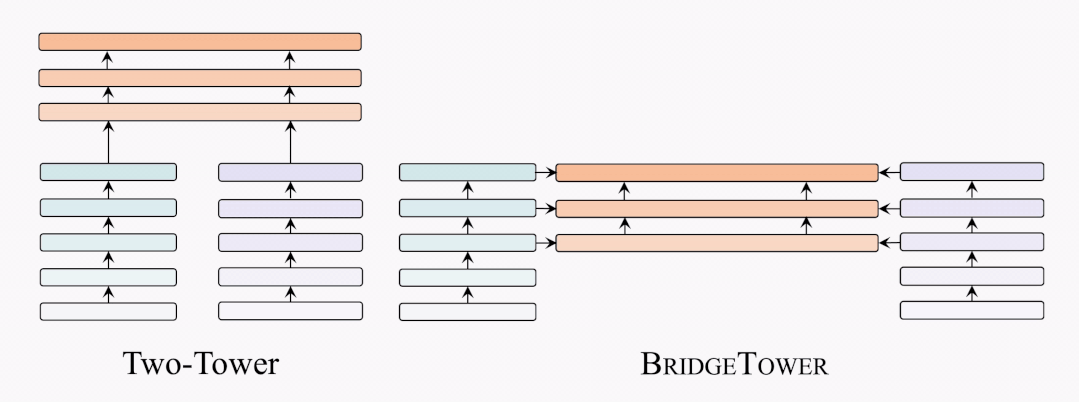
架构对比
因此,我们提出了BridgeTower架构。与双塔架构不同,BridgeTower在跨模态融合模块和单模态编码器之间建立起了多座桥梁。二者的主要区别在于,双塔结构只融合最后一层的特征,而BridgeTower则逐渐融合单模态编码器顶部的多层特征。
2. 模型架构
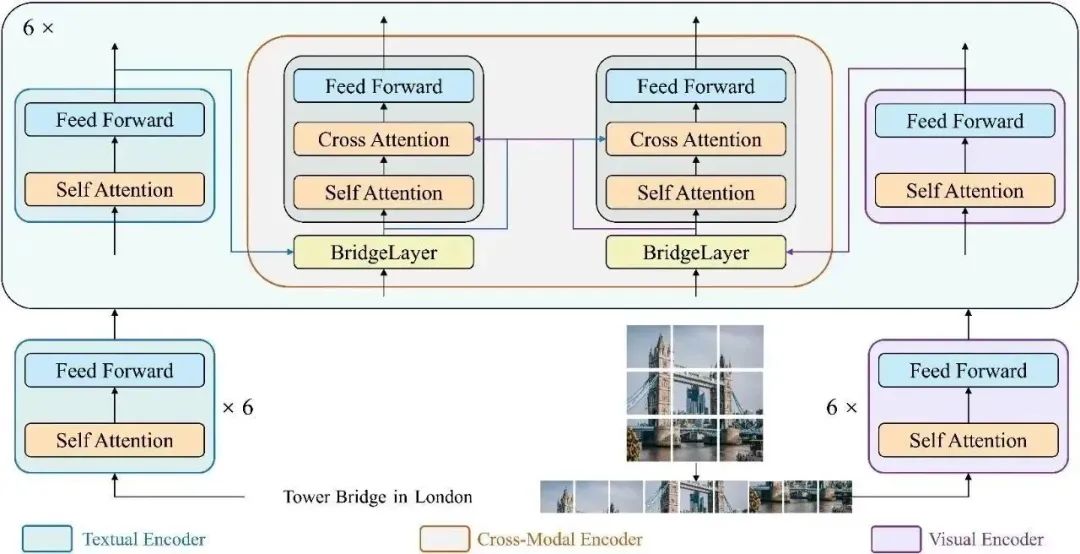
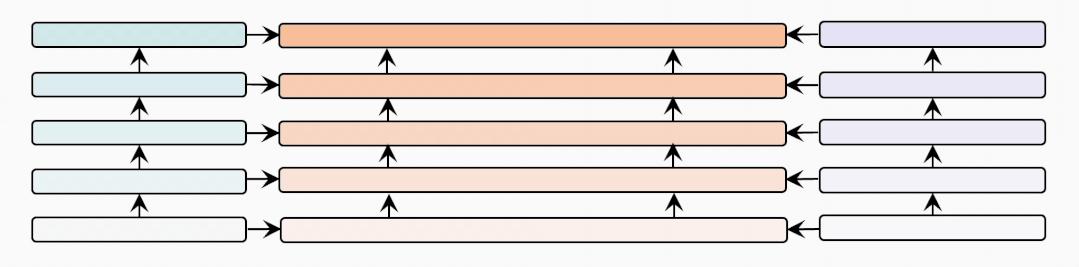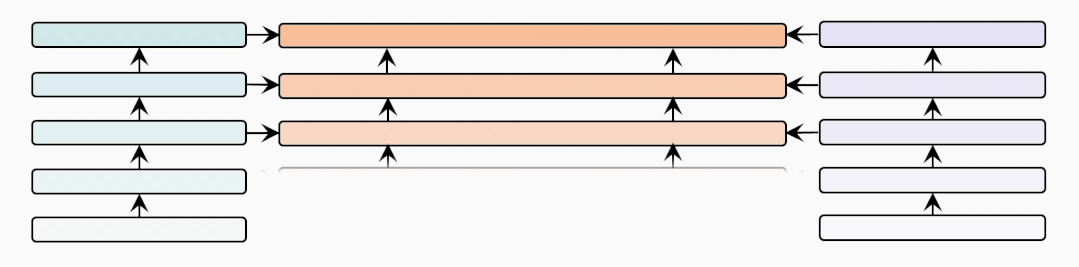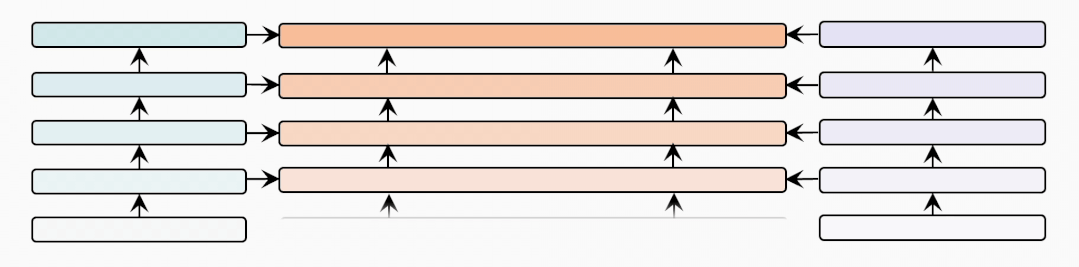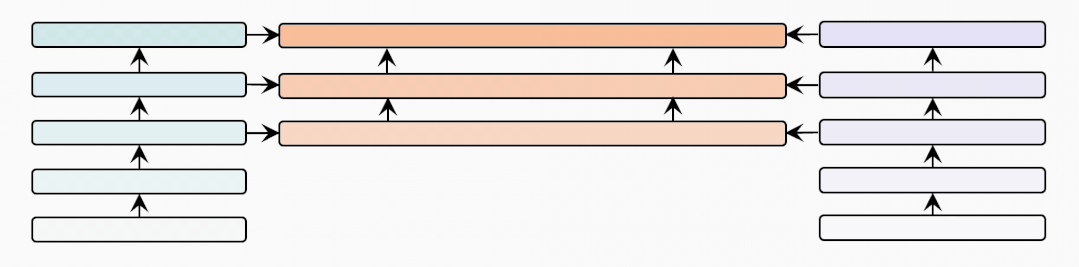
模型架构
这里我们展示了BridgeTower的详细架构图。具体而言,我们采用12层的RoBERTa-base和12层的CLIP-ViT-B作为单模态编码器。跨模态编码器为6层,每一层都添加了BridgeLayer来与单模态编码器的顶部6层建立连接。
这使得预训练单模态编码器中的不同语义层次的视觉和文本表示,通过BridgeLayer与跨模态表示进行融合,从而促进了跨模态编码器中,高效的,自下而上的跨模态对齐与融合。需要注意的是,BridgeTower架构适用于不同的视觉、文本或跨模态编码器。
3. 设计选择
我们对BridgeTower的不同设计选择进行了广泛的实验。
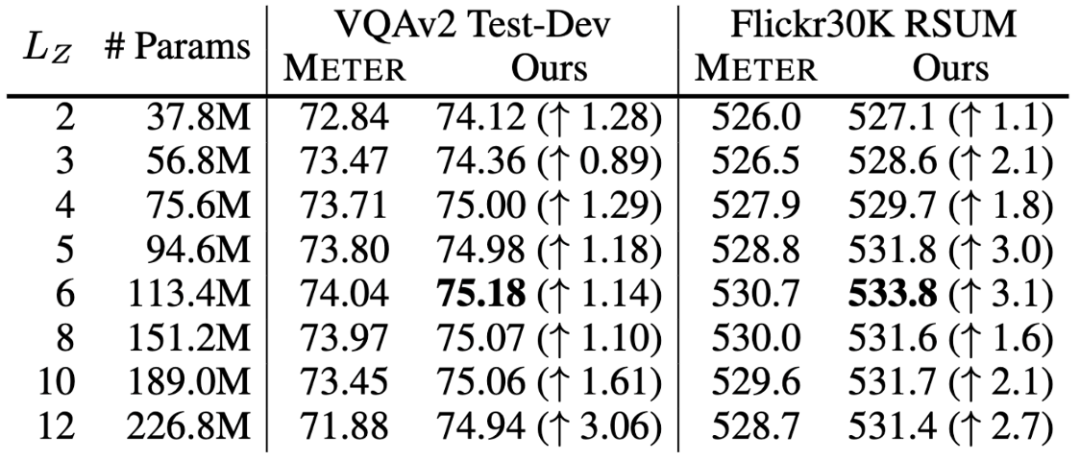
3.1 BridgeLayer的定义
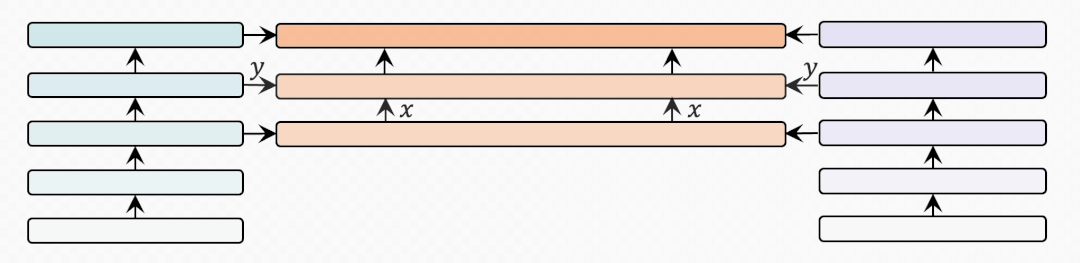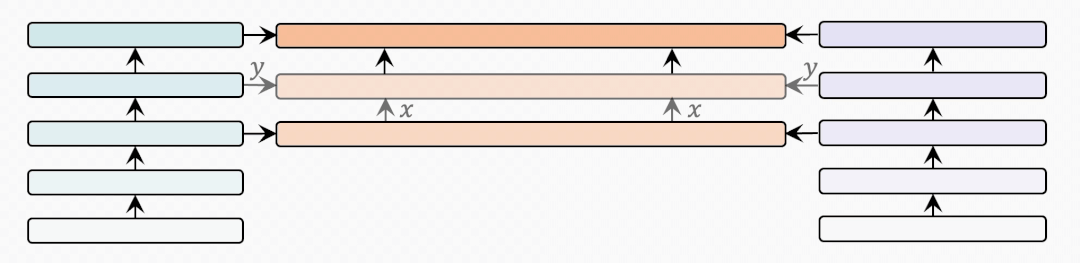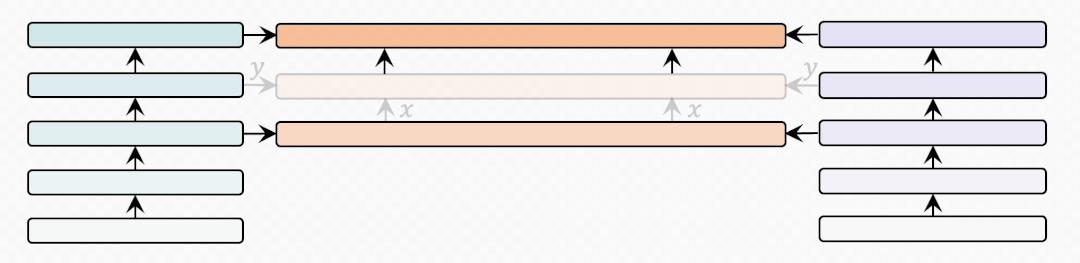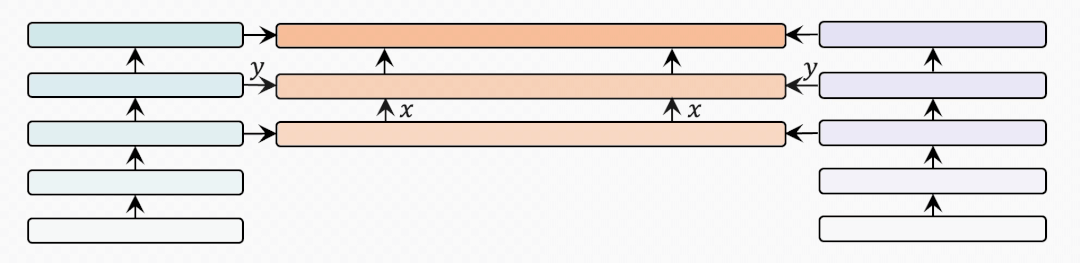
bridge-layer
首先是BridgeLayer的定义,也就是单模态信息与跨模态信息如何在BridgeLayer中融合。

上表展示了不同定义的BridgeLayer的参数量和其在VQAv2和Flickr30K数据集上的性能。RSUM表示图文检索任务的召回度量之和。
表示前一层输出的跨模态表示。
表示相应的单模态表示。我们省略了每一行中使用的 。有些出乎意料但又合乎情理的是,第一行中的 使用最小的参数量得到了最好的结果。
3.2 Cross-Modal Layer的数量
cross-modal-layer
接着我们基于12层的文本和视觉编码器,研究不同数量的跨模态层对性能的影响。
表示跨模态层的数量,并且BridgeTower使用Top-的单模态表示作为跨模态层的输入。我们在两个数据集上比较不同下,METER和BridgeTower的性能情况,我们发现更多的跨模态层并不能不断提高性能。这可能是由于
更多的跨模态层需要更多的训练数据。
顶层的单模态表示有利于跨模态对齐和融合,而底层的单模态表示可能不利于,甚至是有害于跨模态表示的学习。虽然METER和BridgeTower之间唯一的区别是BridgeLayers,但BridgeTower在不同数量的跨模态层中始终获得了一致的性能提升。
3.3 BridgeLayer的数量
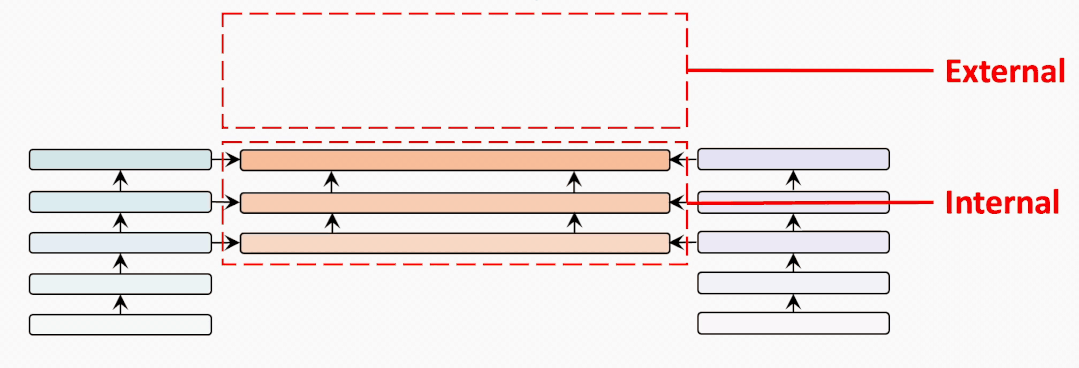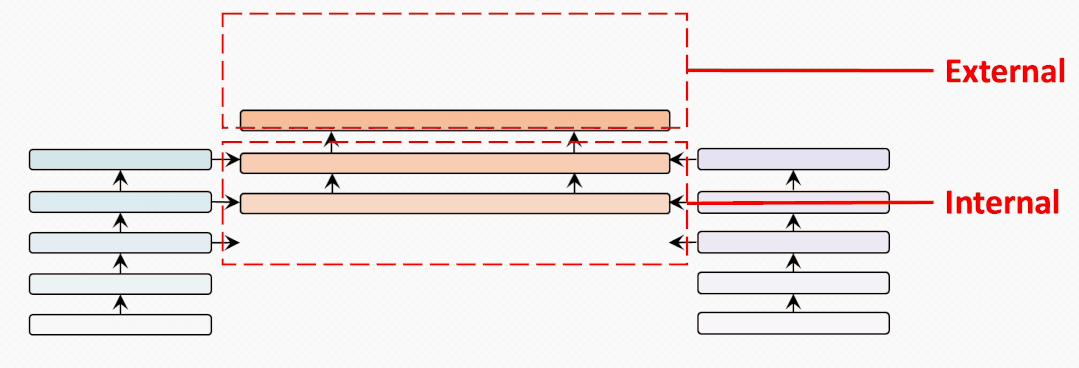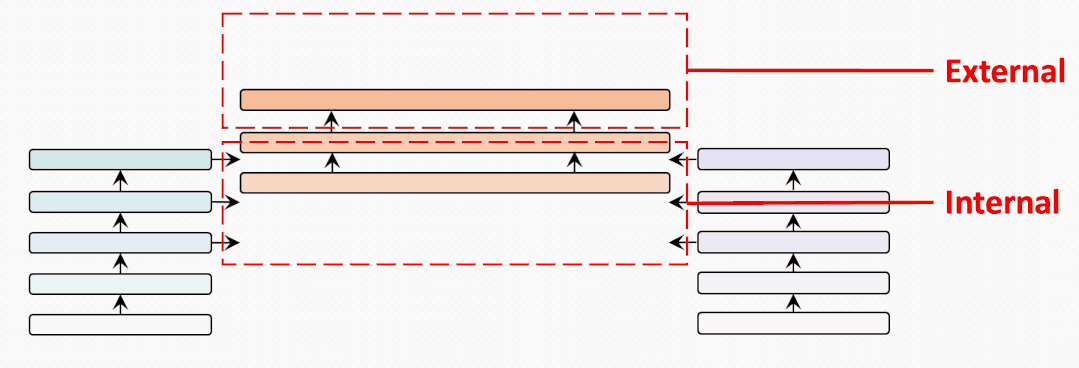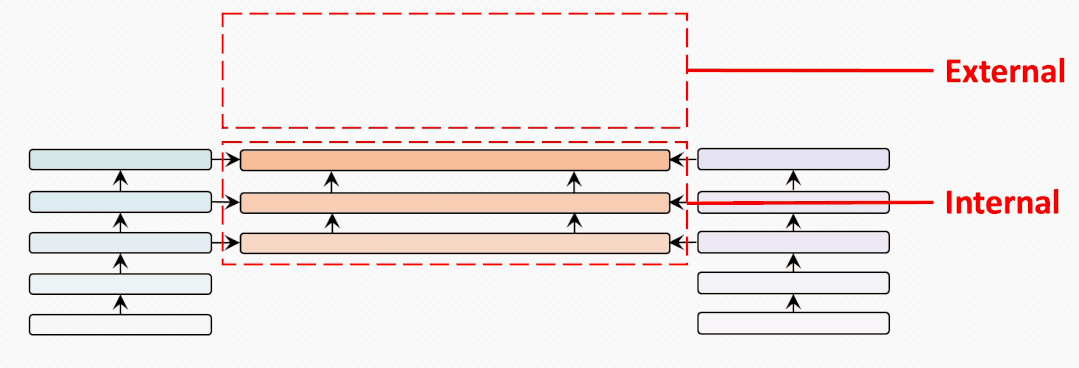
internal-external
最后是BridgeLayer的数量,也就是在使用相同数量的跨模态层时,应该加入多少个BridgeLayer。

为了充分比较BridgeTower和双塔结构的METER模型,我们试图建立一个从BridgeTower到Two-Tower逐渐变化的情景。为了进行公平的比较,我们使用共计6个跨模态层,并将它们分为外部 (External) 跨模态层和内部 (Internal) 跨模态层。二者的区别在于内部跨模态层具有BridgeLayer,而外部跨模态层没有。
第一行显示了6个跨模态层均为内部层的BridgeTower的结果。然后,我们逐渐增加外部层,减少内部层。我们发现在两个数据集上的性能都出现了稳定的下降。
最后一行显示了双塔结构的METER模型的性能。这表明BridgeTower通过BridgeLayers,将单模态编码器的顶层与跨模态编码器的每一层连接起来,可以显著提高性能。
3.4 单模态编码器
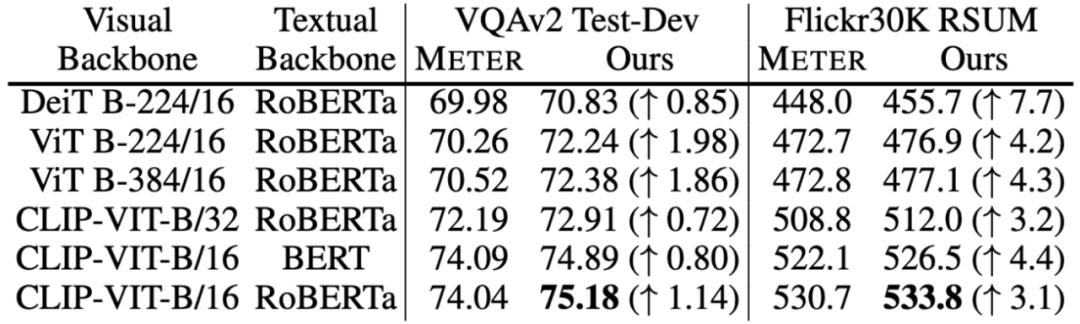
最后我们尝试了不同的视觉和文本编码器作为BridgeTower的预训练单模态编码器,并直接对下游任务进行微调,以进一步研究BridgeLayers带来的影响。我们发现,对于不同的预训练视觉和文本编码器,BridgeTower的性能都持续且显著地优于METER的性能。
4. 实验效果

我们基于公共图文对数据集对BridgeTower进行预训练,如上表所示,大约共计400万张独立图片,900万对图文对。我们使用通用的掩码语言建模 (Masked Language Modeling, MLM) 和图文匹配 (Image-Text Matching, ITM) 任务作为预训练任务。所有的预训练设置与预训练参数都与METER一致,以提供METER和BridgeTower之间的公平比较。
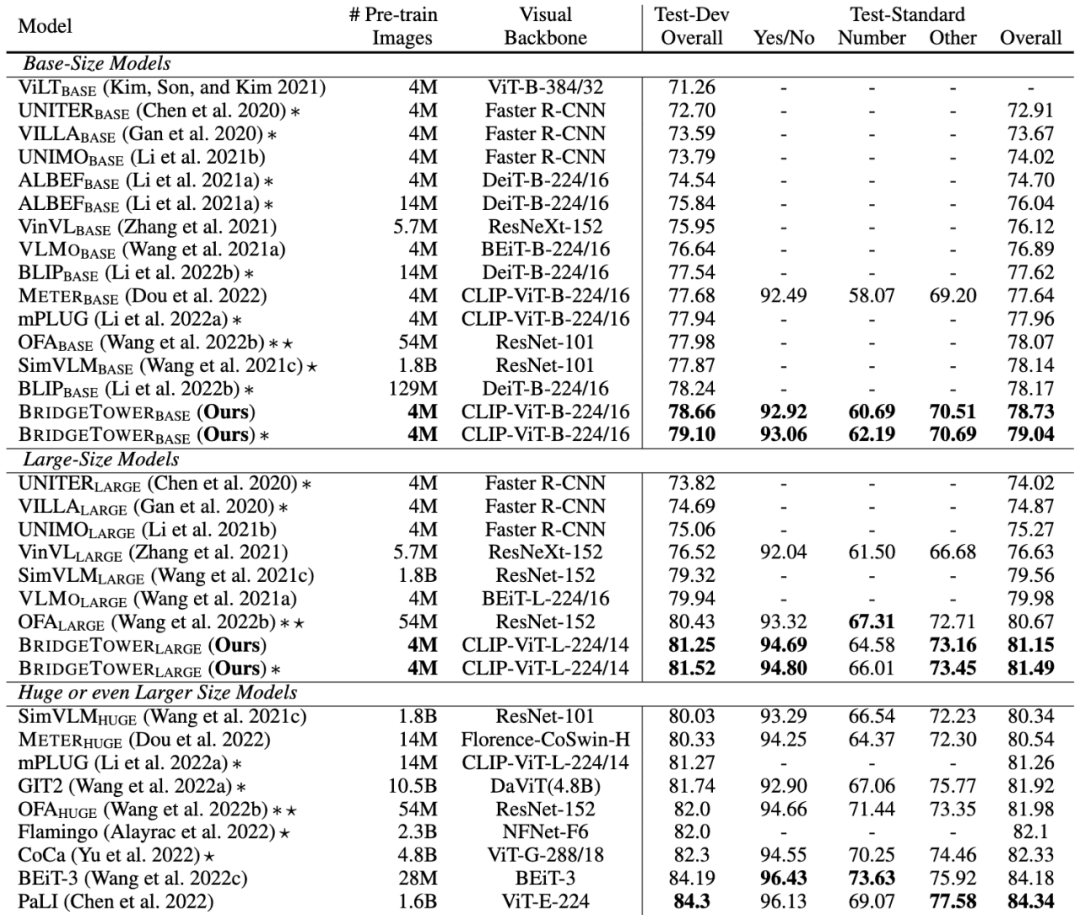
上图展示了BridgeTower模型在视觉问答 (Visual Question Answering) 的VQAv2数据集上的Base和Large两种Size的模型性能。在视觉-语言预训练中,我们的Base模型只使用了400万张图片进行预训练,就在VQAv2基准上取得了令人印象深刻的表现。
而且,METER和BridgeTower使用相同的文本编码器、视觉编码器和跨模态融合机制。只需将METER模型的Two-Tower架构改为BridgeTower架构,在相同的预训练数据和几乎可以忽略不计的额外参数和计算成本下,VQAv2数据集的Test-Standard性能就可以轻松提高1.09。BridgeTower的Large模型在VQAv2数据集上更是取得81.15的Test-Standard性能。
值得注意的是,BridgeTower超过了许多使用10倍甚至100倍的图像进行VL预训练的Base模型与Large模型,击败了许多用更多数据和参数进行预训练的强大模型。
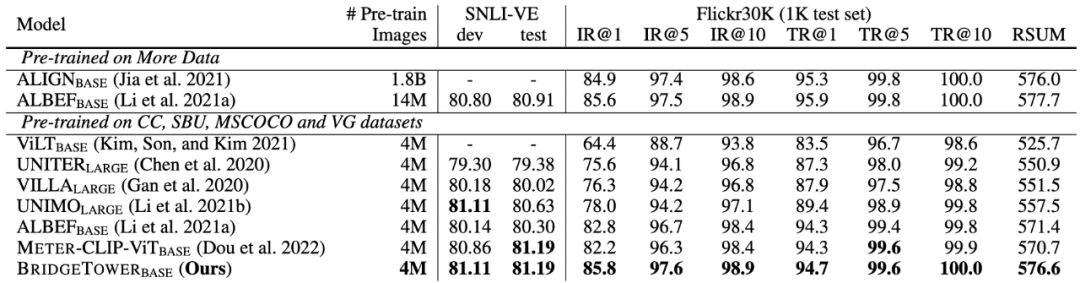
类似的趋势也出现在视觉蕴含 (Visual Entailment) 和图像-文本检索 (Image-Text Retrieval) 任务中。特别是在Flickr30K数据集上,BridgeTower的Base模型带来了5.9点收益。
5. 可视化结果
为了进一步研究性能提高的原因,我们通过分析每个跨模态层中,不同注意力头的注意力权重分布之间的KL散度,来比较双塔架构的METER模型和我们的BridgeTower架构。
KL散度可以被看作是注意力头的多样性。较高或较低的KL散度表示不同的注意力头之间,关注的token更加不同或更加相似。
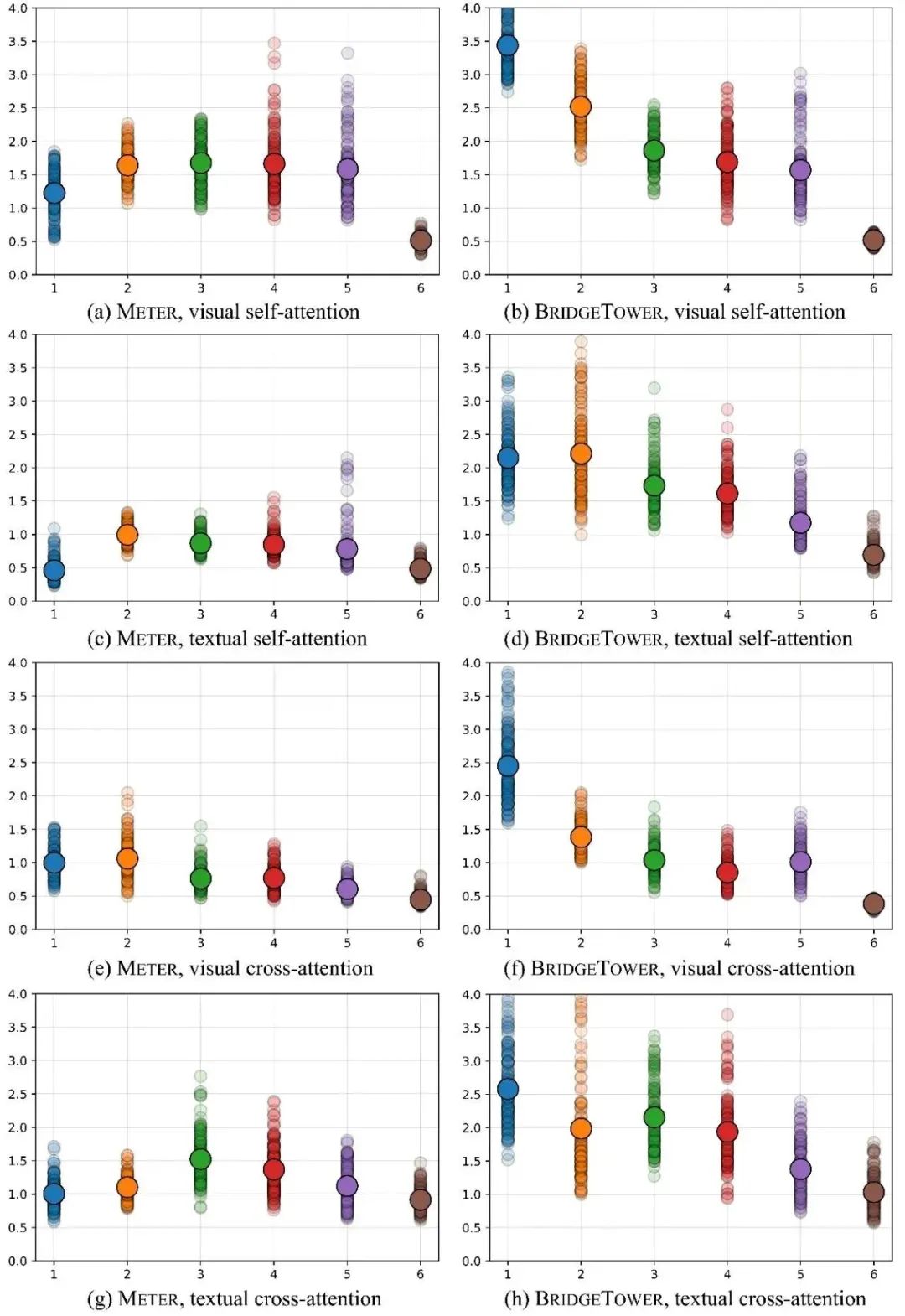
图中的小点代表不同注意力头的注意力分布间的KL散度,大点表示同层KL散度的均值。上图对比了METER和BridgeTower模型的跨模态编码器中,视觉/文本部分的自我/交叉注意力层之间的区别。
上图展示了两个模型的跨模态编码器的视觉和文本部分的自注意力以及交叉注意力的注意力头的多样性。图中存在两个明显的趋势:
对于BridgeTower来说,注意力头的多样性随着层的深入而逐渐变小,但对于METER来说,注意力头的多样性随着层的深入而逐渐变大,然后变小。
BridgeTower每层的注意力头的多样性明显大于METER,尤其是第1层至第5层。
因此,对于跨模态编码器的视觉和文本部分的自注意力以及交叉注意力的不同注意力头,与METER相比,BridgeTower能够关注到更多不同的标记 (token)。
我们将此归功于我们提出的BridgeLayers,它将单模态编码器的顶层与跨模态编码器的每一层连接起来。不同语义层次的视觉和文本表示通过BridgeLayer与跨模态表示进行融合,从而促进了跨模态编码器每一层的更有效和更丰富的跨模态对齐和融合。
6. 结论
在本文中,我们提出了BridgeTower,它引入了多个BridgeLayer,在单模态编码器的顶层和跨模态编码器的每一层之间建立连接。这使得预训练单模态编码器中的不同语义层次的视觉和文本表示,通过BridgeLayer与跨模态表示进行融合,从而促进了跨模态编码器中,高效的,自下而上的跨模态对齐与融合。
仅使用400万张图像进行视觉语言预训练,BridgeTower在各种下游的视觉-语言任务中取得了非常强大的性能。特别是在VQAv2数据集上,BridgeTower达到了78.73%的准确率,在相同的预训练数据和几乎可以忽略不计的额外参数和计算成本下,比Two-Tower架构的METER模型高出了1.09%的准确率。值得注意的是,当进一步扩展该模型时,BridgeTower达到了81.15%的准确率,甚至超过了一些在更大数量级的数据集上使用更多参数进行预训练的强大模型。
审核编辑:刘清
-
编码器
+关注
关注
45文章
3646浏览量
134691
原文标题:AAAI2023 | BridgeTower: 在视觉语言表示学习中建立编码器间的桥梁
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何选择合适的磁编码器 磁编码器在机器人技术中的角色
电机控制系统中的编码器概述与作用
AGV轮毂电机中的编码器







 工商网监
工商网监
评论