 【嵌入式AI简报20230414】黑芝麻智能7nm中央计算芯片正式发布、微软开源“傻瓜式”类ChatGPT模型训练工具
【嵌入式AI简报20230414】黑芝麻智能7nm中央计算芯片正式发布、微软开源“傻瓜式”类ChatGPT模型训练工具
嵌入式 AI
AI 简报 20230414 期
1. 黑芝麻智能7nm中央计算芯片正式发布,单芯片实现智能汽车跨域融合
原文:https://mp.weixin.qq.com/s/s-oDcsvKmwDx81E8LL1quw
在智能网联概念的推动下,智能汽车的发展已经从域控逐渐过渡到域融合,并继续向着中央集成去迈进。架构的变化对作为系统核心的计算芯片也提出了新的要求,为了帮助汽车产业更好地应对未来的智能汽车需求,在4月7日举办的“芯所向 至未来 BEST TECH Day 2023”黑芝麻智能战略发布暨生态合作伙伴大会上,该公司正式发布首个车规级跨域计算平台——武当系列,以及系列中首款产品C1200芯片。
武当系列面向架构创新
当前,汽车行业的发展可以说是日新月异,正在经历前所未有之大变局,机会迎面而来,而机会也稍纵即逝。黑芝麻智能创始人兼CEO单记章表示,黑芝麻智能要做改变人类出行方式的芯片,用人工智能、感知技术、核心芯片去改变汽车行业。

“经过长达24个月的艰苦研发,我们向行业正式推出黑芝麻智能全新的产品线——武当系列,主打跨域计算。”他在介绍中提到,“目前,行业对于L3及以下级别自动驾驶的算力需求比较清晰,黑芝麻智能A1000芯片已经能够很好地支持前融合BEV算法。面向未来,华山系列仍将继续探索更高级别自动驾驶对算力的清晰需求,而武当系列则关注跨域融合向中央计算架构的转变,通过架构创新,提升智能汽车的整体性能。”
黑芝麻智能产品副总裁丁丁在会上对武当系列和C1200进行了全面的介绍。他谈到,智车时代,汽车行业将会有四大新需求,分别是架构创新、算力综合、车规安全和平台化方案。那么,作为智车时代的车载计算方案,就需要能够支持七大类算力需求,依次是通用逻辑、图形渲染、音频音效、数学计算、实时控制、人工智能和数据处理。
为了解决未来的行业需求和算力需求,黑芝麻智能的武当系列芯片具有四大典型优势——新、准、强、高。
“新”是指创新的架构融合。武当系列通过异构隔离技术,把不同算力根据不同场景,以及不同规格和安全要求,进行搭配组合,能够支撑汽车电子电气架构的灵活发展,支持双脑、舱驾、中央计算等各种架构方案。
“准”是指准确的市场定位。如上所述,黑芝麻智能武当系列精准服务于海量的L2+级别融合计算市场,通过单芯片支持跨域融合的方式,力求在这一市场给下游客户带来高赋能价值、成本最优、系统最优的解决方案。
“强”是指强大的家族化平台。武当系列基于当前行业最先进的平台架构,其中C1200选择的是7nm工艺,领先的工艺保证了芯片的算力、功耗、成本能够达到更好的平衡。同时,黑芝麻智能在软硬件结合上提供SDK配套方案,满足客户各场景需求,节省开发时间,以及后续的长期维护代价。因此,黑芝麻智能不仅芯片是家族化规划,软件平台同样如此,确保了客户软件资产能够得到最好的继承。
“高”是指满足最高车规要求。丁丁在介绍时指出,黑芝麻智能三代车规级芯片,每一代都一次性流片成功,持续为客户提供高可靠性+高功能性安全+高信息安全的方案体验。武当系列在上一代芯片平台的基础上进一步优化了设计,可提供行业最高标准的Safety和Security能力。
智能汽车跨域计算平台C1200
C1200是武当系列的首款产品,基于7nm计算平台,内部搭载支持锁步的车规级高性能CPU 核A78AE(性能高达150KDMIPS),和车规级高性能GPU核G78AE,提供强大的通用计算和通用渲染算力。C1200提供丰富的片上资源,包括黑芝麻智能自研DynamAI NN车规级低功耗神经网络加速引擎,新一代自研多功能NeuralIQ ISP模块,高性能HIFI DSP,支持多组锁步的MCU算力,支持17MP高清摄像头的MIPI等。

并且,丁丁强调,C1200还提供丰富的接口资源,比如支持处理多路CAN数据的接入和转发,支持以太网接口并支持所有常用的显示接口格式,支持双通道的LPDDR5内存,等等。
在异构隔离技术的赋能下,黑芝麻智能C1200芯片开创性地实现了硬隔离独立计算子系统,独立渲染,独立显示,满足仪表控制屏的高安全性和快速启动的要求。同时,该子系统也可以灵活应用于自动驾驶、HUD抬头显示等需要独立系统的计算场景。
当然,C1200芯片领先行业的安全性也需要特别指出。该芯片内置支持ASIL-D等级的Safety Island和国密二级和EVITA full的Security模块,并满足车规安全等级最高的可靠性要求。
基于这些领先性能,C1200单芯片支持跨域计算多种场景,包括CMS(电子后视镜)系统、行泊一体、智能大灯、整车计算、信息娱乐系统、智能座舱、舱内感知系统等。
综上所述,黑芝麻智能C1200将在跨域融合方面带来极致的性价比。丁丁指出,目前基于C1200的原型机已经准备就绪,将在2023年内提供样片。

黑芝麻智能定位全面升级
除了C1200单芯片支持智能汽车跨域融合以外,黑芝麻智能也是行业内首个提出单芯片支持行泊一体方案的公司。几天前,该公司刚刚宣布实现能够实现支持10V(摄像头)NOA功能的行泊一体域控制器BOM成本控制在3000元人民币以内,支持50-100T物理算力。
单记章指出,2023年汽车行业面临着非常大的降价压力,成本压力也会传导到上游的供应链。在自动驾驶方案上,合理的算力+高性能+高性价比将成为市场主流。50T左右的物理算力能够支持L2+、L2++级别的自动驾驶已经成为市场的标准配置。
同时,会场外也展示出了基于黑芝麻智能芯片的丰富方案,来自该公司自己以及行业合作伙伴。这些具有颠覆性创新方案的背后是黑芝麻智能企业定位的升级。单记章表示,黑芝麻智能已经从“自动驾驶计算芯片的引领者”升级为“智能汽车计算芯片的引领者”。
他在演讲中提到黑芝麻智能战略定位的三步走计划:
-
第一步:聚焦自动驾驶计算芯片及解决方案,实现产品的商业化落地,形成完整的技术闭环;
-
第二步:根据汽车电子电气架构的发展趋势,拓展产品线覆盖到车内更多的计算节点,形成多产线的组合;
-
第三步:不断扩充产品线覆盖更多汽车的需求,为客户提供基于我们芯片的多种汽车软硬件解决方案。
单记章在会上呼吁:“中国市场已经开始逐渐走出一条属于自己的自动驾驶技术路线,我们欢迎友商和合作伙伴光明正大地竞争和合作,这样中国自动驾驶行业才能够良性发展。”
后记
大会上,黑芝麻智能还发布了“华山开发者计划”,并邀请到来自长安汽车、东风汽车和亿咖通等公司的顶级行业专家进行技术分享。可以看出,伴随着黑芝麻智能企业定位的升级,不仅是软硬件方面会更加丰富,生态同样在日益壮大。在坚持颠覆式创新之路上,黑芝麻智能路越走越远,路也越走越宽。
2. 无需写代码能力,手搓最简单BabyGPT模型:前特斯拉AI总监新作
原文:https://mp.weixin.qq.com/s/BBRBjH-y4hG8AoN2SfMyrw
我们知道,OpenAI 的 GPT 系列通过大规模和预训练的方式打开了人工智能的新时代,然而对于大多数研究者来说,语言大模型(LLM)因为体量和算力需求而显得高不可攀。在技术向上发展的同时,人们也一直在探索「最简」的 GPT 模式。
近日,特斯拉前 AI 总监,刚刚回归 OpenAI 的 Andrej Karpathy 介绍了一种最简 GPT 的玩法,或许能为更多人了解这种流行 AI 模型背后的技术带来帮助。
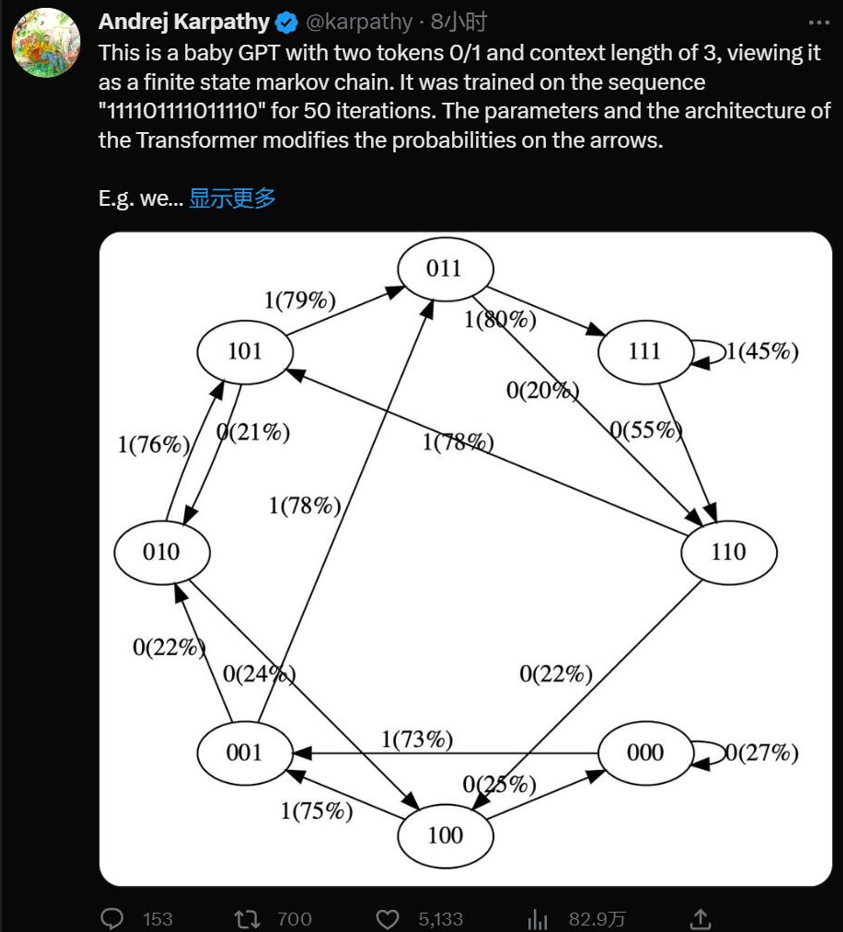
是的,这是一个带有两个 token 0/1 和上下文长度为 3 的极简 GPT,将其视为有限状态马尔可夫链。它在序列「111101111011110」上训练了 50 次迭代,Transformer 的参数和架构修改了箭头上的概率。
例如我们可以看到:
-
在训练数据中,状态 101 确定性地转换为 011,因此该转换的概率变得更高 (79%)。但不接近于 100%,因为这里只做了 50 步优化。
-
状态 111 以 50% 的概率分别进入 111 和 110,模型几乎已学会了(45%、55%)。
-
在训练期间从未遇到过像 000 这样的状态,但具有相对尖锐的转换概率,例如 73% 转到 001。这是 Transformer 归纳偏差的结果。你可能会想这是 50%,除了在实际部署中几乎每个输入序列都是唯一的,而不是逐字地出现在训练数据中。
通过简化,Karpathy 已让 GPT 模型变得易于可视化,让你可以直观地了解整个系统。
你可以在这里尝试它:
https://colab.research.google.com/drive/1SiF0KZJp75rUeetKOWqpsA8clmHP6jMg?usp=sharing
实际上,即使是 GPT 的最初版本,模型的体量很相当可观:在 2018 年,OpenAI 发布了第一代 GPT 模型,从论文《Improving Language Understanding by Generative Pre-Training》可以了解到,其采用了 12 层的 Transformer Decoder 结构,使用约 5GB 无监督文本数据进行训练。
但如果将其概念简化,GPT 是一种神经网络,它采用一些离散 token 序列并预测序列中下一个 token 的概率。例如,如果只有两个标记 0 和 1,那么一个很小的二进制 GPT 可以例如告诉我们:
1[0,1,0]--->GPT--->[P(0)=20%,P(1)=80%]
在这里,GPT 采用位序列 [0,1,0],并根据当前的参数设置,预测下一个为 1 的可能性为 80%。重要的是,默认情况下 GPT 的上下文长度是有限的。如果上下文长度为 3,那么它们在输入时最多只能使用 3 个 token。在上面的例子中,如果我们抛出一枚有偏差的硬币并采样 1 确实应该是下一个,那么我们将从原始状态 [0,1,0] 转换到新状态 [1,0,1]。我们在右侧添加了新位 (1),并通过丢弃最左边的位 (0) 将序列截断为上下文长度 3,然后可以一遍又一遍地重复这个过程以在状态之间转换。
很明显,GPT 是一个有限状态马尔可夫链:有一组有限的状态和它们之间的概率转移箭头。每个状态都由 GPT 输入处 token 的特定设置定义(例如 [0,1,0])。我们可以以一定的概率将其转换到新状态,如 [1,0,1]。让我们详细看看它是如何工作的:
1#hyperparametersforourGPT#vocabsizeis2,soweonlyhavetwopossibletokens:0,1vocab_size=2#contextlengthis3,sowetake3bitstopredictthenextbitprobabilitycontext_length=3
GPT 神经网络的输入是长度为 context_length 的 token 序列。这些 token 是离散的,因此状态空间很简单:
1print('statespace(forthisexercise)=',vocab_size**context_length)#statespace(forthisexercise)=8
细节:准确来说,GPT 可以采用从 1 到 context_length 的任意数量的 token。因此如果上下文长度为 3,原则上我们可以在尝试预测下一个 token 时输入 1 个、2 个或 3 个 token。这里我们忽略这一点并假设上下文长度已「最大化」,只是为了简化下面的一些代码,但这一点值得牢记。
1print('actualstatespace(inreality)=',sum(vocab_size**iforiinrange(1,context_length+1)))#actualstatespace(inreality)=14
我们现在要在 PyTorch 中定义一个 GPT。出于本笔记本的目的,你无需理解任何此代码。
现在让我们构建 GPT 吧:
1config=GPTConfig(block_size=context_length,vocab_size=vocab_size,n_layer=4,n_head=4,n_embd=16,bias=False,)gpt=GPT(config)
对于这个笔记本你不必担心 n_layer、n_head、n_embd、bias,这些只是实现 GPT 的 Transformer 神经网络的一些超参数。
GPT 的参数(12656 个)是随机初始化的,它们参数化了状态之间的转移概率。如果你平滑地更改这些参数,就会平滑地影响状态之间的转换概率。
现在让我们试一试随机初始化的 GPT。让我们获取上下文长度为 3 的小型二进制 GPT 的所有可能输入:
1defall_possible(n,k):#returnallpossiblelistsofkelements,eachinrangeof[0,n)ifk==0:yield[]else:foriinrange(n):forcinall_possible(n,k-1):yield[i]+clist(all_possible(vocab_size,context_length))
2
1[[0,0,0],[0,0,1],[0,1,0],[0,1,1],[1,0,0],[1,0,1],[1,1,0],[1,1,1]]
这是 GPT 可能处于的 8 种可能状态。让我们对这些可能的标记序列中的每一个运行 GPT,并获取序列中下一个标记的概率,并绘制为可视化程度比较高的图形:
1#we'llusegraphvizforprettyplottingthecurrentstateoftheGPTfromgraphvizimportDigraph
2
3defplot_model():dot=Digraph(comment='BabyGPT',engine='circo')
4
5forxiinall_possible(gpt.config.vocab_size,gpt.config.block_size):
6#forwardtheGPTandgetprobabilitiesfornexttokenx=torch.tensor(xi,dtype=torch.long)[None,...]#turnthelistintoatorchtensorandaddabatchdimensionlogits=gpt(x)#forwardthegptneuralnetprobs=nn.functional.softmax(logits,dim=-1)#gettheprobabilitiesy=probs[0].tolist()#removethebatchdimensionandunpackthetensorintosimplelistprint(f"input{xi}--->{y}")
7
8#alsobuildupthetransitiongraphforplottinglatercurrent_node_signature="".join(str(d)fordinxi)dot.node(current_node_signature)fortinrange(gpt.config.vocab_size):next_node=xi[1:]+[t]#cropthecontextandappendthenextcharacternext_node_signature="".join(str(d)fordinnext_node)p=y[t]label=f"{t}({p*100:.0f}%)"dot.edge(current_node_signature,next_node_signature,label=label)
9returndot
10
11plot_model()
1input[0,0,0]--->[0.4963349997997284,0.5036649107933044]input[0,0,1]--->[0.4515703618526459,0.5484296679496765]input[0,1,0]--->[0.49648362398147583,0.5035163760185242]input[0,1,1]--->[0.45181113481521606,0.5481888651847839]input[1,0,0]--->[0.4961162209510803,0.5038837194442749]input[1,0,1]--->[0.4517717957496643,0.5482282042503357]input[1,1,0]--->[0.4962802827358246,0.5037197470664978]input[1,1,1]--->[0.4520467519760132,0.5479532480239868]
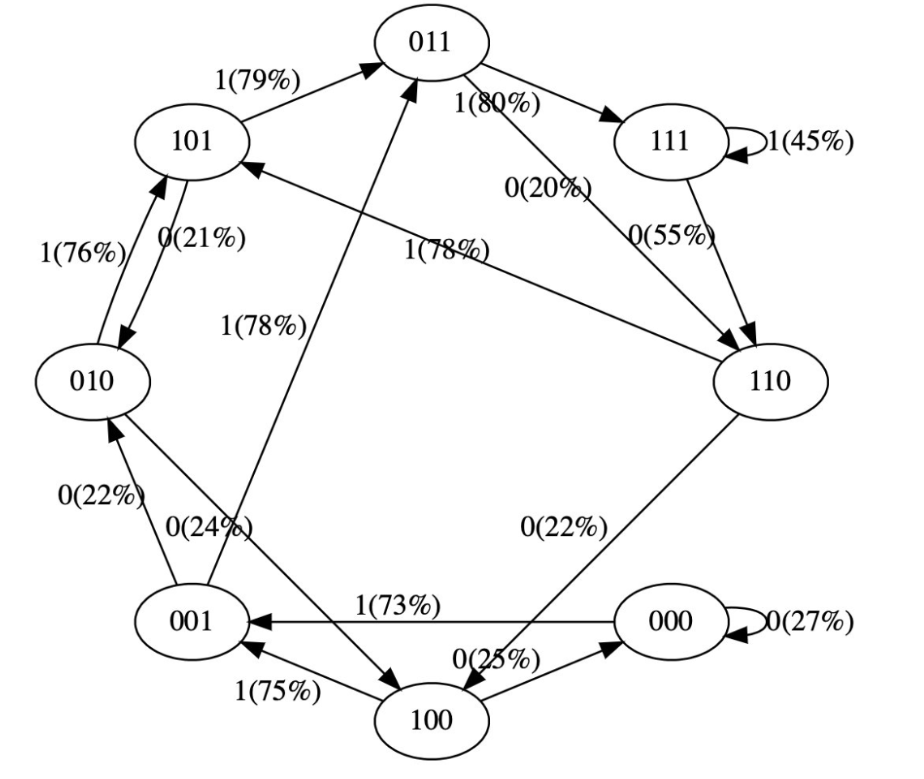
我们看到了 8 个状态,以及连接它们的概率箭头。因为有 2 个可能的标记,所以每个节点有 2 个可能的箭头。请注意,在初始化时,这些概率中的大多数都是统一的(在本例中为 50%),这很好而且很理想,因为我们甚至根本没有训练模型。
下面开始训练:
1#let'strainourbabyGPTonthissequenceseq=list(map(int,"111101111011110"))seq
1[1,1,1,1,0,1,1,1,1,0,1,1,1,1,0]
1#convertthesequencetoatensorholdingalltheindividualexamplesinthatsequenceX,Y=[],[]#iterateoverthesequenceandgrabeveryconsecutive3bits#thecorrectlabelforwhat'snextisthenextbitateachpositionforiinrange(len(seq)-context_length):X.append(seq[i:i+context_length])Y.append(seq[i+context_length])print(f"example{i+1:2d}:{X[-1]}-->{Y[-1]}")X=torch.tensor(X,dtype=torch.long)Y=torch.tensor(Y,dtype=torch.long)print(X.shape,Y.shape)
我们可以看到在那个序列中有 12 个示例。现在让我们训练它:
1#initaGPTandtheoptimizertorch.manual_seed(1337)gpt=GPT(config)optimizer=torch.optim.AdamW(gpt.parameters(),lr=1e-3,weight_decay=1e-1)
1#traintheGPTforsomenumberofiterationsforiinrange(50):logits=gpt(X)loss=F.cross_entropy(logits,Y)loss.backward()optimizer.step()optimizer.zero_grad()print(i,loss.item())
1print("Trainingdatasequence,asareminder:",seq)plot_model()我们没有得到这些箭头的准确 100% 或 50% 的概率,因为网络没有经过充分训练,但如果继续训练,你会期望接近。
请注意一些其他有趣的事情:一些从未出现在训练数据中的状态(例如 000 或 100)对于接下来应该出现的 token 有很大的概率。如果在训练期间从未遇到过这些状态,它们的出站箭头不应该是 50% 左右吗?这看起来是个错误,但实际上是可取的,因为在部署期间的真实应用场景中,几乎每个 GPT 的测试输入都是训练期间从未见过的输入。我们依靠 GPT 的内部结构(及其「归纳偏差」)来适当地执行泛化。
大小比较:
-
GPT-2 有 50257 个 token 和 2048 个 token 的上下文长度。所以 `log2 (50,257) * 2048 = 每个状态 31,984 位 = 3,998 kB。这足以实现量变。
-
GPT-3 的上下文长度为 4096,因此需要 8kB 的内存;大约相当于 Atari 800。
-
GPT-4 最多 32K 个 token,所以大约 64kB,即 Commodore64。
-
I/O 设备:一旦开始包含连接到外部世界的输入设备,所有有限状态机分析就会崩溃。在 GPT 领域,这将是任何一种外部工具的使用,例如必应搜索能够运行检索查询以获取外部信息并将其合并为输入。
Andrej Karpathy 是 OpenAI 的创始成员和研究科学家。但在 OpenAI 成立一年多后,Karpathy 便接受了马斯克的邀请,加入了特斯拉。在特斯拉工作的五年里,他一手促成了 Autopilot 的开发。这项技术对于特斯拉的完全自动驾驶系统 FSD 至关重要,也是马斯克针对 Model S、Cybertruck 等车型的卖点之一。
今年 2 月,在 ChatGPT 火热的背景下,Karpathy 回归 OpenAI,立志构建现实世界的 JARVIS 系统。
英伟达人工智能科学家 Jim Fan 表示:「对于 Meta 的这项研究,我认为是计算机视觉领域的 GPT-3 时刻之一。它已经了解了物体的一般概念,即使对于未知对象、不熟悉的场景(例如水下图像)和模棱两可的情况下也能进行很好的图像分割。最重要的是,模型和数据都是开源的。恕我直言,Segment-Anything 已经把所有事情(分割)都做的很好了。」
3. CV开启大模型时代!谷歌发布史上最大ViT:220亿参数,视觉感知力直逼人类
原文:https://mp.weixin.qq.com/s/lWgA5JiBhUYAzeGvgqE_mg
Transformer无疑是促进自然语言处理领域繁荣的最大功臣,也是GPT-4等大规模语言模型的基础架构。
不过相比语言模型动辄成千上万亿的参数量,计算机视觉领域吃到Transformer的红利就没那么多了,目前最大的视觉Transformer模型ViT-e的参数量还只有40亿参数。
最近谷歌发布了一篇论文,研究人员提出了一种能够高效且稳定训练大规模Vision Transformers(ViT)模型的方法,成功将ViT的参数量提升到220亿。

论文链接:https://arxiv.org/abs/2302.05442
为了实现模型的扩展,ViT-22B结合了其他语言模型(如PaLM模型)的思路,使用 QK 归一化改进了训练稳定性,提出了一种异步并行线性操作(asynchronous parallel linear operations) 的新方法提升训练效率,并且能够在硬件效率更高的Cloud TPU上进行训练。
在对ViT-22B模型进行实验以评估下游任务性能时,ViT-22B也表现出类似大规模语言模型的能力,即随着模型规模的扩大,性能也在不断提升。
ViT-22B 还可以应用于PaLM-e中,与语言模型结合后的大模型可以显著提升机器人任务的技术水平。
研究人员还进一步观察到规模带来的其他优势,包括更好地平衡公平性和性能,在形状/纹理偏见方面与人类视觉感知的一致性,以及更好的稳健性。
模型架构
ViT-22B 是一个基于Transformer架构的模型,和原版ViT架构相比,研究人员主要做了三处修改以提升训练效率和训练稳定性。
并行层(parallel layers)
ViT-22B并行执行注意力块和MLP块,而在原版Transformer中为顺序执行。
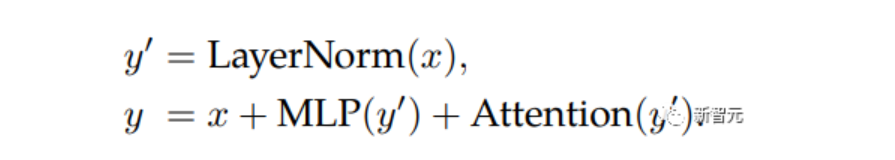
PaLM模型的训练也采用了这种方法,可以将大模型的训练速度提高15%,并且性能没有下降。
query/key (QK) normalization
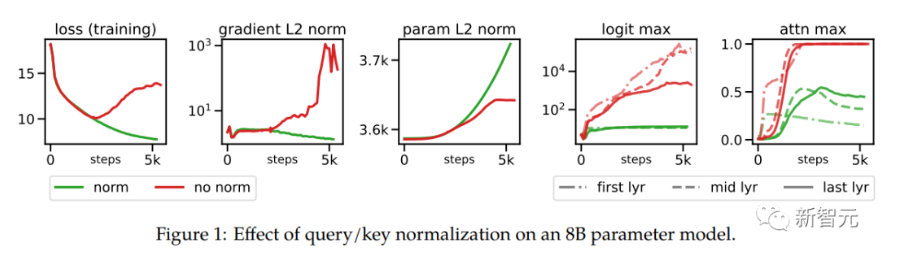
在扩展ViT的过程中,研究人员在80亿参数量的模型中观察到,在训练几千步之后训练损失开始发散(divergence),主要是由于注意力logits的数值过大引起的不稳定性,导致零熵的注意力权重(几乎one-hot)。
为了解决这个问题,研究人员在点乘注意力计算之前对Query和Key使用LayerNorm
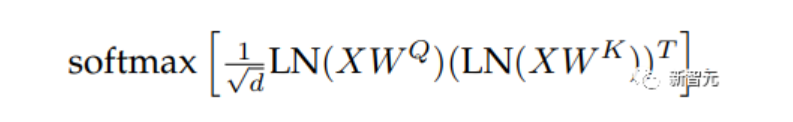
在80亿参数模型上的实验结果如下图所示,归一化可以缓解发散问题。
删除QKV投影和LayerNorms上的偏置项
和PaLM模型一样,ViT-22B从QKV投影中删除了偏置项,并且在所有LayerNorms中都没有偏置项(bias)和centering,使得硬件利用率提高了3%,并且质量没有下降。
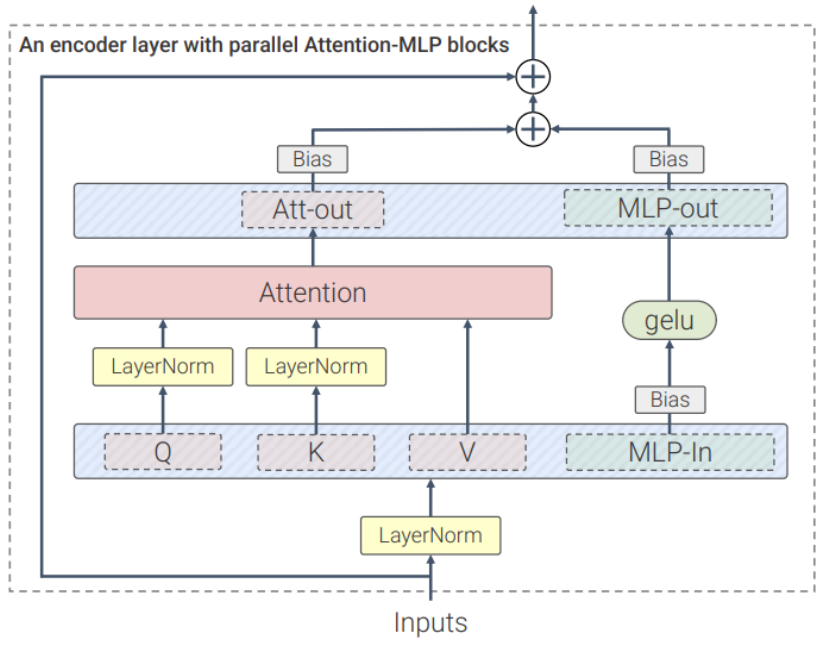
不过与PaLM不同的是,ViT-22B对(内部和外部)MLP稠密连接层使用了偏置项,可以观察到质量得到了改善,并且速度也没有下降。
ViT-22B的编码器模块中,嵌入层,包括抽取patches、线性投影和额外的位置嵌入都与原始ViT中使用的相同,并且使用多头注意力pooling来聚合每个头中的per-token表征。
ViT-22B的patch尺寸为14×14,图像的分辨率为224×224(通过inception crop和随机水平翻转进行预处理)。
异步并联线性运算(asynchronous parallel linear operations)
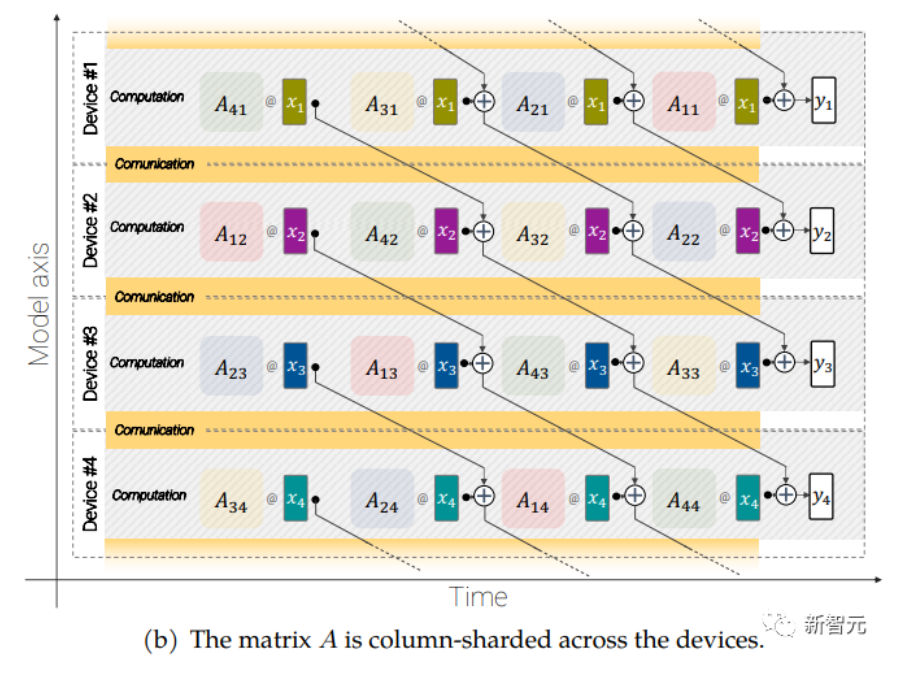
大规模的模型还需要分片(sharding),即将模型参数分布在不同的计算设备中,除此之外,研究人员还把激活(acctivations,输入的中间表征)也进行分片。
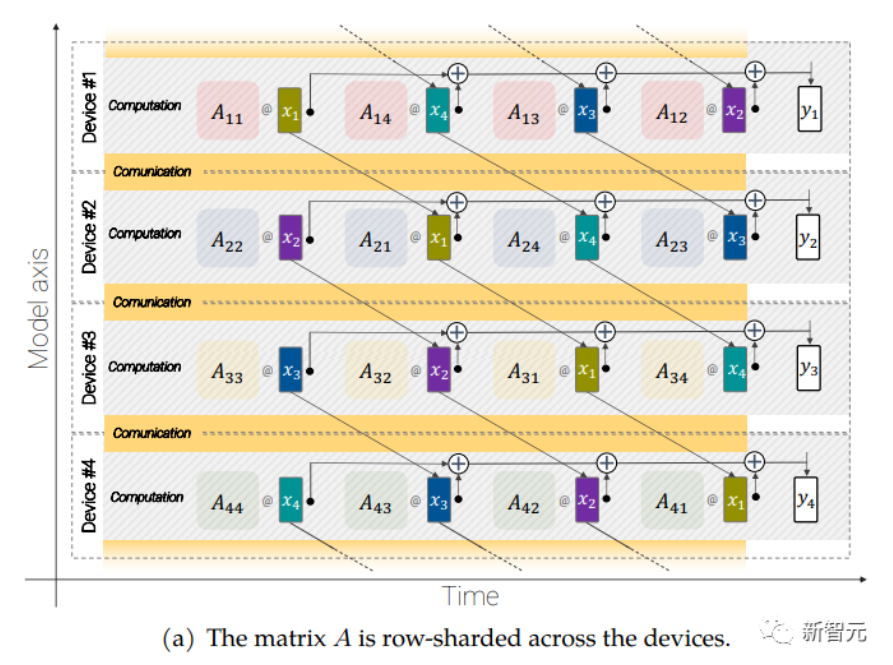
因为输入和矩阵本身都是分布在各种设备上的,即使是像矩阵乘法这样简单的操作也需要特别小心。
研究人员开发了一种称为异步并行线性运算的方法,可以在矩阵乘法单元(在TPU 中占据绝大多数计算能力的单元)中计算时,同时对设备之间的激活和权值进行通信。
异步方法最小化了等待传入通信的时间,从而提高了设备效率。
异步并行线性运算的目标是计算矩阵乘法 y = Ax,但矩阵 A 和激活 x 都分布在不同的设备上,需要通过跨设备的重叠通信和计算来实现这一点。矩阵 A 在设备之间进行列分片(column-shard),每个矩阵包含一个连续的切片,每个块表示为 Aij,更多细节请看原始论文。
实验结果
为了说明ViT-22B学习到的表征非常丰富,研究人员使用LiT-tuning训练一个文本模型来生成一些表征用来对齐文本和图像。
下面是用Parti 和 Imagen 生成的分布外(out-of-distribution)图像得到的实验结果,可以看到ViT-22B的zero-shot图像分类泛化能力非常强,仅从web上爬取的自然图像就能识别出没见过的物体和场景。
论文中还讨论了ViT-22B在视频分类、深度估计和语义分割任务上的效果。
结论
研究人员提出了一个目前最大的视觉Transformer模型 ViT-22B,包含220亿参数。
通过对原始模型架构进行微小但关键的修改后,实现了更高的硬件利用率和训练稳定性,从而得到了一个在几个基准测试上提高了模型的上限性能。
使用冻结模型生成嵌入,只需要在顶部训练几层,即可获得很好的性能,并且评估结果进一步表明,与现有模型相比,ViT-22B 在形状和纹理偏差方面显示出与人类视知觉更多的相似性,并且在公平性和稳健性方面提供了优势。
4. 计算机视觉中的图像标注工具总结
原文:https://mp.weixin.qq.com/s/ggxVzo4pEjRP5Jn0zzb0Fg
labelme
地址:https://github.com/wkentaro/labelme
你可以用它做什么
labelme 是一个基于 python 的开源图像多边形标注工具,可用于手动标注图像以进行对象检测、分割和分类。它是在线 LabelMe 的离线分支,最近关闭了新用户注册选项。所以,在这篇文章中,我们只考虑 labelme(小写)。
该工具是具有直观用户界面的轻量级图形应用程序。使用 labelme,您可以创建:多边形、矩形、圆、线、点或线带。通常,能够以众所周知的格式(例如 COCO、YOLO 或 PASCAL VOL)导出注释以供后续使用通常很方便。但是,在 labelme 中,标签只能直接从应用程序保存为 JSON 文件。如果要使用其他格式,可以使用 labelme 存储库中的 Python 脚本将注释转换为 PASCAL VOL。尽管如此,它还是一个相当可靠的应用程序,具有用于手动图像标记和广泛的计算机视觉任务的简单功能。
安装和配置
labelme 是一个跨平台的应用程序,可以在多个系统上工作,例如 Windows、Ubuntu 或 macOS。安装本身非常简单,这里有很好的描述。例如,在 macOS 上,您需要在终端中运行以下命令:
-
安装依赖:brew install pyqt
-
安装labelme:pip install labelme
-
运行 labelme:labelme
labelImg
地址:https://github.com/tzutalin/labelImg
你可以用它做什么
labelImg 是一种广泛使用的开源图形注释工具。它仅适用于目标定位或检测任务,并且只能在考虑的对象周围创建矩形框。尽管存在这种限制,我们还是建议使用此工具,因为该应用程序仅专注于创建尽可能简化工具的边界框。对于此任务,labelImg 具有所有必要的功能和方便的键盘快捷键。另一个优点是您可以以 3 种流行的注释格式保存/加载注释:PASCAL VOC、YOLO 和 CreateML。
安装和配置
这里对安装进行了很好的描述。还要注意 labelImg 是一个跨平台的应用程序。例如,对于 MacOS,需要在命令行上执行以下操作:
-
安装依赖:先 brew install qt,然后 brew install libxml2
-
选择要安装的文件夹的位置。
-
当你在文件夹中时,运行以下命令:git clone https://github.com/tzutalin/labelImg.git, cd labelImg 然后 make qt5py3
-
运行 labelImg:python3 labelImg.py
-
开发人员强烈建议使用 Python 3 或更高版本和 PyQt5。
CVAT
地址:https://github.com/openvinotoolkit/cvat
你可以用它做什么
CVAT 是一种用于图像和视频的开源注释工具,用于对象检测、分割和分类等任务。要使用此工具,您无需在计算机上安装该应用程序。可以在线使用此工具的网络版本。您可以作为一个团队协作处理标记图像并在用户之间分配工作。还有一个很好的选择,它允许您使用预先训练的模型来自动标记您的数据,如果您使用 CVAT 仪表板中现有的可用模型,这可以简化最流行的类(例如,COCO 中包含的类)的过程。或者,您也可以使用自己的预训练模型。CVAT 具有我们已经考虑过的工具中最广泛的功能集。特别是,它允许您以大约 15 种不同的格式保存标签。可以在此处找到完整的格式列表。
hasty.ai
地址:https://hasty.ai/
你可以用它做什么
与上述所有工具不同,hasty.ai 不是免费的开源服务,但由于所谓的对象检测和分割的 AI 助手,它非常方便地标记数据。自动支持允许您显着加快注释过程,因为在标记期间辅助模型正在训练。换句话说,标记的图像越多,助手的工作就越准确。我们将在下面看一个例子来说明它是如何工作的。
您也可以免费试用此服务。该试验提供 3000 积分,足以为一个物体检测任务自动生成大约 3000 个物体的建议标签。
hasty.ai 允许您以 COCO 或 Pascal VOC 格式导出数据。您还可以作为一个团队处理单个项目并在项目设置中分配角色。
免费积分用完后,hasty.ai 仍然可以免费使用,但标记将完全由手动操作。在这种情况下,最好考虑上述免费工具。
配置
-
要使用该工具,您需要在 hasty.ai 上注册。
-
登录您的帐户。
-
单击创建新项目。
-
用名称和描述填写表单并导航到项目设置,您可以在其中定义考虑中的类,为该项目添加数据。
-
此外,您可以添加其他用户来共同处理项目。积分将从共享项目的用户的帐户中使用。
5. 微软开源“傻瓜式”类ChatGPT模型训练工具,成本大大降低,速度提升15倍
原文:https://mp.weixin.qq.com/s/t3HA4Hu61LLDC3h2Njmo_Q
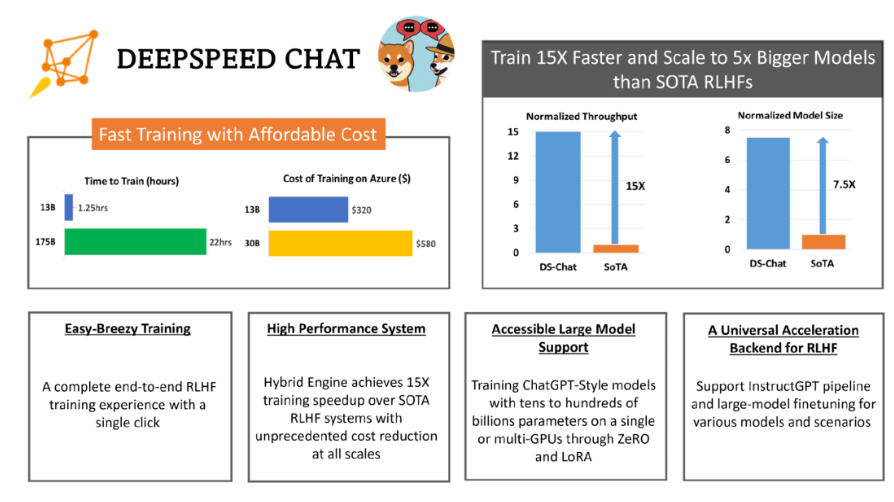
当地时间 4 月 12 日,微软宣布开源 DeepSpeed-Chat,帮助用户轻松训练类 ChatGPT 等大语言模型。
据悉,Deep Speed Chat 是基于微软 Deep Speed 深度学习优化库开发而成,具备训练、强化推理等功能,还使用了 RLHF(基于人类反馈的强化学习)技术,可将训练速度提升 15 倍以上,而成本却大大降低。
如下图,一个 130 亿参数的类 ChatGPT 模型,训练时间只需要 1.25 小时。
简单来说,用户只需要通过 Deep Speed Chat 提供的 “傻瓜式” 操作,就能以最短的时间、最高效的成本训练类 ChatGPT 大语言模型。
使 RLHF 训练真正在 AI 社区普及
近来,ChatGPT 及类似模型引发了 AI 行业的一场风潮。ChatGPT 类模型能够执行归纳、编程、翻译等任务,其结果与人类专家相当甚至更优。为了能够使普通数据科学家和研究者能够更加轻松地训练和部署 ChatGPT 等模型,AI 开源社区进行了各种尝试,如 ChatLLaMa、ChatGLM-6B、Alpaca、Vicuna、Databricks-Dolly 等。
然而,目前业内依然缺乏一个支持端到端的基于人工反馈机制的强化学习(RLHF)的规模化系统,这使得训练强大的类 ChatGPT 模型十分困难。
例如,使用现有的开源系统训练一个具有 67 亿参数的类 ChatGPT 模型,通常需要昂贵的多卡至多节点的 GPU 集群,但这些资源对大多数数据科学家或研究者而言难以获取。同时,即使有了这样的计算资源,现有的开源系统的训练效率通常也达不到这些机器最大效率的 5%。
简而言之,即使有了昂贵的多 GPU 集群,现有解决方案也无法轻松、快速、经济的训练具有数千亿参数的最先进的类 ChatGPT 模型。
与常见的大语言模型的预训练和微调不同,ChatGPT 模型的训练基于 RLHF 技术,这使得现有深度学习系统在训练类 ChatGPT 模型时存在种种局限。
微软在 Deep Speed Chat 介绍文档中表示,“为了让 ChatGPT 类型的模型更容易被普通数据科学家和研究者使用,并使 RLHF 训练真正在 AI 社区普及,我们发布了 DeepSpeed-Chat。”
据介绍,为了实现无缝的训练体验,微软在 DeepSpeed-Chat 中整合了一个端到端的训练流程,包括以下三个主要步骤:
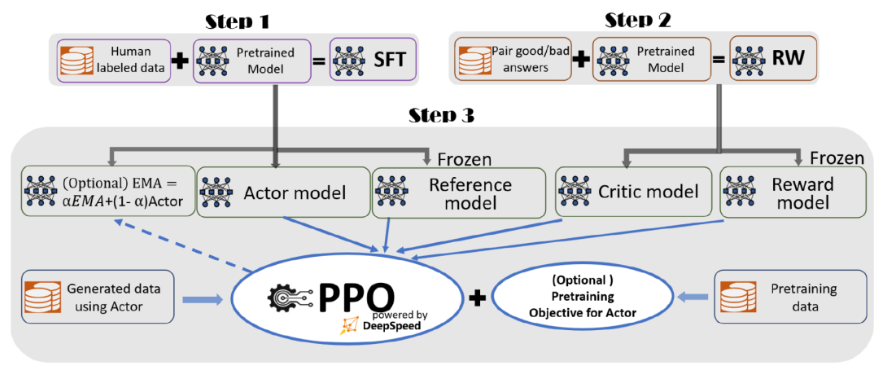
-
监督微调(SFT),使用精选的人类回答来微调预训练的语言模型以应对各种查询;
-
奖励模型微调,使用一个包含人类对同一查询的多个答案打分的数据集来训练一个独立的(通常比 SFT 小的)奖励模型(RW);
-
RLHF 训练,利用 Proximal Policy Optimization(PPO)算法,根据 RW 模型的奖励反馈进一步微调 SFT 模型。
在步骤 3 中,微软提供了指数移动平均(EMA)和混合训练两个额外的功能,以帮助提高模型质量。根据 InstructGPT,EMA 通常比传统的最终训练模型提供更好的响应质量,而混合训练可以帮助模型保持预训练基准解决能力。
总体来说,DeepSpeed-Chat 具有以下三大核心功能:
1.简化 ChatGPT 类型模型的训练和强化推理体验:只需一个脚本即可实现多个训练步骤,包括使用 Huggingface 预训练的模型、使用 DeepSpeed-RLHF 系统运行 InstructGPT 训练的所有三个步骤、甚至生成你自己的类 ChatGPT 模型。此外,微软还提供了一个易于使用的推理API,用于用户在模型训练后测试对话式交互。
2.DeepSpeed-RLHF 模块:DeepSpeed-RLHF 复刻了 InstructGPT 论文中的训练模式,并确保包括 SFT、奖励模型微调和 RLHF 在内的三个步骤与其一一对应。此外,微软还提供了数据抽象和混合功能,以支持用户使用多个不同来源的数据源进行训练。
3.DeepSpeed-RLHF 系统:微软将 DeepSpeed 的训练(training engine)和推理能力(inference engine) 整合到一个统一的混合引擎(DeepSpeed-HE)中用于 RLHF 训练。DeepSpeed-HE 能够在 RLHF 中无缝地在推理和训练模式之间切换,使其能够利用来自 DeepSpeed-Inference 的各种优化,如张量并行计算和高性能 CUDA 算子进行语言生成,同时对训练部分还能从 ZeRO- 和 LoRA-based 内存优化策略中受益。此外,DeepSpeed-HE 还能自动在 RLHF 的不同阶段进行智能的内存管理和数据缓存。
高效、经济、扩展性强
据介绍,DeepSpeed-RLHF 系统在大规模训练中具有出色的效率,使复杂的 RLHF 训练变得快速、经济并且易于大规模推广。
具体而言,DeepSpeed-HE 比现有系统快 15 倍以上,使 RLHF 训练快速且经济实惠。例如,DeepSpeed-HE 在 Azure 云上只需 9 小时即可训练一个 OPT-13B 模型,只需 18 小时即可训练一个 OPT-30B 模型。这两种训练分别花费不到 300 美元和 600 美元。
此外,DeepSpeed-HE 也具有卓越的扩展性,其能够支持训练拥有数千亿参数的模型,并在多节点多 GPU 系统上展现出卓越的扩展性。因此,即使是一个拥有 130 亿参数的模型,也只需 1.25 小时就能完成训练。而对于参数规模为 1750 亿的更大模型,使用 DeepSpeed-HE 进行训练也只需不到一天的时间。
另外,此次开源有望实现 RLHF 训练的普及化。微软表示,仅凭单个 GPU,DeepSpeed-HE 就能支持训练超过 130 亿参数的模型。这使得那些无法使用多 GPU 系统的数据科学家和研究者不仅能够轻松创建轻量级的 RLHF 模型,还能创建大型且功能强大的模型,以应对不同的使用场景。
那么,人手一个专属 ChatGPT 的时代,还有多远?
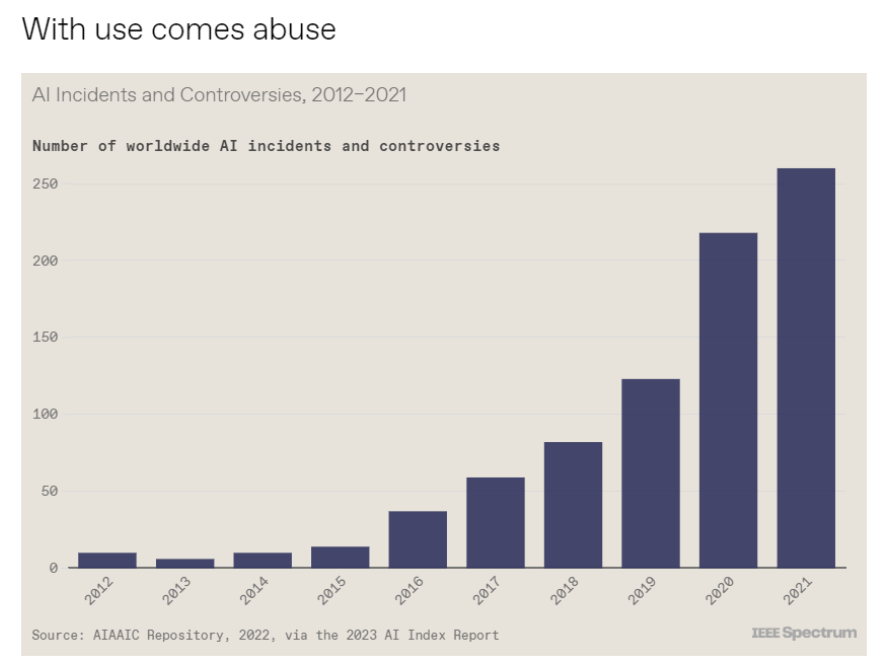
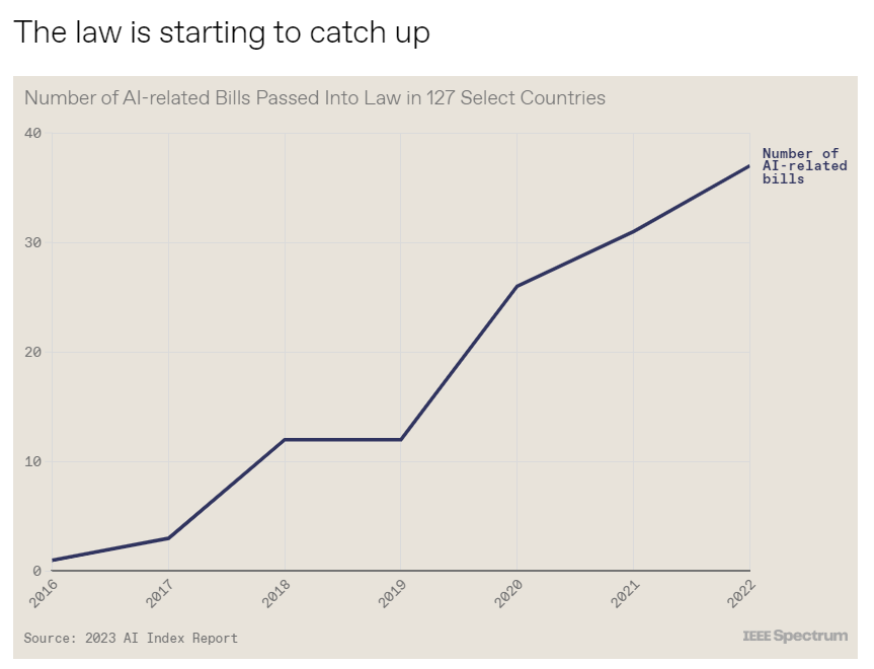
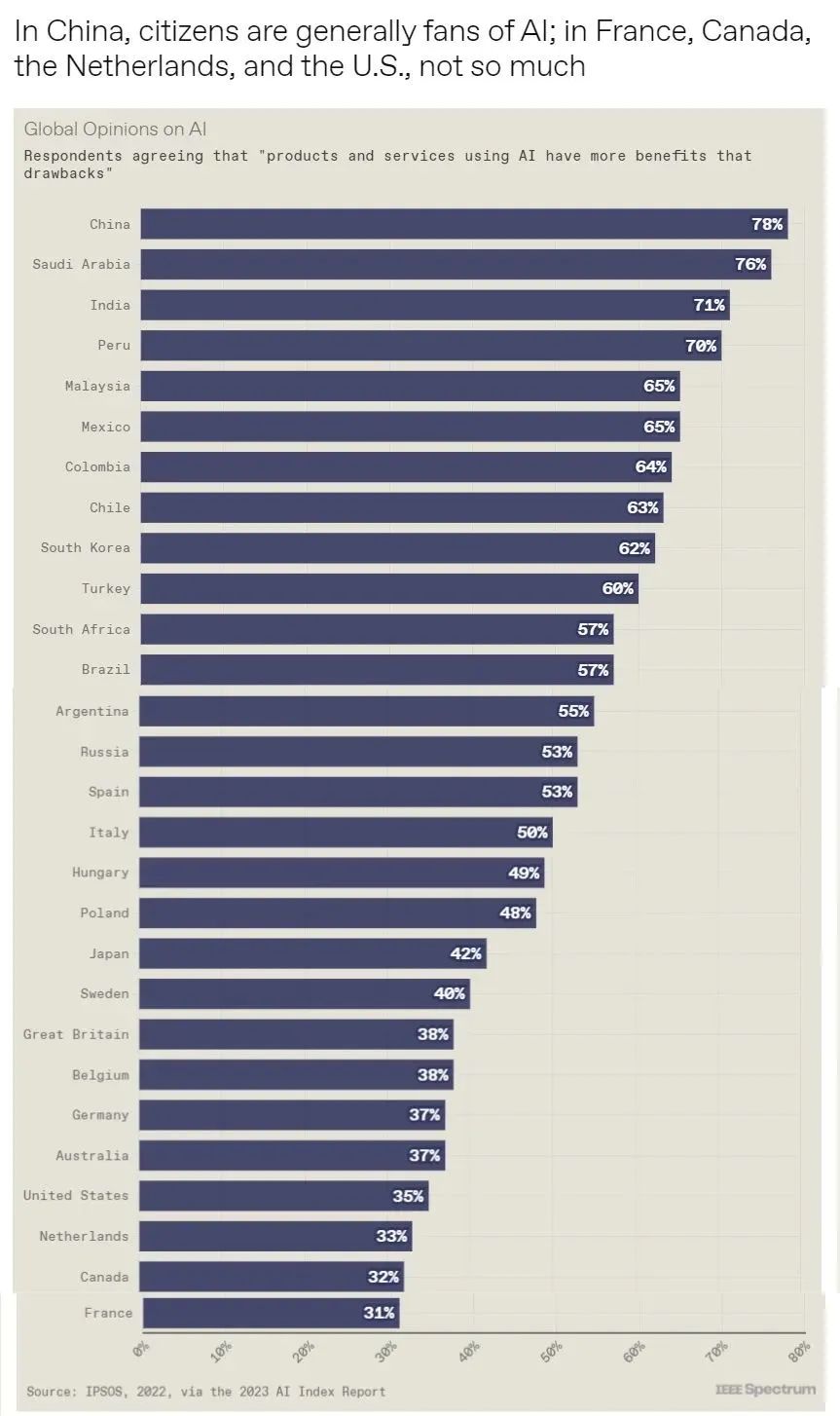
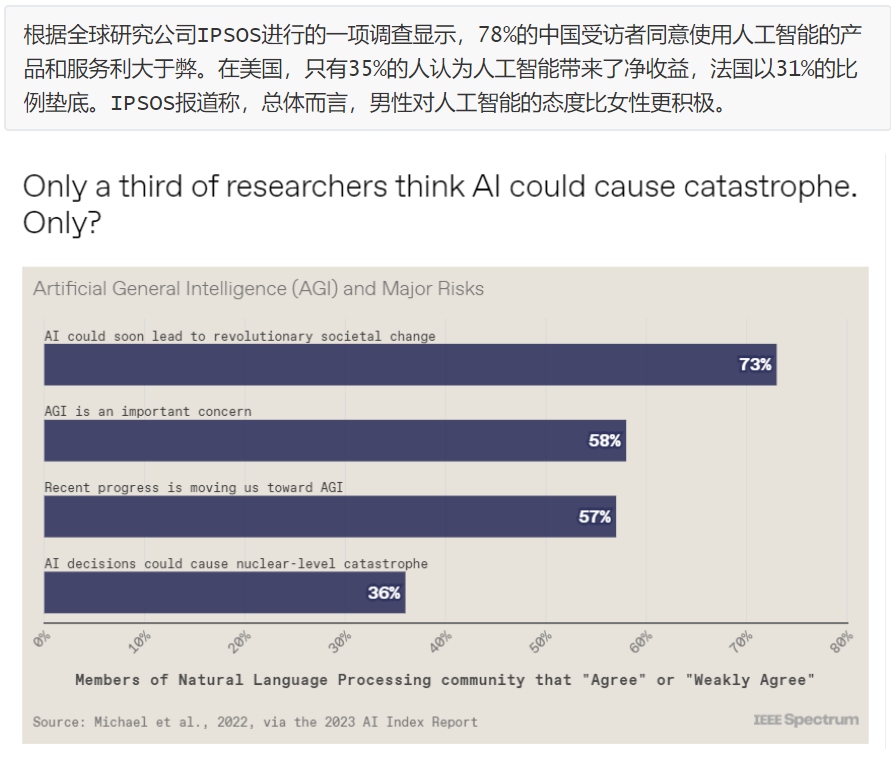
6. 10张图总结2023年人工智能状况
https://mp.weixin.qq.com/s/oKPPsfzKK8DbGg_vzaTRuQ
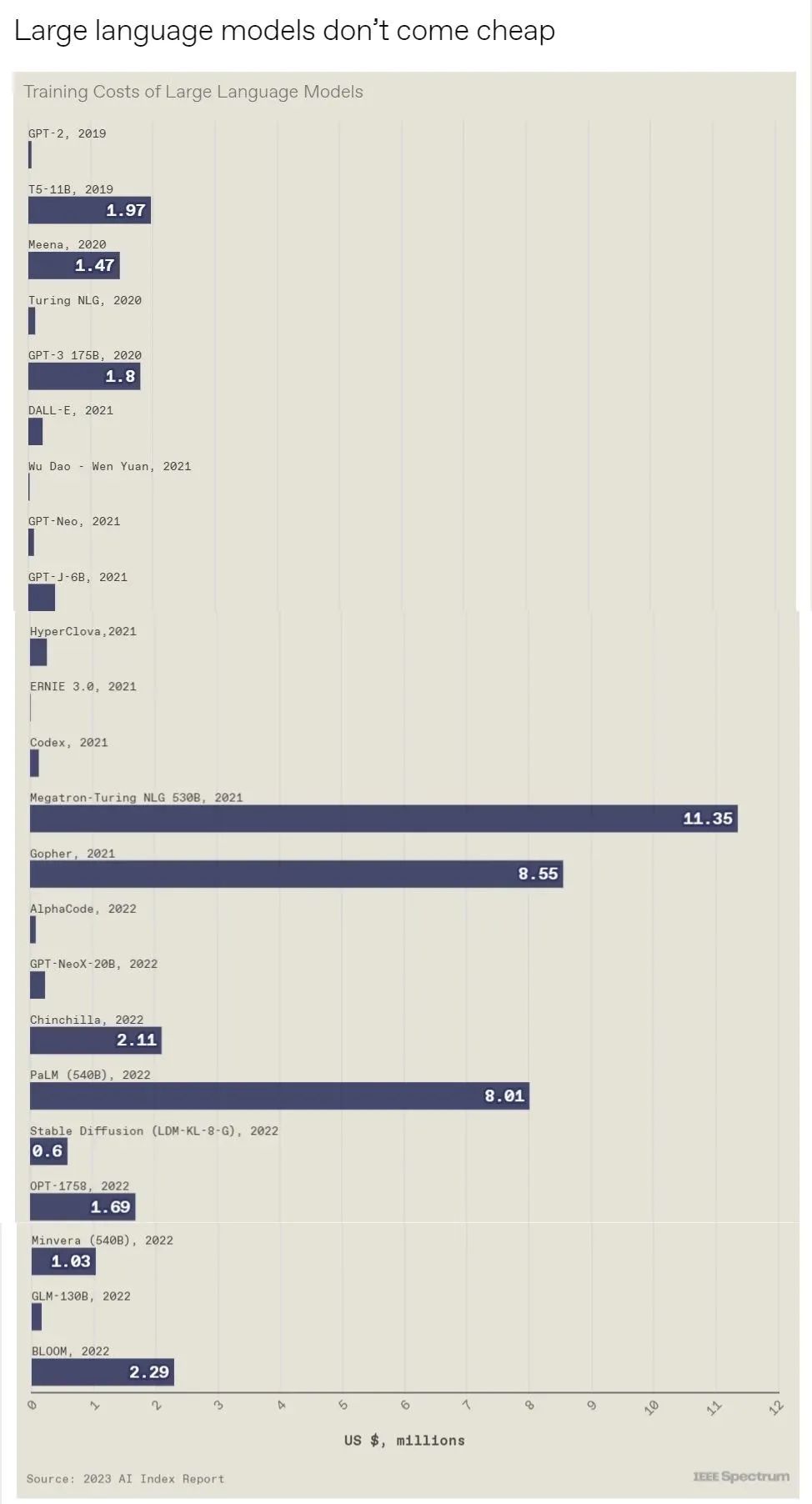
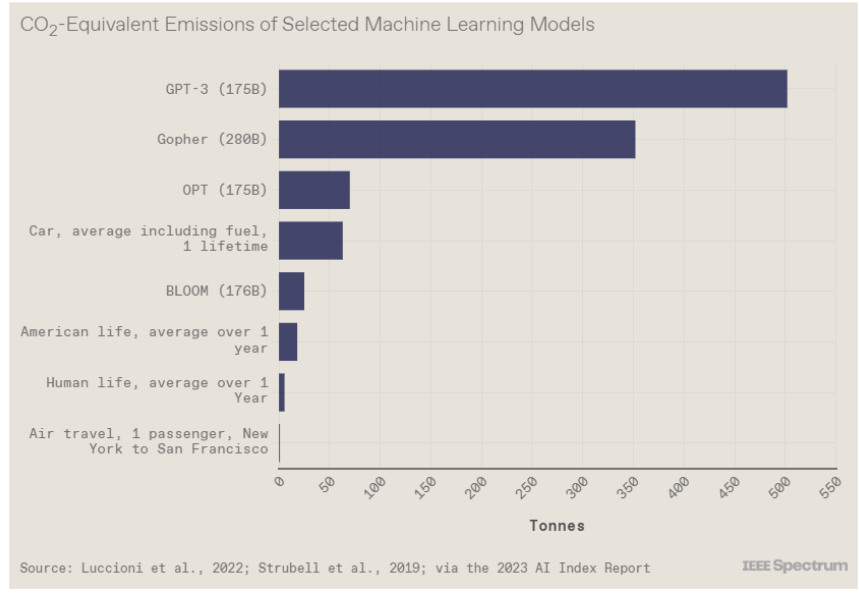
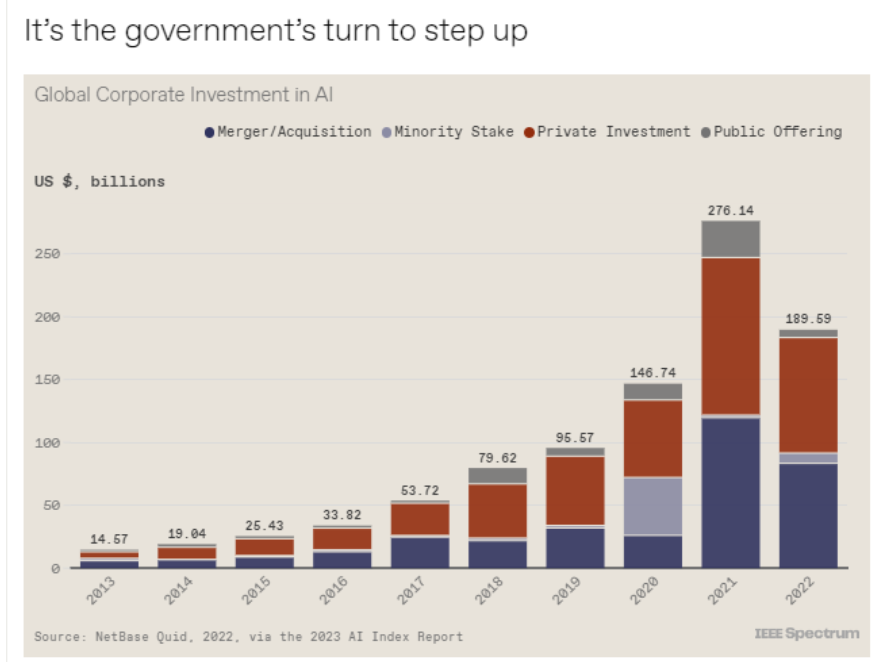
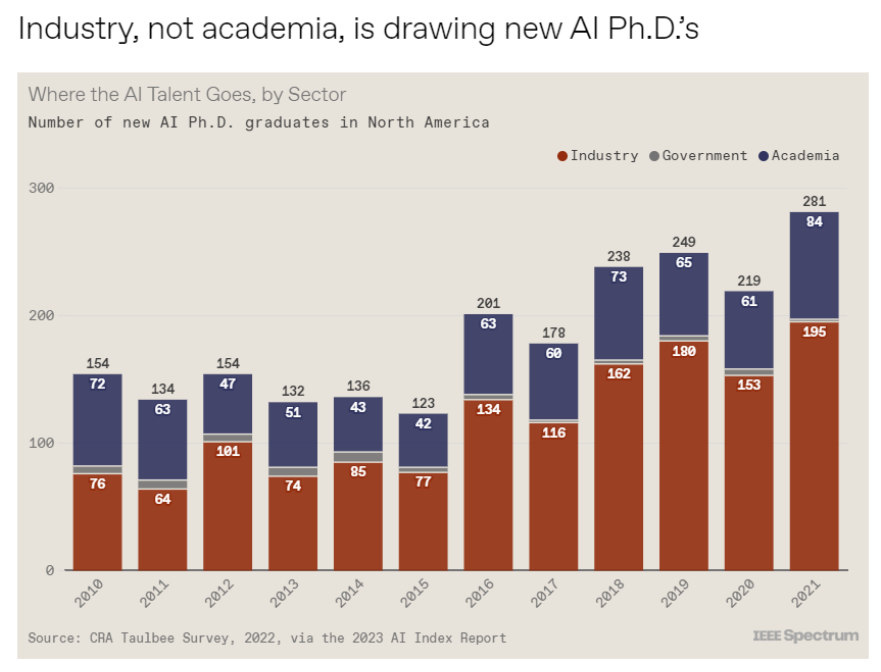
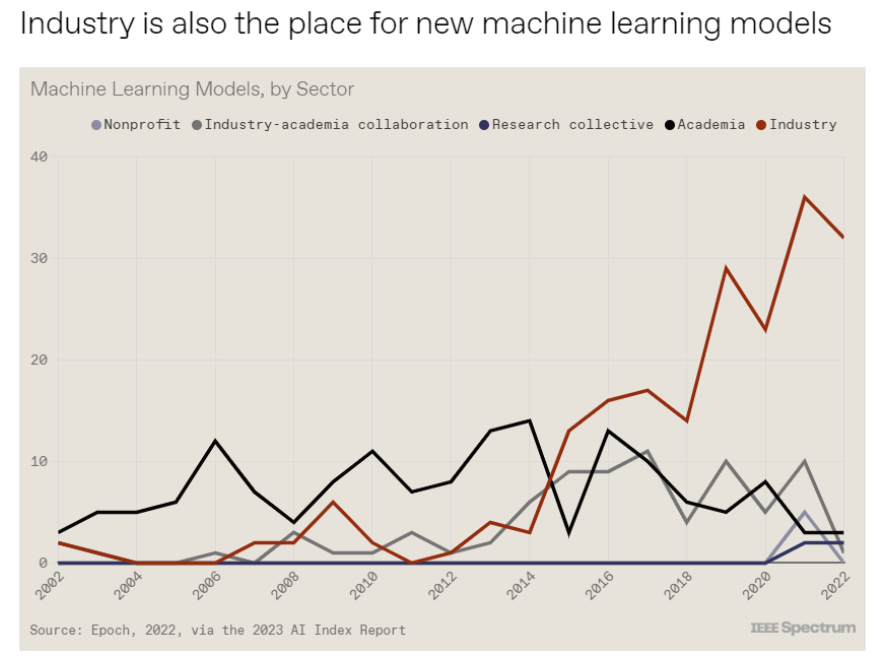
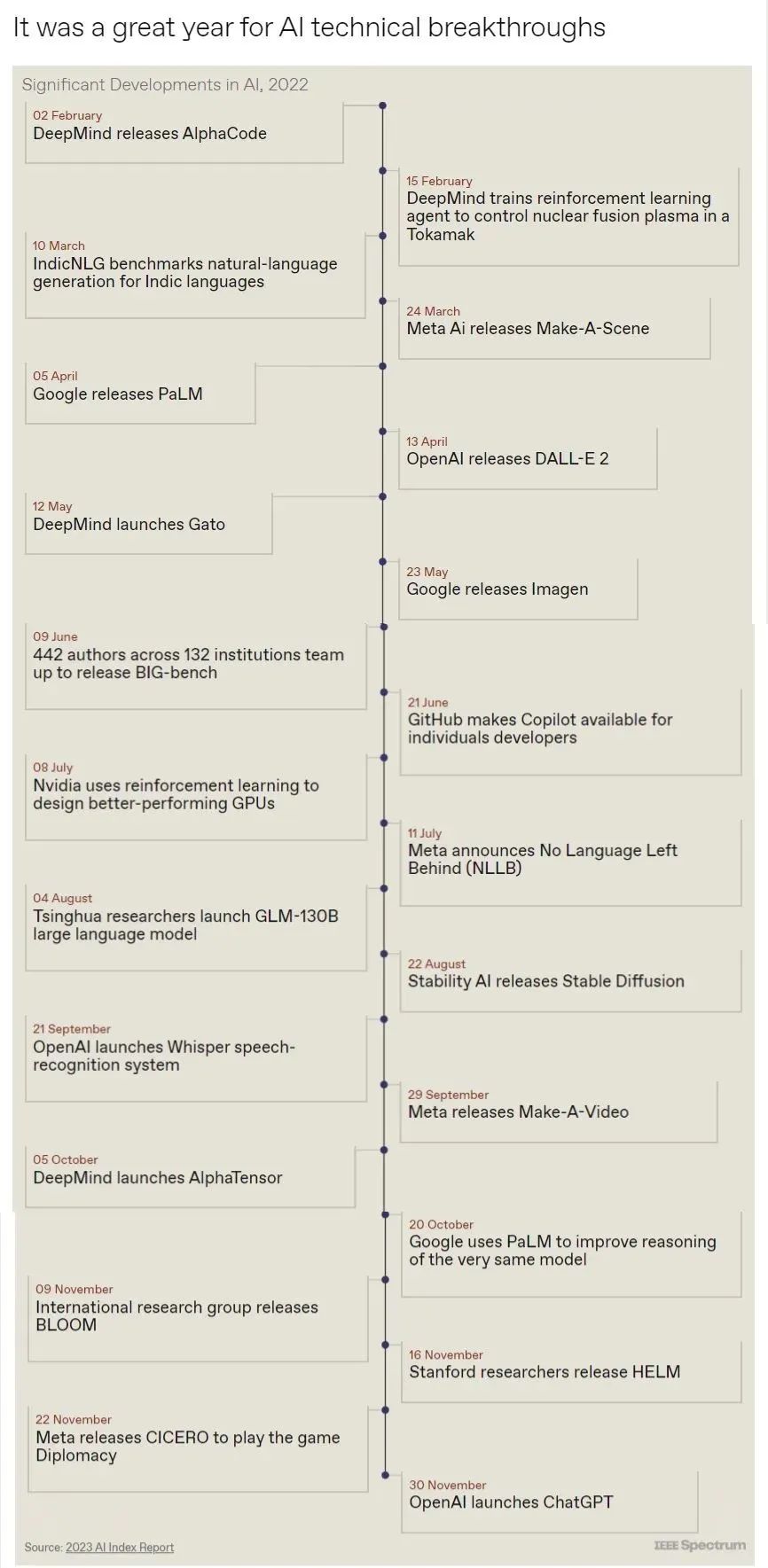
斯坦福大学以人为本人工智能研究所(Human-Centered AI Institute,HAI)收集了一年的人工智能数据(https://hai.stanford.edu/),提供了当今人工智能世界的全面情况。该报告自2017年起,由斯坦福大学开始主导研究。AI指数报告作为一项独立计划,每年发布AI指数年度报告,全面追踪人工智能的最新发展状态和趋势。今年的综合报告共有302页,这比2022年的报告增长了近60%。这在很大程度上要归功于2022年需求关注的生成性人工智能的蓬勃发展,以及收集人工智能和道德数据的努力越来越大。
对于那些像我(作者,以下简称我)一样渴望阅读整个《2023年人工智能指数报告》(https://aiindex.stanford.edu/report/)的人,你可以首先在这里进行了解。下面是10张图表,捕捉了当今人工智能的基本趋势。








———————End———————
RT-Thread线下入门培训-4月场次 青岛、北京
1.免费2.动手实验+理论3.主办方免费提供开发板4.自行携带电脑,及插线板用于笔记本电脑充电5.参与者需要有C语言、单片机(ARM Cortex-M核)基础,请提前安装好RT-Thread Studio 开发环境

立即扫码报名
报名链接
https://jinshuju.net/f/UYxS2k
巡回城市:青岛、北京、西安、成都、武汉、郑州、杭州、深圳、上海、南京
你可以添加微信:rtthread2020 为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!
点击阅读原文,进入RT-Thread 官网
原文标题:【嵌入式AI简报20230414】黑芝麻智能7nm中央计算芯片正式发布、微软开源“傻瓜式”类ChatGPT模型训练工具
-
RT-Thread
+关注
关注
31文章
1308浏览量
40495
原文标题:【嵌入式AI简报20230414】黑芝麻智能7nm中央计算芯片正式发布、微软开源“傻瓜式”类ChatGPT模型训练工具
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
黑芝麻智能芯片加速DeepSeek模型推理
黑芝麻智能芯片全面兼容DeepSeek模型推理
黑芝麻智能与RockAI联手发布AI Agent解决方案
黑芝麻智能与Nullmax联袂发布A2000多模态大模型智驾方案
黑芝麻智能与Elektrobit联手推出武当系列解决方案
黑芝麻智能与RockAI发布AI Agent解决方案
黑芝麻智能、NESINEXT、傅利叶联合发布“灵巧手”
开启全新AI时代 智能嵌入式系统快速发展——“第六届国产嵌入式操作系统技术与产业发展论坛”圆满结束
智能汽车AI芯片第一股黑芝麻智能在港交所挂牌上市
EVASH Ultra EEPROM:助力ChatGPT等AI应用的嵌入式存储解决方案
黑芝麻智能获国际最高安全标准认证
AI引爆边缘计算变革,塑造嵌入式产业新未来AI引爆边缘计算变革,塑造嵌入式产业新未来——2024研华嵌入式






 工商网监
工商网监
评论