 C/C++预处理命令的工作原理及分类
C/C++预处理命令的工作原理及分类
摘要:在C/C++语言编程过程中,经常会用到如#include、#define等指令,同时也会涉及到大量的预处理与条件编译,这样做的好处可以使代码更利于移植移植性,也让代码易于修改。 因此引入了预处理与条件编译的概念。
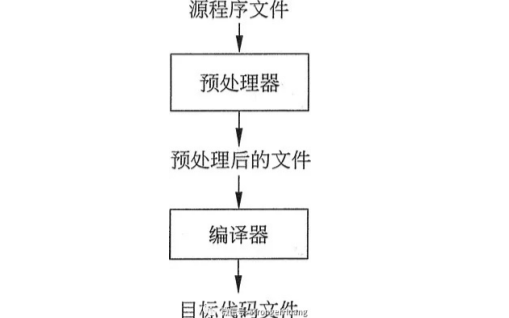
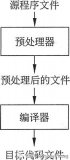
预处理的行为是由指令控制的。 所有的预处理器命令都是以#开头,它必须是第一个非空字符。 预处理指令由预处理程序(预处理器)操作。
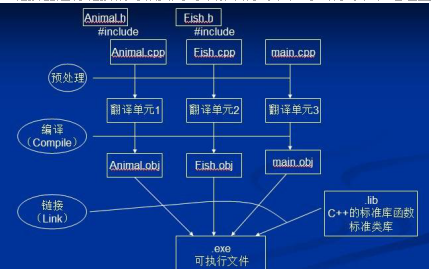
预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。 因此, 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。 通俗来讲预处理命令的作用就是在编译和链接之前,对源文件进行一些文本方面的操作,比如文本替换、文件包含、删除部分代码等,这个过程叫做预处理(在编译之前对源文件进行简单加工)
相比其他编程语言,C/C++语言更依赖预处理器,故在阅读或开发C/C++程序过程中,可能会接触大量的预处理指令。 预处理指令不属于C/C++语言的语法,但在一定意义上可以说预处理扩展了C/C++。 预处理命令的分类主要划分为以下几种类型:
1、宏定义
#define命令并不是真正的定义符号常量,而是定义一个可以替换的宏。 被定义为宏的标示符称为“宏名”。 在编译预处理过程时,对程序中所有出现的“宏名”,都用宏定义中的字符串去代换,这称为“宏代换”或“宏展开”。 宏替换在编译前进行,不分配内存; 宏展开不占运行时间,只占编译时间; 宏替换只作替换,不做计算。
#define NEMBER 9 //#define 宏名 文本
#define M(a, b) a*b //#define 宏名(参数表) 文本
#define SWITCHON //#define 宏名 //(定义一个条件编译的开关字段)
#define NAME(n) num ## n //宏定义,使用 ## 运算符,粘合的作用
int num0 = 10;
printf("num0 = %d\\n", NAME(0));//宏调用NAME(0)被替换为 num ## 0,被粘合为:num0。
//可变宏:… 和 __VA_ARGS__
#define PR(...) printf(__VA_ARGS__) //宏定义
PR("hello\\n"); //宏调用
//输出结果:hello
//在宏定义中,形参列表的最后一个参数为省略号“…”,而“__VA_ARGS__”就可以被用在替换文本中,来表示省略号“…”代表了什么。
//而上面例子宏代换之后为:printf(“hello\\n”);
#undef指令删除前面定义的宏名字(也就是#define的标识符)。 也就是说,它“不定义”宏。 (注意:如果标识符当前没有被定义成一个宏名称,那么就会忽略该指令),一般形式为:
#undef NEMBER //取消之前已定义的NEMBER
#define NEMBER 100 //重新定义NUMBE为100
2、系统预定义的宏
LINE : 当前源文件的行号,整数
FILE : 当前源文件名,char 字符串,文件的完整路径和文件名**
DATE : 当前编译日期,char 字符串,格式:月 日 年
TIME : 当前编译时间,char 字符串,格式:时 分 秒
STDC : 整数 1,表示兼容 ANSI/ISO C 标准,配合 #if 使用
**TIMESTAMP ** : 最后一次修改当前文件的时间戳,char 字符串,格式:年 月份 日期 时 分 秒
3、文件包含
当一个C语言程序由多个文件模块组成时,主模块中一般包含main函数和一些当前程序专用的函数。 程序从main函数开始执行,在执行过程中,可调用当前文件中的函数,也可调用其他文件模块中的函数。
如果在模块中要调用其他文件模块中的函数,首先必须在主模块中声明该函数原型。 一般都是采用文件包含的方法,包含其他文件模块的头文件。
包含文件的格式有#include后面跟尖括号<>和双引号“”之分。 两者的主要差别是搜索路径的不同。 C的标准库加.h,C++标准库可以不加.h。
尖括号形式:如#include
双引号形式:如#include“para.h”,首先到当前工作目录下查找该文件,如果未发现,再按尖括号包含时的办法到系统目录下查找。 包含自定义的头文件,一般采用该方式。 虽然系统标准库头文件采用此方式也正确,但浪费了不必要的搜索时间,故系统标准库头文件不建议采用该包含方式。
4、条件编译
条件编译允许程序员有选择按照不同的条件去编译程序的不同部分,从而得到不同的目标代码。 使用条件编译,可方便地处理程序的调试版本和正式版本,也可使用条件编译使程序的移植更方便。
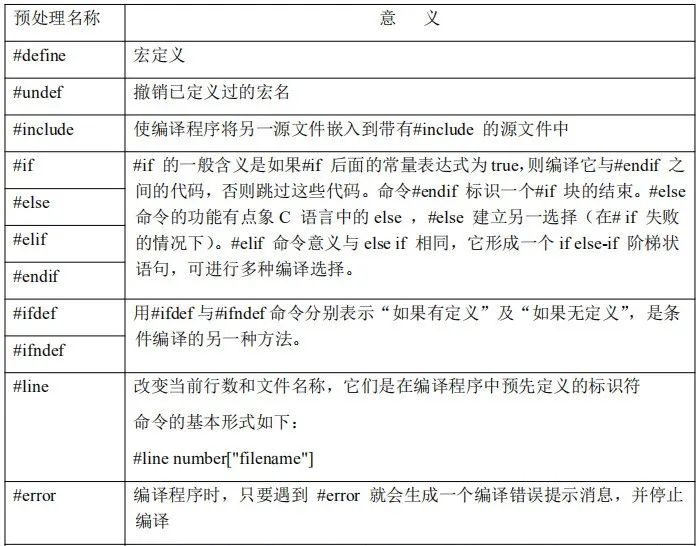
常见的条件编译指令有 #if、#elif、#else、#endif、#ifdef、#ifndef。
#if、#elif、#else、#endif的使用和if、elseif 、else的使用非常相似,一般使用格式如下:
#if 整型常量表达式1
程序段1
#elif 整型常量表达式2
程序段2
#else
程序段3
#endif
执行起来就是,如果整形常量表达式为真,则执行程序段1,否则继续往后判断依次类推(注意是整形常量表达式),最后#endif是#if的结束标志。
#ifdef的作用是判断某个宏是否定义,如果该宏已经定义则执行后面的代码,#ifndef恰好和#ifdef相反,一般使用格式如下:
//ifdef
#ifdef 宏名
程序段1
#else
程序段2
#endif
//ifndef
#ifndef 宏名
程序段1
#else
程序段2
#endif
#ifdef表示如果该宏已被定义过,则对“程序段1”进行编译,否则对“程序段2”进行编译(这个和上面的#if一样最后都需要#endif),上述格式也可以不用#else,这一点上和if else相同。
#ifndef表示如果该宏未被定义,则对“程序段1”进行编译,否则对“程序段2”进行编译。
5、特殊命令
#line 可以改变 LINE 和 _FILE_两个宏的内容,即为其指定新的值。 其本质是重定义 LINE 和 FILE ,主要有以下两种形式:
#line linenum
#line linenum 文件名
int main()
{
printf( "code is on line %d, in file %s\\n", __LINE__, __FILE__ );
#line 10
printf( "code is on line %d, in file %s\\n", __LINE__, __FILE__ );
#line 20 "hello.cpp"
printf( "code is on line %d, in file %s\\n", __LINE__, __FILE__ );
printf( "code is on line %d, in file %s\\n", __LINE__, __FILE__ );
}
输出为:
code is on line 7, in file line_directive.cpp
code is on line 10, in file line_directive.cpp
code is on line 20, in file hello.cpp
code is on line 21, in file hello.cpp
#error :当预处理器预处理到#error命令时将停止编译并输出用户自定义的错误消息,一般用于调试程序。
#error [用户自定义的错误消息]
//注:上述语法成份中的方括号"[]"代表用户自定义的错误消息可以省略不写。
//举例1:
#error Sorry,an error has occurred!
//举例2:
#error
#ifndef A
#define A 5
#endif
#if A < 5
#error Sorry,an error has occurred!
#endif
#warning :****类似于#error 指令,但不会导致取消预处理,程序继续编译,不会影响程序的正常运行。 #warning 指令之后的信息在预处理继续之前作为消息输出,产生警告。
#warning [用户自定义的警告信息]
#warning Sorry,an warning has occurred!
#pragma:是功能比较丰富且灵活的指令,可以有不同的参数选择,从而完成相应的特 定功能操作。 #pragma指令是计算机或操作系统特定的,并且通常对于每个编译器而言都有所不同。 #pragma指令可用于条件语句以提供新的预处理器功能,或为编译器提供实现所定义的信息
其格式一般为: #pragma Para。 其中Para 为参数,参数可以有 message 类型、code_seg、once、warning、pack 等,具体可以在网上详细查看。 举两个常用的例子:
#pragma一次
只要在头文件的最开始加入这条指令就能够保证指定该文件在编译源代码文件时仅由编译器包含(打开)一次,使用 #pragma once 可减少生成次数,和使用预处理宏定义来避免多次包含文件的内容的效果是一样的,但是需要键入的代码少,可减少错误率,这条指令实际上在VC6中就已经有了,但是考虑到兼容性并没有太多的使用它。
//使用#progma once
#pragma once
// Code placed here is included only once per translation unit
//使用宏定义方式
#ifndef HEADER_H_
#define HEADER_H_
// Code placed here is included only once per translation unit
#endif // HEADER_H_
#pragma once是编译相关,就是说这个编译系统上能用,但在其他编译系统不一定可以,也就是说移植性差,不过基本上已经是每个编译器都有这个定义了。
#pragma包 (n)
指定结构、联合和类成员的封装对齐。 其实就是改变编译器的内存对齐方式。 这个功能对于集合数据体使用,默认的数据的对齐方式占用内存比较大,可进行修改。 在没有参数的情况下调用pack会将n设置为编译器选项中设置的值。 如果未设置编译器选项,windows默认为8,linux默认为4。 具体的使用方法为,其中n称为对齐系数,取值必须是2的幂次方,即1、2、4、8、16等。
1. #pragma pack(show) 以警告信息的形式显示当前字节对齐的值.
2. #pragma pack(n) 将当前字节对齐值设为 n .
3. #pragma pack() 将当前字节对齐值设为默认值(通常是8) .
4. #pragma pack(push) 将当前字节对齐值压入编译栈栈顶.
5. #pragma pack(pop) 将编译栈栈顶的字节对齐值弹出并设为当前值.
6. #pragma pack(push, n) 先将当前字节对齐值压入编译栈栈顶, 然后再将 n 设为当前值.
7. #pragma pack(pop, n) 将编译栈栈顶的字节对齐值弹出, 然后丢弃, 再将 n 设为当前值.
8. #pragma pack(push, identifier) 将当前字节对齐值压入编译栈栈顶, 然后将栈中保存该值的位置标识为 identifier .
10. #pragma pack(pop, identifier) 将编译栈栈中标识为 identifier 位置的值弹出, 并将其设为当前值. 注意, 如果栈中所标识的位置之上还有值, 那会先被弹出并丢弃.
11. #pragma pack(push, identifier, n) 将当前字节对齐值压入编译栈栈顶, 然后将栈中保存该值的位置标识为 identifier, 再将 n 设为当前值.
12. #pragma pack(pop, identifier, n) 将编译栈栈中标识为 identifier 位置的值弹出, 然后丢弃, 再将 n 设为当前值. 注意, 如果栈中所标识的位置之上还有值, 那会先被弹出并丢弃.
//注意: 如果在栈中没有找到 pop 中的标识符, 则编译器忽略该指令, 而且不会弹出任何值.
通常成对使用:
#pragma pack (n) //作用:编译器将按照n个字节对齐。
#pragma pack () //作用:取消自定义字节对齐方式。
#pragma pack (push,1) //作用:是指把原来对齐方式设置压栈,并设新的对齐方式设置为一个字节对齐
#pragma pack(pop) //作用:恢复对齐状态
-
处理器
+关注
关注
68文章
19156浏览量
229066 -
函数
+关注
关注
3文章
4304浏览量
62415 -
命令
+关注
关注
5文章
678浏览量
21981 -
C++
+关注
关注
22文章
2104浏览量
73482 -
编译器
+关注
关注
1文章
1618浏览量
49043
发布评论请先 登录
相关推荐
C语言常用的预处理命令
c语言预处理命令以什么开头
Tcl/Tk命令与C/C++的集成研究
基于51单片机--C语言之预处理总结

C++的const多文件编译预处理的资料说明

C51的预处理命令和用户配置文件详细资料说明
C预处理器及其工作原理





 工商网监
工商网监
评论