 2023年AI技术科普:算法、算力、数据及应用
2023年AI技术科普:算法、算力、数据及应用
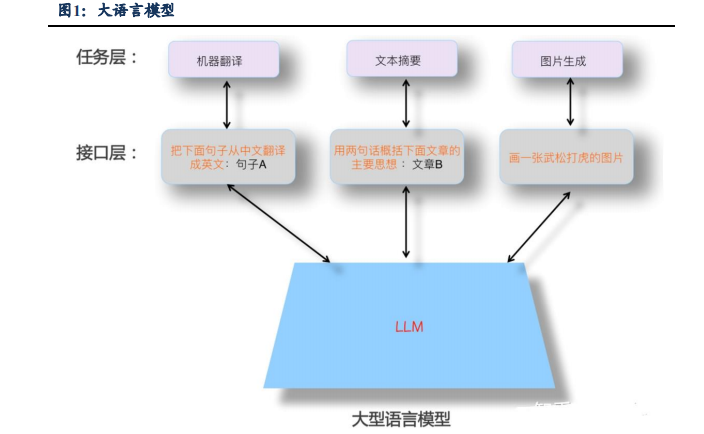
大模型是AI开发的新范式,是人工智能迈向通用智能的里程碑:大模型指通过在大规模宽泛的数据上进行训练后能适应一系列下游任务的模型,本质依旧是基于统计学的语言模型,只不过“突现能力”赋予其强大的推理能力。大模型的训练和推理都会用到AI芯片的算力支持,在数据和算法相同情况下,算力是大模型发展的关键,是人工智能时代的“石油”。
1.算法:大模型——人工智能迈向通用智能的里程碑
大模型就是Foundation Model(基础模型),指通过在大规模宽泛的数据上进行训练后能适应一系列下游任务的模型。大模型兼具“大规模”和“预训练”两种属性,面向实际任务建模前需在海量通用数据上进行预先训练,能大幅提升人工智能的泛化性、通用性、实用性,是人工智能迈向通用智能的里程碑技术。
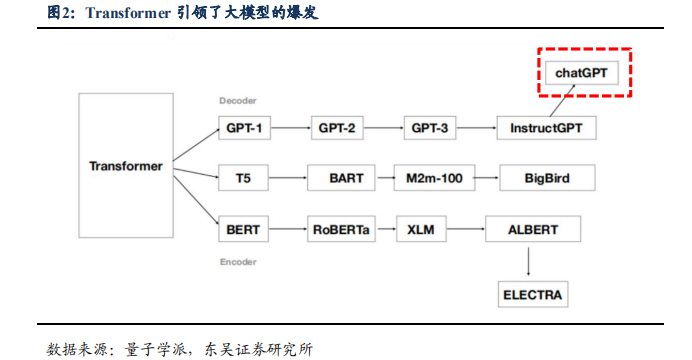
大模型的本质依旧是基于统计学的语言模型,“突现能力”赋予其强大的推理能力。当前几乎所有参数规模超过千亿的大语言模型都采取GPT模式。近些年来,大型语言模型研究的发展主要有三条技术路线:Bert模式、GPT模式以及混合模式。Bert模式适用于理解类、做理解类、某个场景的具体任务,专而轻,2019年后基本上就没有什么标志性的新模型出现;混合模式大部分则是由国内采用;多数主流大语言模型走的还是GPT模式,2022年底在GPT-3.5的基础上产生了ChatGPT,GPT技术路线愈发趋于繁荣。
GPT4作为人工智能领域最先进的语言模型,在如下四个方面有较大的改进。
1)多模态:GPT4可以接受文本和图像形式的prompt,在人类给定由散布的文本和图像组成的输入的情况下生成相应的文本输出(自然语言、代码等);
2)多语言:在测试的26种语言的24种中,GPT-4优于GPT-3.5和其他大语言模型(Chinchilla,PaLM)的英语语言性能;
3)“记忆力”:GPT-4的最大token数为32,768,即2^15,相当于大约64,000个单词或50页的文字,远超GPT-3.5和旧版ChatGPT的4,096个token;
4)个性化:GPT-4比GPT-3.5更原生地集成了可控性,用户将能够将“具有固定冗长、语气和风格的经典ChatGPT个性”更改为更适合他们需要的东西。
2.算力:AI训练的基础设施
大模型算力成本主要分为初始训练成本和后续运营成本。
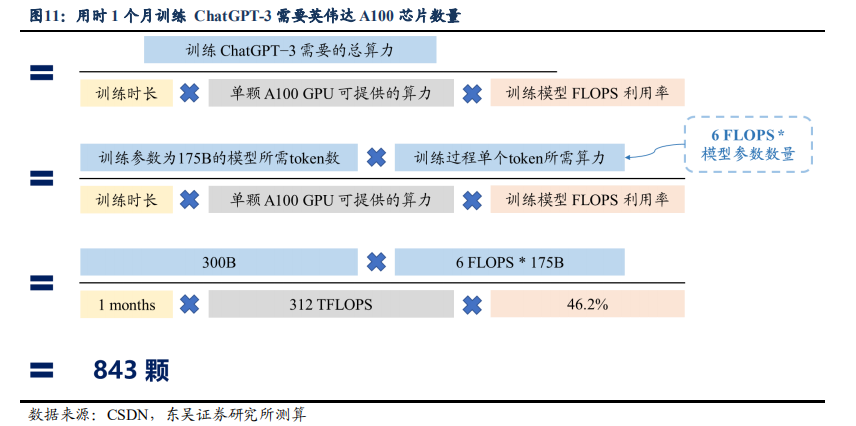
初始训练:根据openAI官网数据,每个token(token是服务端生成的一串字符串,以作客户端进行请求的一个令牌)的训练成本通常约为6N FLOPS(FLOPS指每秒浮点运算次数,理解为计算速度,可以用来衡量硬件的性能),其中N是LLM(大型语言模型)的参数数量。1750亿参数模型的GPT-3是在3000亿token上进行训练的。根据openAI官网数据,在训练过程中,模型的FLOPS利用率为46.2%。我们假设训练时间为1个月,采用英伟达A100进行训练计算(峰值计算能力为312 TFLOPS FP16/FP32),则测算结果为需要843颗英伟达A100芯片。
运营(推理)成本:运营阶段所需算力量与使用者数量紧密相关。根据openAI官网数据,每个token的推理成本通常约为2N FLOPS,其中N是LLM的参数数量。根据openAI官网数据,在训练过程中,模型的FLOPS利用率为21.3%。同样采用英伟达A100进行推理计算(峰值计算能力为312 TFLOPS FP16/FP32)。我们假设GPT-3每日5000万活跃用户,每个用户提10个问题,每个问题回答400字,则测算结果为需要16255颗英伟达A100芯片。

GPT-4为多模态大模型,对算力要求相比GPT-3会提升10倍。GPT-4的收费是8kcontext为$0.03/1k token,是GPT-3.5-turbo收费的15倍($0.002 / 1K tokens),因此我们推断GPT-4的参数量是GPT-3的10倍以上,预计GPT-4的算力需求是GPT-3的10倍以上。
国产大模型有望带动国内新增A100出货量超200万颗,使得中国算力市场空间增加2倍以上。我们假设国内百度,华为,阿里,腾讯,字节等前10位头部大厂都会发布自己的大模型。
加速卡国产化率较低,美国制裁加速。根据IDC数据,2021年,中国加速卡市场中Nvidia占据超过80%市场份额。
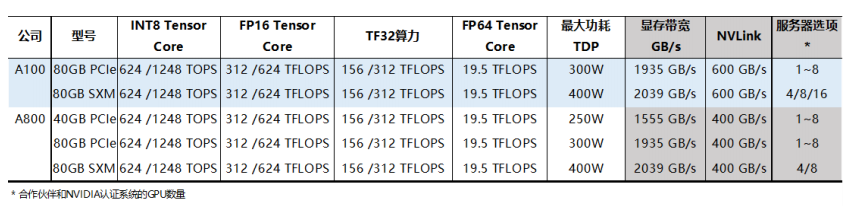
英伟达推出中国特供版A800,算力与A100基本一致。2022年11月8日,英伟达推出A800 GPU,将是面向中国客户的A100 GPU的替代产品。A800符合美国政府关于减少出口管制的明确测试,并且不能通过编程来超过它。A800 GPU在算力上与A100保持一致,但增加了40GB显存的PCIe版本,但在NVLink互联速度上,A800相较于A100下降了200GB/s的速度。同时,A800 80GB SXM版本目前已经不支持16块GPU的成套系统,上限被限制在8块。总的来看,A800能够满足国内市场需求,是A100的平替版本。
3.数据:AI发展的驱动力
数据资源是AI产业发展的重要驱动力之一。数据集作为数据资源的核心组成部分,是指经过专业化设计、采集、清洗、标注和管理,生产出来的专供人工智能算法模型训练的数据。
大模型的训练数据主要来自于维基百科、书籍、期刊、Reddit社交新闻站点、Common Crawl和其他数据集。OpenAI虽没有直接公开ChatGPT的相关训练数据来源和细节,但可以从近些年业界公布过的其他大模型的训练数据推测出ChatGPT的训练数据来源,近几年大模型训练采用的数据来源基本类似。国内大模型的数据来源和自身优势业务有较强相关性,如百度文心一言大模型的来源主要基于互联网公开数据,包括网页、搜索、图片、语音日均调用数据,以及知识图谱等。
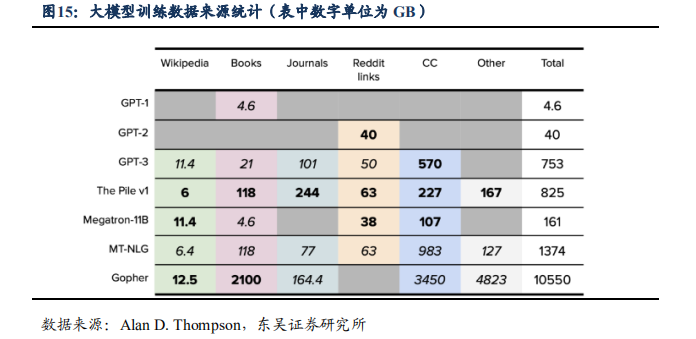
GPT4依靠大量多模态数据训练。GPT4是一个大规模的多模态模型,相比于此前的语言生成模型,数据方面最大的改进之一就是突破纯文字的模态,增加了图像模态的输入,具有强大的图像理解能力,即在预练习阶段输入任意顺序的文本和图画,图画经过Vision Encoder向量化、文本经过普通transformer向量化,两者组成多模的句向量,练习目标仍为next-word generation。根据腾讯云开发者推测,GPT4训练数据中还额外增加了包含正误数学问题、强弱推理、矛盾一致陈述及各种意识形态的数据,数据量可能是GPT3.5(45TB数据)的190倍。
4.应用:AI的星辰大海
AI时代已经来临,最大的市场将是被AI赋能的下游应用市场。如果说AI是第四次工业革命,那么正如前三次工业革命,最大的市场将是被AI赋能的下游应用市场。本轮革命性的产品ChatGPT将极大地提升内容生产力,率先落地于AIGC领域,打开其产业的想象边界。文本生成、代码生成、图像生成以及智能客服将是能直接赋予给下游行业的能力,打开其产业想象的边界。
最直接的应用在内容创作领域。ChatGPT的功能核心是基于文本的理解和分析,与内容创作行业趋同。ChatGPT可用于创建新闻文章、博客文章甚至小说等内容,它可以生成原创且连贯的内容,为内容创作者节省时间和资源。整体生成式AI已用于创建图像,视频,3D对象,Skyboxes等。这大大节省了创作时间,同时带来了多样的创作风格。
ChatGPT解决了机器人的痛点。ChatGPT开启了一种新的机器人范式,允许潜在的非技术型用户参与到回路之中,ChatGPT可以为机器人场景生成代码。在没有任何微调的情况下,利用LLM的知识来控制不同的机器人动作,以完成各种任务。ChatGPT大大改善了机器人对指令的理解,并且不同于以前单一、明确的任务,机器人可以执行复合型的任务。
ChatGPT在芯片设计领域的应用。传统的芯片设计强烈依赖模板而忽视了大量可以复用的优秀数据,同时数据量大导致ChatGPT泛化性更好。此外芯片硬件模块相对单一,有一些成熟范式,芯片设计代码复杂但人工不足,这些都与ChatGPT有很好的互补。AI使得芯片开发成本降低、周期缩短,具备足够多训练数据和AI能力的芯片设计公司竞争优势可能会扩大。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4607浏览量
92826 -
人工智能
+关注
关注
1791文章
47183浏览量
238212 -
ai技术
+关注
关注
1文章
1266浏览量
24284
原文标题:2023年AI技术科普:算法、算力、数据及应用
文章出处:【微信号:架构师技术联盟,微信公众号:架构师技术联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
大模型时代的算力需求
AI真·炼丹:整整14天,无需人类参与
DPU技术赋能下一代AI算力基础设施

立足算力,聚焦AI!顺网科技全面走进AI智算时代


AI算力应用中的光模块产品
算力大升级 英特尔至强可扩展处理器持续技术创新






 工商网监
工商网监
评论