 大算力模型,HBM、Chiplet和CPO等技术打破技术瓶颈
大算力模型,HBM、Chiplet和CPO等技术打破技术瓶颈
大语言模型涉及对高性能硬件(如 GPU、TPU)、大规模高质量数据集的需求以及软件算法的提高等多方面要求。
1.HBM 技术:高吞吐高带宽,AI 带动需求激增
HBM(High Bandwidth Memory)意为高带宽存储器,是一种硬件存储介质,是高性能 GPU 的核心组件。HBM 具有高吞吐高带宽的特性,受到工业界和学术界的关注。它单颗粒的带宽可以达到 256 GB/s,远超过 DDR4 和 GDDR6。DDR4 是 CPU 和硬件处理单元的常用外挂存储设备,但是它的吞吐能力不足以满足当今计算需求,特别是在 AI 计算、区块链和数字货币挖矿等大数据处理访存需求极高的领域。GDDR6 也比不上 HBM,它单颗粒的带宽只有 64 GB/s,是HBM 的 1/4。而 DDR4 3200 需要至少 8 颗粒才能提供 25.6 GB/s 的带宽,是 HBM 的 1/10。
HBM 使用多根数据线实现高带宽,完美解决传统存储效率低的问题。HBM 的核心原理和普通的 DDR、GDDR 完全一样,但是 HBM 使用多根数据线实现了高带宽。HBM/HBM2 使用 1024 根数据线传输数据,作为对比,GDDR 是 32 根,DDR 是 64 根。HBM 需要使用额外的硅联通层,通过晶片堆叠技术与处理器连接。这么多的连接线保持高传输频率会带来高功耗。因此 HBM 的数据传输频率相对很低,HBM2 也只有 2 Gbps,作为对比,GDDR6 是 16 Gbps,DDR4 3200 是3.2 Gbps。这些特点导致了 HBM 技术高成本,容量不可扩,高延迟等缺点。
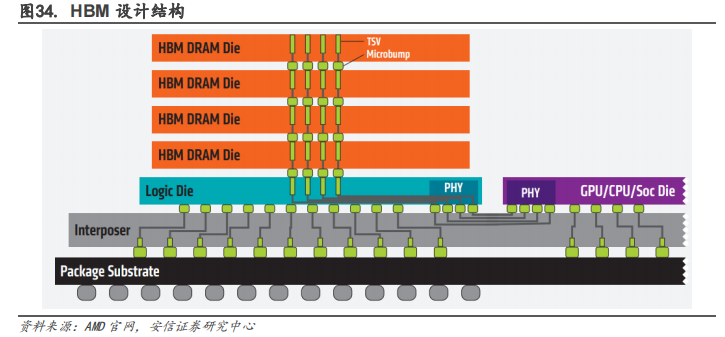
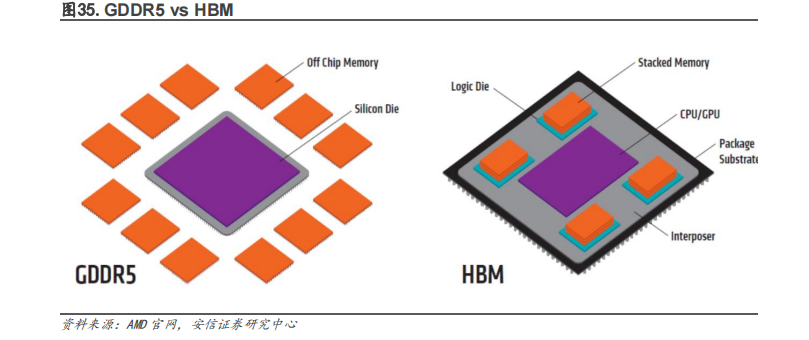
HBM 可以被广泛的应用到汽车高带宽存储器,GPU 显存芯片,部分 CPU 的内存芯片,边缘 AI加速卡,Chiplets 等硬件中。在高端 GPU 芯片产品中,比如 NVDIA 面向数据中心的 A100 等加速卡中就使用了 HBM;部分 CPU 的内存芯片,如目前富岳中的 A64FX 等 HPC 芯片中也有应用到。车辆在快速移动时,摄像头、传感器会捕获大量的数据,为了更快速的处理数据,HBM是最合适的选择。Chiplets 在设计过程中没有降低对内存的需求,随着异构计算(尤其是小芯片)的发展,芯片会加速对高带宽内存的需求,无论是 HBM、GDDR6 还是 LPDDR6。
HBM 缓解带宽瓶颈,是 AI 时代不可或缺的关键技术。AI 处理器架构的探讨从学术界开始,当时的模型简单,算力低,后来模型加深,算力需求增加,带宽瓶颈出现,也就是 IO 问题。这个问题可以通过增大片内缓存、优化调度模型等方法解决。但是随着 AI 大模型和云端 AI处理的发展,计算单元剧增,IO 问题更严重了。要解决这个问题需要付出很高的代价(比如增加 DDR 接口通道数量、片内缓存容量、多芯片互联),这便是 HBM 出现的意义。HBM 用晶堆叠技术和硅联通层把处理器和存储器连接起来,把 AI/深度学习完全放到片上,提高集成度,降低功耗,不受芯片引脚数量的限制。HBM 在一定程度上解决了 IO 瓶颈。未来人工智能的数据量、计算量会越来越大,超过现有的 DDR/GDDR 带宽瓶颈,HBM 可能会是唯一的解决方案。
巨头领跑,各大存储公司都已在 HBM 领域参与角逐。SK 海力士、三星、美光等存储巨头在HBM 领域展开了升级竞赛,国内佰维存储等公司持续关注 HBM 领域。SK 海力士早在 2021 年10 月就开发出全球首款 HBM3,2022 年 6 月量产了 HBM3 DRAM 芯片,并将供货英伟达,持续巩固其市场领先地位。三星也在积极跟进,在 2022 年技术发布会上发布的内存技术发展路线图中,HBM3 技术已经量产。
2、Chiplet技术:全产业链升级降本增效,国内外大厂前瞻布局
Chiplet 即根据计算单元或功能单元将 SOC 进行分解,分别选择合适制程工艺制造。随着处理器的核越来越多,芯片复杂度增加、设计周期越来越长,SoC 芯片验证的时间、成本也急剧增加,特别是高端处理芯片、大芯片。当前集成电路工艺在物理、化学很多方面都达到了极限,大芯片快要接近制造瓶颈,传统的 SoC 已经很难继续被采纳。Chiplet,俗称小芯片、芯粒,是将一块原本复杂的 SoC 芯片,从设计的时候就按照不同的计算单元或功能单元进行分解,然后每个单元分别选择最合适的半导体制程工艺进行制造,再通过先进封装技术将各自单元彼此互联。Chiplet 是一种类似搭乐高积木的方法,能将采用不同制造商、不同制程工艺的各种功能芯片进行组装,从而实现更高良率、更低成本。
Chiplet 可以从多个维度降低成本,延续摩尔定律的“经济效益”。随着半导体工艺制程推进,晶体管尺寸越来越逼近物理极限,所耗费的时间及成本越来越高,同时所能够带来的“经济效益”的也越来越有限。Chiplet 技术可从三个不同的维度来降低成本:
(1)可大幅度提高大型芯片的良率:芯片的良率与芯片面积有关,Chiplet 设计将大芯片分成小模块可以有效改善良率,降低因不良率导致的成本增加。
(2)可降低设计的复杂度和设计成本:Chiplet 通过在芯片设计阶段就将 Soc 按照不同功能模块分解成可重复云涌的小芯粒,是一种新形式的 IP 复用,可大幅度降低设计复杂度和成本累次增加。
(3)可降低芯片制造的成本:在 Soc 中的一些主要逻辑计算单元是依赖于先进工艺制程来提升性能,但其他部分对制程的要求并不高,一些成熟制程即可满足需求。将Soc进行Chiplet化后对于不同的芯粒可选择对应合适的工艺制程进行分开制造,极大降低芯片的制造成本。
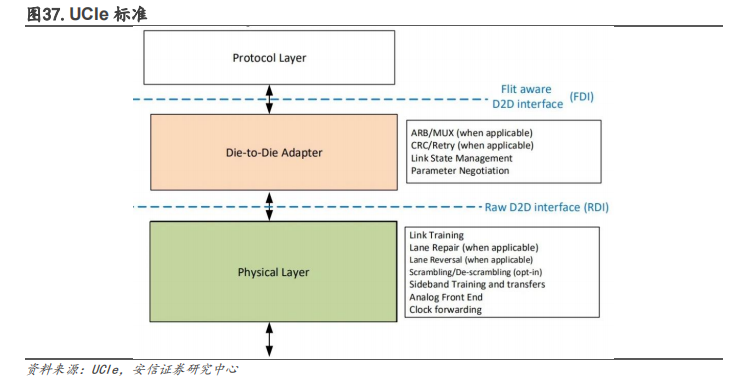
Chiplet 为全产业链提供了升级机会。在后摩尔时代,Chiplet 可以开启一个新的芯片生态。2022年 3 月,Chiplet的高速互联标准——UCIe(UniversalChiplet Interconnect Express,通用芯粒互联技术)正式推出,旨在芯片封装层面确立互联互通的统一标准,打造一个开放性的 Chiplet 生态系统。巨头们合力搭建起了统一的 Chiplet 互联标准,将加速推动开放的Chiplet 平台发展,并横跨 x86、Arm、RISC-V 等架构和指令集。Chiplet 的影响力也从设计端走到芯片制造与封装环节。在芯片小型化的设计过程中,需要添加更多 I/O 与其他芯片芯片接口,裸片尺寸必须要保持较大的空白空间。而且,要想保证 Chiplet 的信号传输质量就需要发展高密度、大宽带布线的先进封装技术。另外,Chiplet 也影响到从 EDA 厂商、晶圆制造和封装公司、芯粒 IP 供应商、Chiplet 产品及系统设计公司到 Fabless 设计厂商的产业链各个环节的参与者。
(1)最先受到影响的是芯片 IP 设计企业,Chiplet 本质就是不同的 IP 芯片化,国内类似 IP 商均有望参与其中,比如华为海思有 IP 甚至指令集开发实力的公司,推出基于 RISC-V 内核的处理器(玄铁 910)阿里平头哥半导体公司,独立的第三方 IP 厂商,如芯动科技、芯原股份、芯耀辉、锐成芯微、芯来等众多 IP 公司等。
(2)Chiplet 需要 EDA 工具从架构探索、芯片设计、物理及封装实现等提供全面支持,为国内 EDA 企业发展带来了突破口。芯和半导体已全面支持 2.5D Interposer、3DIC 和 Chiplet 设计。
(3)Chiplet 也推动了先进封装技术的发展。根据长电科技公告,在封测技术领域取得新的突破。4nm 芯片作为先进硅节点技术,是导入 Chiplet 封装的一部分通富微电提供晶圆级及基板级封装两种解决方案,其中晶圆级 TSV 技术是 Chiplet 技术路径的一个重要部分。

国外芯片厂率先发力,通过 Chiplet 实现收益。AMD 的 EPYC 率先采用了 Chiplet 结构,实现了在服务器 CPU 市场上的翻身。随后,Ryzen 产品上重用了 EYPC Rome 的 CCD,这样的 chiplet设计极好的降低了总研发费用。2023 年 1 月,Intel 发布了采用了 Chiplet 技术的第四代至强可扩展处理器 Sapphire Rapids 以及英特尔数据中心 GPU Max 系列等。Sapphire Rapids是 Intel 首个基于 Chiplet 设计的处理器,被称为“算力神器”。Xilinx 的 2011 Virtex-72000T 是 4 个裸片的 Chiplet 设计。Xilinx 也是业界唯一的同构和异构的 3D IC。
3、CPO 技术:提升数据中心及云计算效率,应用领域广泛
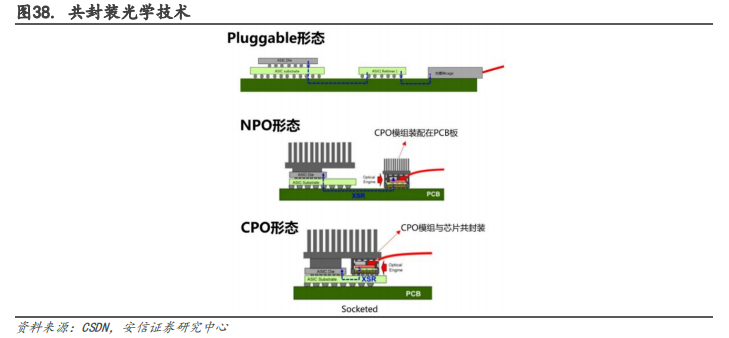
CPO(Co-packaged,共封装光学技术)是高速电信号能够高质量的在交换芯片和光引擎之间传输。在 5G 时代,计算、传输、存储的带宽要求越来越高,同时硅光技术也越来越成熟,因此板上和板间的光互连成为了一种必要的方式。随着通道数大幅增加,需要专用集成电路(ASIC)来控制多个光收发模块。传统的连接方式是 Pluggable(可插拔),即光引擎是可插拔的光模块,通过光纤和 SerDes 通道与网络交换芯片(AISC)连接。之后发展出了 NPO(Near-packaged,近封装光学),一种将光引擎和交换芯片分别装配在同一块 PCB 基板上的方式。而CPO 是一种将交换芯片和光引擎共同装配在同一个 Socketed(插槽)上的方式,形成芯片和模组的共封装,从而降低网络设备的功耗和散热问题。NPO 是 CPO 的过渡阶段,相对容易实现,而 CPO 是最终解决方案。
随着大数据及 AI 的发展,数据中心的需求激增,CPO 有着广泛的应用前景。在数据中心领域,CPO 技术可以实现更高的数据密度和更快的数据传输速度,还可以减少系统的功耗和空间占用,降低数据中心的能源消耗和维护成本,能够应用于高速网络交换、服务器互联和分布式存储等领域,例如,Facebook 在其自研的数据中心网络 Fabric Aggregator 中采用了CPO 技术,提高了网络的速度和质量。在云计算领域,CPO 技术可以实现高速云计算和大规模数据处理。例如微软在其云计算平台 Azure 中采用了 CPO 技术,实现更高的数据密度和更快的数据传输速度,提高云计算的效率和性能。
在 5G 通信领域,CPO 技术可以实现更快的无线数据传输和更稳定的网络连接。例如华为在其 5G 通信系统中采用了 CPO 技术,将收发器和芯片封装在同一个封装体中,从而实现了高速、高密度、低功耗的通信。除此之外,5G/6G 用户的增加,人工智能、机器学习 (ML)、物联网 (IoT) 和虚拟现实流量的延迟敏感型流量激增,对光收发器的数据速率要求将快速增长;AI、ML、VR 和 AR 对数据中心的带宽要求巨大,并且对低延迟有极高的要求,未来 CPO 的市场规模将持续高速扩大。
审核编辑 :李倩
-
gpu
+关注
关注
28文章
4818浏览量
129639 -
物联网
+关注
关注
2914文章
45118浏览量
378950 -
chiplet
+关注
关注
6文章
437浏览量
12654 -
CPO
+关注
关注
0文章
28浏览量
252
原文标题:大算力模型,HBM、Chiplet和CPO等技术打破技术瓶颈
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
芯片、模型生态分散,无问芯穹、沐曦、壁仞谈国产算力瓶颈破局之道

信而泰CCL仿真:解锁AI算力极限,智算中心网络性能跃升之道

解锁Chiplet潜力:封装技术是关键

浪潮信息与智源研究院携手共建大模型多元算力生态
算力再跃升!亿万克发布新一代AI服务器——G882N7+!
亿铸科技熊大鹏探讨AI大算力芯片的挑战与解决策略
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
摩尔线程GPU算力底座助力大模型产业发展
名单公布!【书籍评测活动NO.41】大模型时代的基础架构:大模型算力中心建设指南
IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
HBM:突破AI算力内存瓶颈,技术迭代引领高性能存储新纪元

大算力时代, 如何打破内存墙





 工商网监
工商网监
评论