 Armv8架构及虚拟化介绍
Armv8架构及虚拟化介绍

0、ARMv8架构
1)ARMv8基本概念
(1)执行状态(execution state):处理器运行时的环境,包括寄存器的位宽、支持的指令集、异常模型、内存管理及编程模型等。ARMv8体系结构定义了两个执行状态:
AArch64:64位的执行状态
提供31个64位的通用寄存器。
提供64位程序计数指针寄存器(Program Counter,PC)、栈指针寄存器(Stack Pointer,SP)及异常链接寄存器(Exception Link Register,ELR)。
提供A64精简指令集。
定义ARMv8异常模型,支持4个异常等级:EL0~EL3。
提供64位的内存模型。
定义一组处理器状态(PSTATE),用来保存PE(Processing Element,处理机)的状态。
AArch32:32位的执行状态
提供13个32位的通用寄存器、PC指针寄存器、SP寄存器、链接寄存器。
支持A32和T32两套指令集。
支持ARMv7-A异常模型。
提供32位的虚拟内存访问机制。
定义一组处理器状态(PSTATE),用来保存PE的状态。
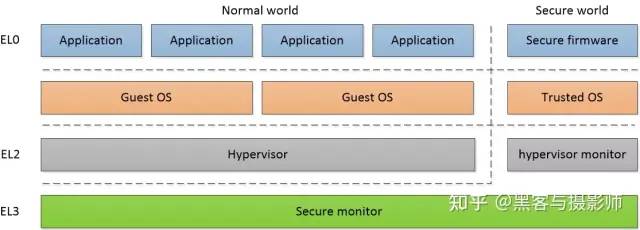
AArch64状态的异常等级
ARMv8处理器支持两种执行状态:AArch64状态和AArch32状态。其中AArch64状态是ARMv8新增的64位执行状态,该状态下运行A64指令集。AARch32状态是为了兼容ARMv7的32位执行状态,该状态下运行A32指令集或者T32指令集。
AArch64状态的异常等级,决定了处理器当前运行的特权级别,类似于ARMv7中的特权等级。
EL0:用户特权,用于运行普通用户程序。
EL1:系统特权,通常用于操作系统内核,比如linux、rtos。如果系统使能了虚拟化扩展,运行虚拟机操作系统内核。
EL2:运行虚拟化扩展的虚拟机监控器(hypervisor)。
EL3:运行安全世界中的安全监控器(secure monitor)。
ARMv8允许切换应用程序的运行模式,在一个64位操作系统的ARMv8处理器中,我们可以同时运行A64指令集和A32指令集的应用程序,但是32位操作系统的ARMv8处理器中,就不能运行A64指令集的应用程序了。
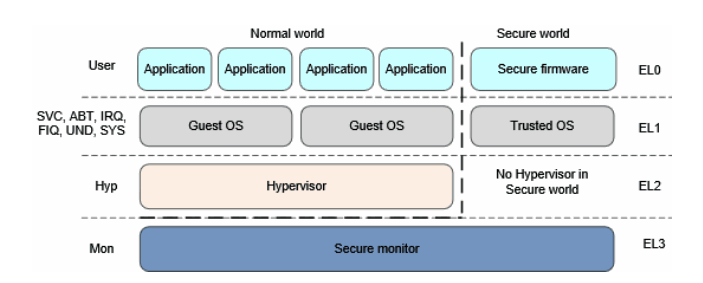
ARMv8体系结构提供2种安全状态:Secure和Non-secure。Secure state和Non-secure state将运行环境划分为Normal world和Secure world,EL3只存在于Secure state。每种安全状态有独立的物理地址空间范围,在Secure state,处理器可以访问Secure和Non-secure的物理地址空间范围。在Non-secure state,处理器只能访问Non-secure的物理地址空间范围。
异常等级之间的切换:
Supervisor Call(SVC)指令:EL0的软件向EL1(OS service)申请软件服务。
Hypervisor Call(HVC)指令:主要被EL1(guest OS)请求hypervisor(EL2)服务。
Secure monitor Caller(SMC)指令:EL3用来切换安全非安全世界。
ERET指令用于异常返回,返回地址和处理器状态是从当前EL(exception level)下的ELR和SPSR寄存器中恢复的。ERET 指令可用于返回到 CPU 支持的相同或任何较低的异常级别。如果存储在 SPSR_EL3.M[4:0] 中的已保存模式字段,设置为 0b00101 或 0b00100,其中位M[ 3:2] 将异常级别编码为1,然后在 EL3 执行的 ERET 指令将返回到 EL1。
(2)ARMv8指令集:根据不同的执行状态,提供不同的指令集支持,支持如下指令集。
A64指令集:运行在AArch64状态下,提供64位指令集支持。A64指令集是ARMv8新增的,和A32采用了不同的指令编码,所以跟A32不兼容。A64可以处理64位宽的寄存器和数据,使用64位的指针来访存,但是A64指令集的指令宽度是32位。
A32指令集:运行在AArch32状态下,提供32位A32指令集支持。
T32指令集:运行在AArch32状态下,提供16位和32位Thumb指令集支持。
2)ARMv8特性
使用64位体系结构,因此处理器可以访问远超4GB的物理地址空间。虽然是64位体系结构,但是一般并不使用64位地址总线,例如使用48位,即可以访问256TB的物理地址空间。在32位ARM体系结构中,如果不使能LPAE(Large Physical Address Extension)功能,最多只能访问4GB物理地址空间。即使使能了LPAE功能,也只是将物理地址空间的寻址能力扩展到40位,也就是1TB。
提供64位的虚拟地址寻址,从而扩大了进程的虚拟地址空间。在32位ARM体系结构中,即使使能了LAPE功能,也只是扩展了物理地址空间,但是进程的虚拟地址空间还是只有4GB。扩大虚拟地址空间之后,可以使用memory map的方式映射更大的文件到进程虚拟地址空间中,从而提高IO的效率。
通过automatic event signaling机制,实现高性能低功耗的spinlock。
提供31个64位通用寄存器,可减少对栈的使用,减少访存的频率,从而提升性能。在ARMv7体系结构的AAPCS(ARM Architecture Procedure Call Standard)中,前4个参数使用寄存器传递,大于4个的参数部分需要使用栈传递,也就是需要访问内存。而在ARMv8体系结构中,可以使用寄存器传递前8个参数,从而减少了对栈的使用。
提供基于PC寄存器±4GB的相对寻址范围,提高了相对寻址效率,可以提升动态库和位置无关代码的执行效率。
支持16KB & 64KB的分页粒度,可以减少页表级数,同时提高TLB命中率。
全新的异常处理模型,更加利于操作系统和虚拟化的实现。
设计了全新的Load-Acquire和Store-Release指令,在线程安全的代码中,不再需要显式的内存屏障指令,从而提升了性能。
3)ARMv8寄存器
(1)通用寄存器
AArch64执行状态支持31个64位通用寄存器(X0~X30),AArch32状态支持16个32位通用寄存器。
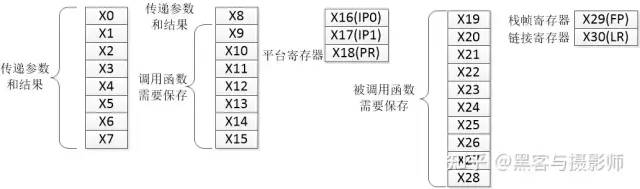
通用寄存器
(2)状态寄存器
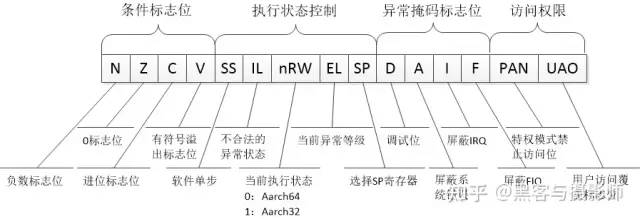
状态寄存器
(3)特殊寄存器
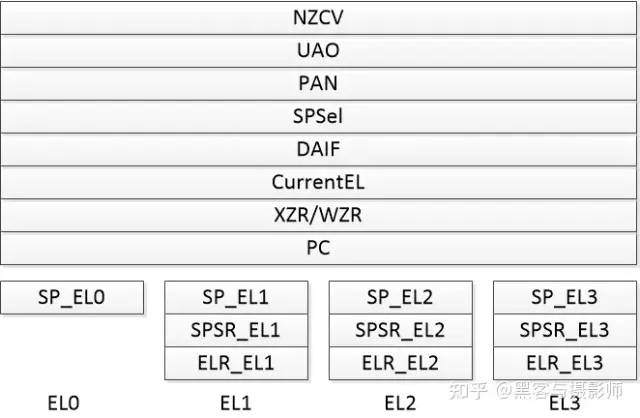
特殊寄存器
当运行异常处理程序时,处理器会把PSTATE寄存器的值暂时保存在SPSR(Saved Program Status Register,SPSR)里。当异常处理完返回时,再把SPSR的值恢复到PSTATE寄存器。
(4)系统寄存器
通过访问和设置这些系统寄存器,来完成对处理器不同的功能配置。ARMv8支持7类系统寄存器:
通用系统控制寄存器
调试寄存器
性能监控寄存器
活动监控寄存器
统计扩展寄存器
RAS寄存器
通用定时器寄存器
系统寄存器支持不同的异常等级访问,具体的访问规则如下:
Reg_EL1:处理器处于EL1、EL2、EL3时,都可以访问该寄存器。
Reg_EL2:处理器处于EL2、EL3时,可以访问寄存器。
大部分系统寄存器不支持处理器处于EL0时访问,但也有例外,比如CTR_EL0。
通过MSR、MRS指令访问系统寄存器。
1 综述
本文描述了Armv8-A AArch64的虚拟化支持。包括stage 2页表转换,虚拟异常,以及陷阱。本文介绍了一些基础的硬件辅助虚拟化理论以及一些Hypervisor如何利用这些虚拟化特性的例子。文本不会讲述某一具体的Hypervisor软件是如何工作的以及如何开发一款Hypervisor软件。通过阅读本文,你可以学到两种类型的Hypervisor以及它们是如何映射到Arm的异常级别。你将能解释陷阱是如何工作的以及其是如何被用来进行各种模拟操作。你将能描述Hypervisor可以产生什么虚拟异常以及产生这些虚拟异常的机制。理解本文内容需要一定基础,本文假定你熟悉ARMv8体系结构的异常模型和内存管理。 1.1 虚拟化简介 这里我们将介绍一些基础的Hypervisor和虚拟化的理论知识。如果你已经有一定的基础或是已经熟悉了这些概念,可以跳过这部分内容。我们用Hypervisor这个词来定义一种负责创建,管理以及调度虚拟机(Virtual Machines, VMs)的软件。
虚拟化为什么重要
虚拟化是一种在现代云计算和企业基础架构中广泛使用的技术。开发人员用虚拟机在一个硬件平台上运行多个不同的操作系统来开发和测试软件,以避免对主计算环境造成可能的破坏。虚拟化技术在服务器上非常流行,大多数面向服务器的处理器都需要支持虚拟化功能,这是因为虚拟化能给数据中心服务器带来如下一些需要的特性:
隔离:利用虚拟化可以对同一个物理核上运行的虚拟机进行隔离。这使得相互间不可信的的计算环境可以共享同一套硬件环境。例如,两个竞争对手可以共享同一个物理机器而又不能访问对方的数据。
高可用性:虚拟化可以在不同的物理机器之间无缝透明地迁移负载。这个技术广泛用于将负载从出错的硬件平台迁移至其他可用平台,以便维护和替换出错的硬件而不影响服务。
负载均衡:为了降低数据中心硬件和功耗成本,需要尽可能充分地利用硬件平台资源。将负载均衡地迁移到不同地物理机上,有利用充分利用物理机资源,降低功耗,同时为租户提供最佳性能。
沙箱:虚拟机可以作为一个沙箱来为运行在其中的应用屏蔽其他软件的干扰,或者避免其干扰其他软件。例如在虚拟机中运行特定软件,可以避免该软件的bug或病毒导致物理机器上的其他软件损坏。
1.2 Hypervisor的两种类型
Hypervisor通常被分成两种类型,独立类型Type 1和寄生类型 Type 2。我们先看看Type 2类型的Hypervisor。对于Type 2类型的Hypervisor,其寄生的宿主操作系统拥有对硬件平台和资源(包括CPU和物理内存…)的全部控制权。下图展示了Type 2类型的Hypervisor。
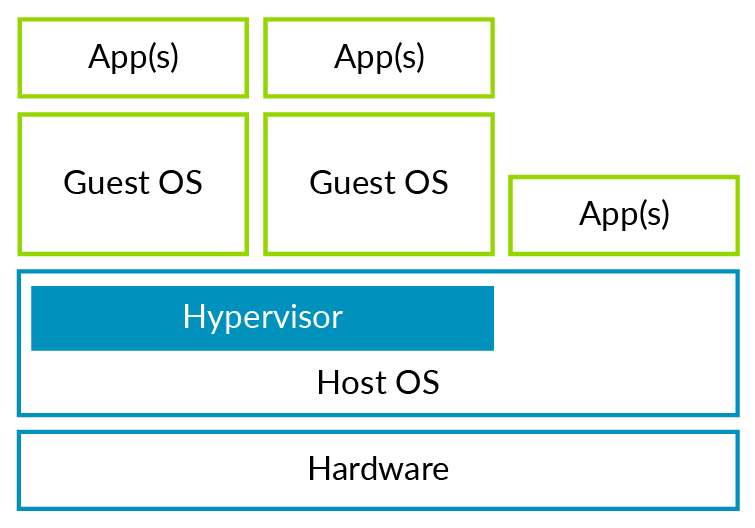
图1:Type 2 Hypervisor 宿主操作系统,指的是直接运行在硬件平台上并为Type 2类型的Hypervisor提供运行环境的操作系统。这类Hypervisor可以充分利用宿主操作系统对物理硬件的管理功能,而Hypervisor只需提供虚拟化相关功能即可。不知你是否使用过Virtual Box或是VMware Workstation, 这类软件就是Type 2类型的Hypervisor。 接下来,看看独立类型的Type 1 Hypervisor, 如图2。这类Hypervisor没有宿主操作系统。其直接运行在物理硬件之上,直接管理各种物理资源,同时管理并运行客户机操作系统。
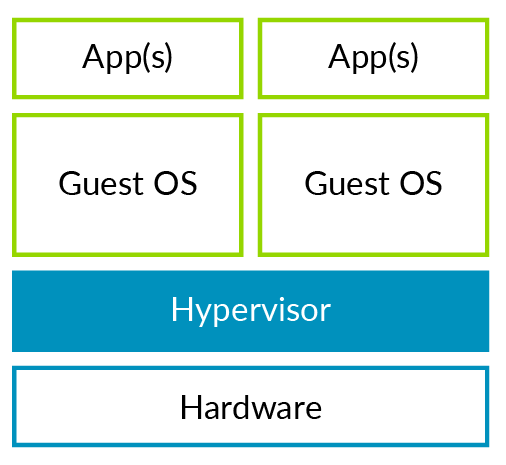
图2:Type 1 Hypervisor 在开源社区常见的Hypervisor, Xen (Type 1) 和 KVM (Type 2)就分属这两种不同的类型。其他开源的或知识产权的Hypervisor,可参见WiKi。
1.3 全虚拟化和半虚拟化
关于虚拟机,经典定义是:虚拟机是一个独立的隔离的计算环境,这种计算环境让使用者看起来就像在使用真实的物理机器一样。尽管我们可以在基于ARM的硬件平台上模拟真实硬件,但这通常不是最有效的做法,因此我们常常不这么做。例如,模拟一个真实的以太网设备是非常慢的,这是因为对任何一个模拟寄存器的访问都会陷入到Hypervisor当中进行模拟。比起直接访问物理寄存器来说,这种操作的代价要昂贵得多。一个替代方案是修改客户操作系统,使之意识到自身运行在虚拟机当中,通过在Hypervisor中模拟一个虚拟设备来给客户机使用。以此来换取更好得I/O性能。严格来说,全虚拟化需要完全模拟真实硬件,性能上会比较差。开源项目Xen推进了半虚拟化,通过修改客户机操作系统的核心部分使其更适合在虚拟环境中运行,以此来提高性能。 另一个使用半虚拟化的原因是早期的体系结构并不是为虚拟化而设计的,存在虚拟化漏洞。因为虚拟化要求所有敏感指令或访问敏感资源的指令都能被截获模拟。对于存在虚拟化漏洞的体系结构,则需要通过半虚拟化的方案来填补漏洞。而今,大多数体系机构都支持硬件辅助虚拟化,包括Arm。这使得操作系统的核心部分无需修改也能获得较好得性能。只有少数存储和网络相关的I/O设备仍然采用半虚拟化的方案来改善性能,这类半虚拟化的方案如,virtio 和 Xen PV Bus。
1.4 虚拟机(VM)和虚拟CPU (vCPU)
有必要区分虚拟机(VM)和虚拟CPU(vCPU)。这有利于理解本文的后续部分。例如,一个内存页面可以分配给一个虚拟机,因此所有属于该VM的vCPUs都可以访问它。而一个虚拟中断只是针对某个vCPU,因此只有该vCPU可以收到。虚拟机(VM)和虚拟CPU(vCPU)的关系如图3所示。
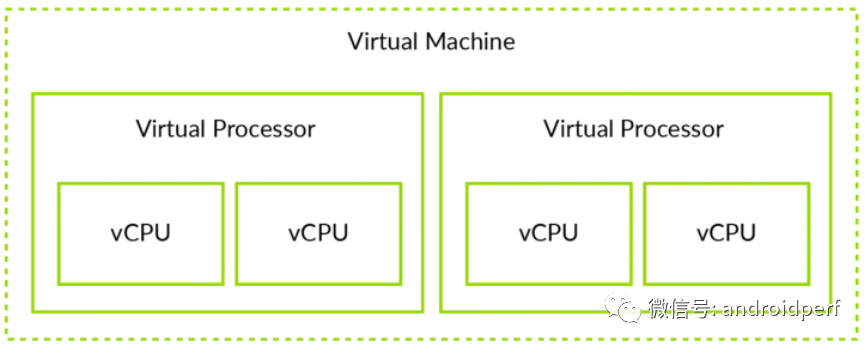
图3:VM vs vCPU 注意:ARM体系结构定义了处理单元(Processing Element, PE)一词,现代CPU可能包含多个内核或线程,PE用来指代单一的执行单元。同样的这里的vCPU严格来说应该是vPE。
2 AArch64的虚拟化
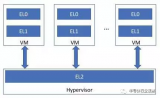
对于ARMv8, Hypervisor运行在EL2异常级别。只有运行在EL2或更高异常级别的软件才可以访问并配置各项虚拟化功能。
Stage 2转换
EL1/0指令和寄存器访问
注入虚拟异常
安全状态和非安全状态下的异常级别及可运行的软件如图4所示
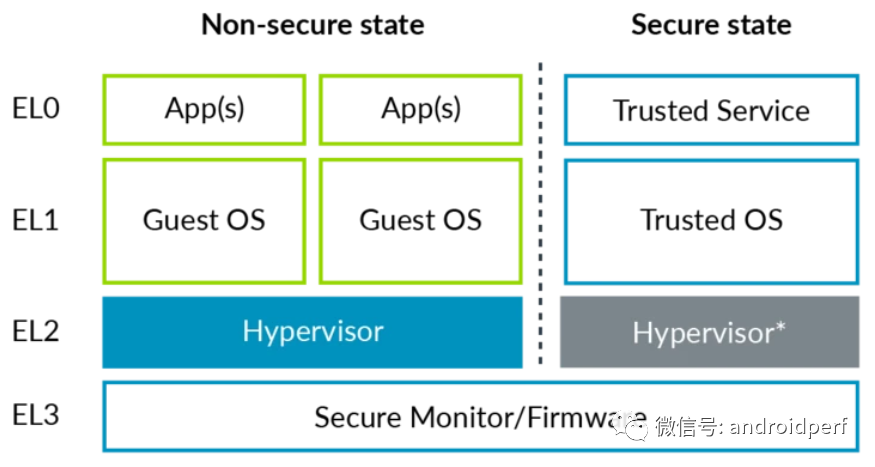
图4:AArch64的虚拟化 注意:安全状态的EL2用灰色显示是因为,安全状态的EL2并不总是可用,这是Armv8.4-A引入的特性。
2.1 Stage 2 转换
什么是Stage 2 转换
Stage 2 转换允许Hypervisor控制虚拟机的内存视图。具体来说,其可以控制虚拟机是否可以访问特定的某一块物理内存,以及该内存块出现在虚拟机内存空间的位置。这种能力对于虚拟机的隔离和沙箱功能来说至关重要。这使得虚拟机只能看到分配给它自己的物理内存。为了支持Stage 2 转换, 需要增加一个页表,我们称之为Stage 2页表。操作系统控制的页表转换称之为stage 1转换,负责将虚拟机视角的虚拟地址转换为虚拟机视角的物理地址。而stage 2页表由Hypervisor控制,负责将虚拟机视角的物理地址转换为真实的物理地址。虚拟机视角的物理地址在Armv8中有特定的词描述,叫中间物理地址(intermediate Physical Address, IPA)。 stage 2转换表的格式和stage 1的类似,但也有些属性的处理不太一样,例如,判断内存类型 是normal 还是 device的信息被直接编码进了表里,而不是通过查询MAIR_ELx寄存器。
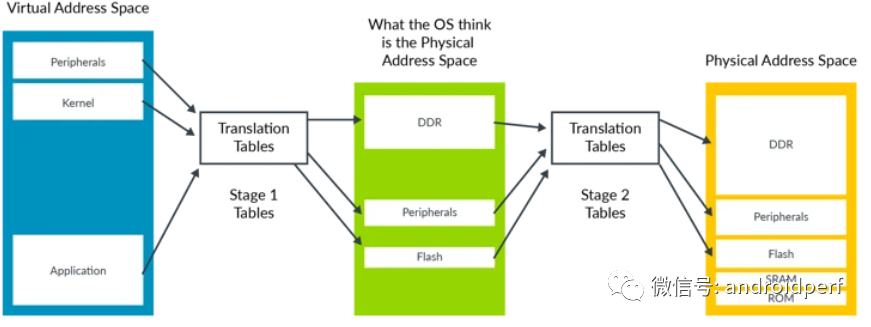
图5:地址转换, VA to IPA to PA
VMID
每一个虚拟机都被分配一个ID号,称之为VMID。这个ID号用于标记某个特定的TLB项属于哪一个VM。VMID使得不同的VM可以共享同一块TLB缓存。VMID存储在寄存器VTTBR_EL2中,可以是8或16比特,由VTCR_EL2.vs比特位控制,其中16比特的VMID支持是在armv8.1-A中扩展的,是可选的。需注意,EL2和EL3的地址转换不需要VMID标记,因为它们不需要stage 2转换。
VMID vs ASID
TLB项也可以用ASID(Address Space Identifier)标记,每个应用都被操作系统分配有一个ASID,所有属于同一个应用的TLB项都有相同的ASID。这使得不同应用可以共享同一块TLB缓存。每一个VM有它自己的ASID空间。例如两个不同的VMs同时使用ASID 5,但指的是不同的东西。对于虚拟机而言,通常VMID会结合ASID同时使用。
属性整合和覆盖
stage 1 和 stage 2映射都包含属性,例如存储类型,访问权限等。内存管理单元(MMU)会将两个阶段的属性整合成一个最终属性,整合的原则是选择更有限制的属性。且看如下例子:
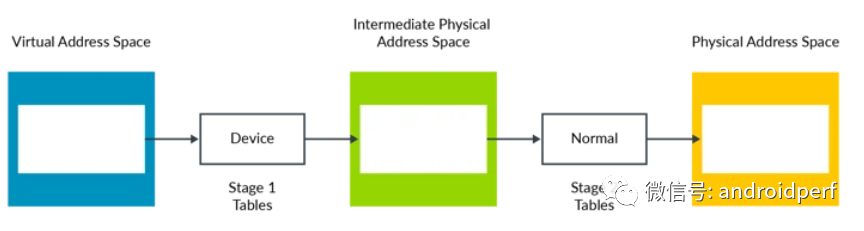
图6:映射属性整合 在上面的例子中,Device属性比起Normal属性更具限制性,因此最终结果是Device属性。同样的原理,如果你将顺序调换一下也不会改变最终的属性。 属性整合在大多数情况下都可以工作。但有些时候,例如在VM的早期启动阶段,Hypervisor希望改变默认的行为,则可以通过如下寄存器比特来实现。
HCR_EL2.CD: 控制所有stage 1属性为Non-cacheable。
HCR_EL2.DC:强制所有stage 1属性为Normal,Write-Back Cacheable。
HCR_EL2.FWB (Armv8.4-A引入):使用stage 2属性覆盖stage 1属性,而不是使用默认的限制性整合原则。
模拟MMIO
与物理机器的物理地址空间类似,VM的IPA地址空间包含了内存与外围设备两种区域。如下图所示

图7:模拟MMIO VM使用外围设备区域来访问其看到的物理外围设备,这其中包含了直通设备和虚拟外围设备。虚拟设备完全由Hypervisor模拟,如下图所示
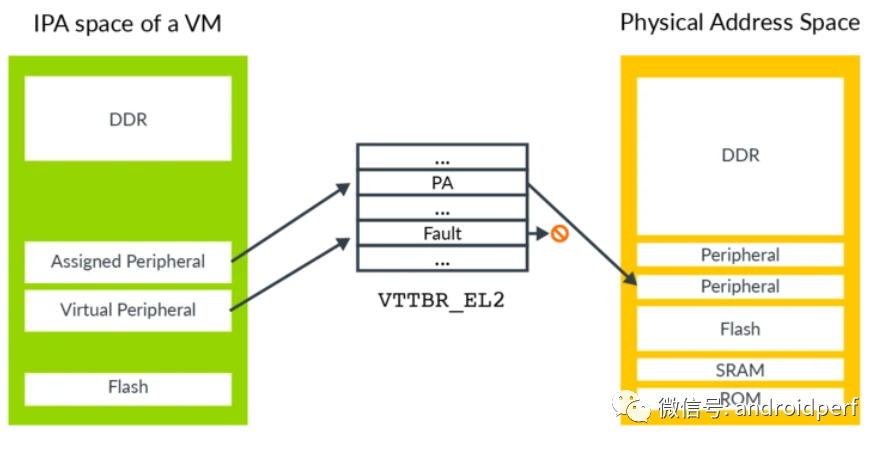
图8:stage 2映射 一个直通设备被直接分配给VM并映射到IPA地址空间,这使得VM中的软件可用直接访问真实的物理硬件。一个虚拟的外围设备由Hypervisor模拟,其stage 2的转换项被标记为fault。虽然VM中的软件看来其是直接与物理设备交互,但实际上这一访问会导致stage 2转换fault,从而进入相应的异常处理程序由Hypervisor模拟。 为了模拟一个外围设备,Hypervisor需要知道哪一个外围设备被访问,外围设备的哪一个寄存器被访问,是读访问还是写访问,访问长度是多少,以及使用哪些寄存器来传送数据。 当处理stage 1 faults时,FAR_ELx寄存器包含了触发异常的虚拟地址。但虚拟地址不是给Hypervisor用的,Hypervisor通常不会知道客户操作系统如何配置虚拟地址空间的映射。对于stage 2 faults,有一个专门的寄存器HPFAR_EL2,该寄存器会报告发生错误的IPA地址。IPA地址空间由Hypervisor控制,因此可用利用此寄存器里的信息来进行必要的模拟。 ESR_ELx寄存器用于报告发生异常的相关信息。当loads或stores一个通用寄存器触发stage 2 fault时,相关异常信息由这些寄存器提供。这些信息包含了,访问的长度,访问的原地址或目的地址。Hypervisor可以以此来判断对虚拟外围设备访问的权限。下图展示了一个陷入(trapping) – 模拟(emulating)的访问过程。
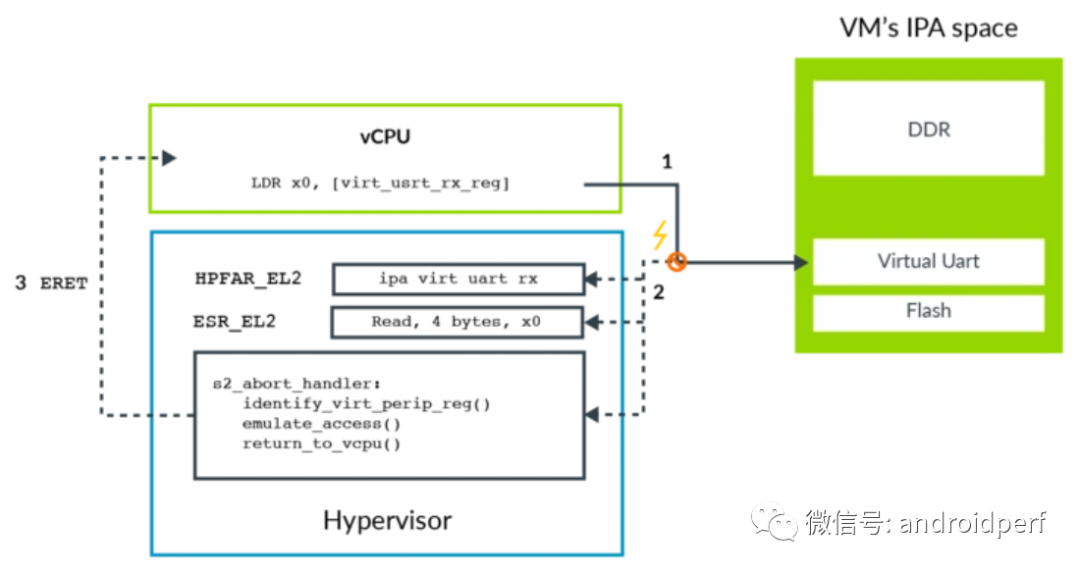
图9:外围设备模拟
VM里的软件尝试访问虚拟外围设备,这个例子当中是虚拟UART的接收FIFO。
该访问被stage 2转换block住,导致一个abort异常被路由到EL2。
异常处理程序查询ESR_EL2关于异常的信息,如访问长度,目的寄存器,是load还是store操作。
异常处理程序查询HPFAR_EL2,取得发生abort的IPA地址。
Hypervisor通过ESR_EL2和HPFAR_EL2里的相关信息对相关虚拟外围设备作模拟,模拟完成后通过ERET指令返回vCPU,并从发生异常的下一条指令继续执行。
系统内存管理单元(System Memory Management Units, SMMUs)
到目前为止,我们只考虑了从处理器发起的各种访问。我们还需要考虑其他主设备如DMA控制器发起的访问。我们需要一种方法来扩展stage 2映射以保护这些主设备的地址空间。如果一个DMA控制器没有使用虚拟化,那它看起来应该如下图所示
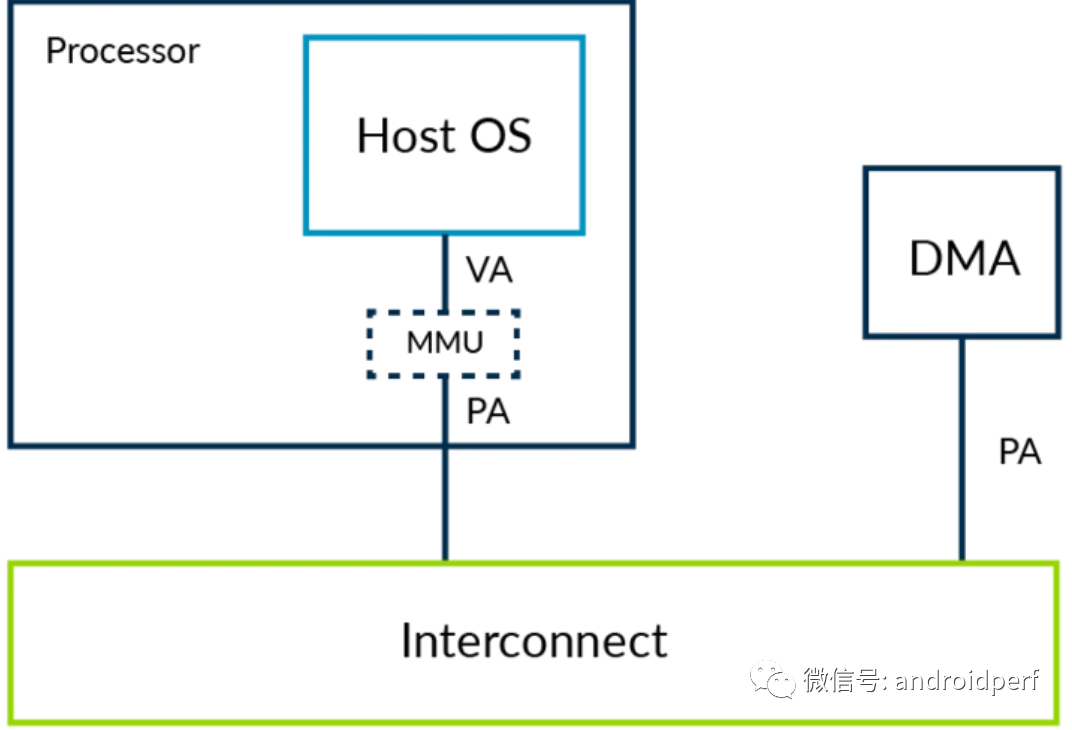
图10:没有虚拟化的DMA访问 DMA控制器通常由内核驱动编程控制。内核驱动会确保不违背操作系统层面的内存保护原则,即一个应用不能使用DMA访问其没有权限访问的其他应用的内存。 下面让我们考虑操作系统运行在虚拟机中的场景。
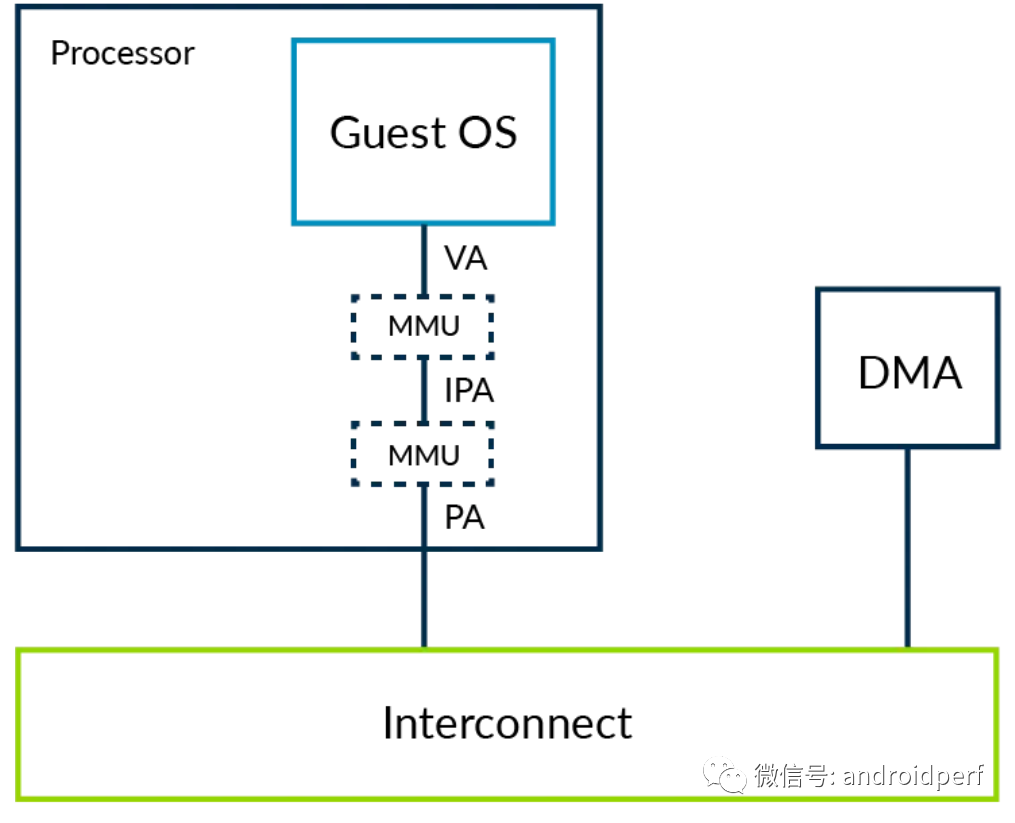
图11:虚拟化下没有SMMU的DMA访问 在这个系统中,Hyperviosr通过stage 2映射来隔离不同VMs的地址空间。这是基于Hypervisor控制的stage 2映射表实现的。而驱动则直接与DMA控制器交互,这会产生两个问题:
隔离:DMA控制器访问在虚拟机之间没有了隔离,这破坏了虚拟机的沙箱功能。
地址空间:利用两级映射转换,使内核看到的PAs实际上是IPAs。但DMA控制器看到的仍然是PAs。因此DMA控制器和内核看到的是不同的地址空间,为了解决这个问题,每当VM与DMA控制器交互时就需要陷入到Hypervisor中做必要的转换。这种处理方式是极其没有效率的,且容易出错。
解决的办法是将stage 2的机制推广到DMA控制器。这么做的话,这些主设备控制器也需要一个MMU,Armv8称之为SMMU(通常也称为IOMMU)。
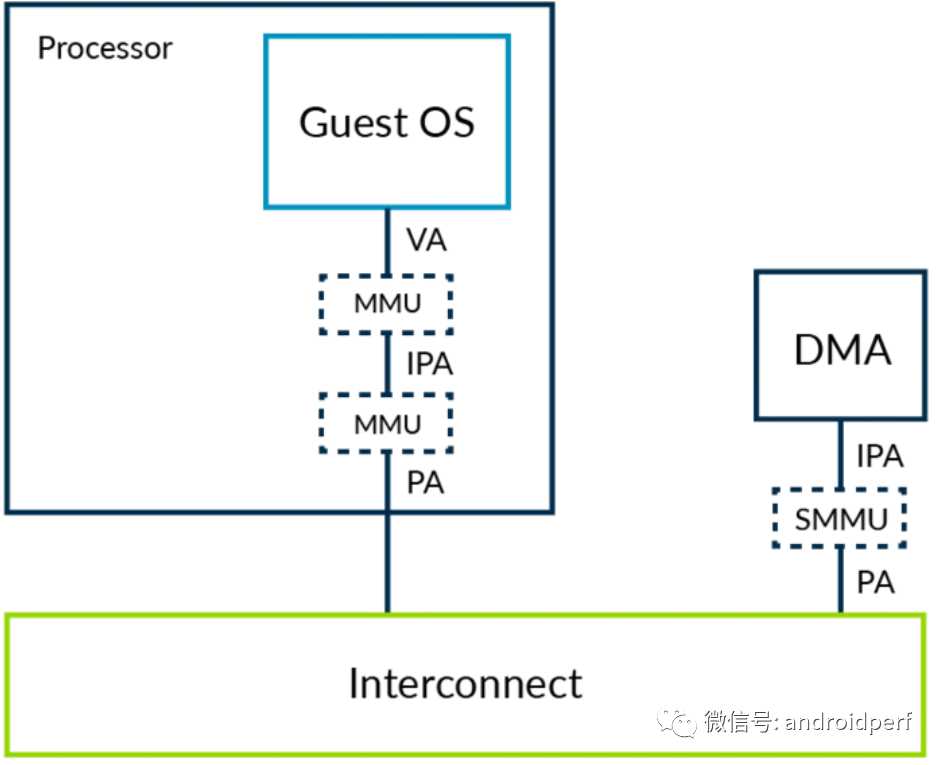
图12:虚拟化下通过SMMU的DMA访问 Hypervisor负责配置SMMU,以使DMA控制器看到的物理地址空间与kenrel看到的物理地址空间相同。这样就能解决上述两个问题。 转自:https://calinyara.github.io/technology/2019/11/03/armv8-virtualization.html 相关文章:
-
寄存器
+关注
关注
31文章
5622浏览量
130589 -
架构
+关注
关注
1文章
537浏览量
26661 -
ARMv8
+关注
关注
1文章
37浏览量
14748
原文标题:收藏:Arm v8架构及虚拟化介绍
文章出处:【微信号:架构师技术联盟,微信公众号:架构师技术联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
ARM公司公开下一代ARM架构技术细节
ARM重新定义ARMv8新架构,ARMv8新架构特性解说
ARM-v8架构分析
基于ARMv7架构的Cortex系列
ARMv8架构编程之内存管理单元探索
ARMv8架构的两种执行状态分别是什么
ARMv8架构概述
NEON在armv8(arch64)下如何去使用呢
ARM推新品:ARMv8首次支援64位元指令集
64位ARMv8架构交易敲定 ARM助力Cavium进军新领域
TRACE32支持ARMv8架构
从软件开发的角度概述ARMv8处理器架构中的虚拟化操作
ARMv8处理器体系结构中的虚拟化功能



评论