 大数据的4v特征有哪些 大数据技术包括哪些技术
大数据的4v特征有哪些 大数据技术包括哪些技术
大数据的4v特征有哪些
大数据的4V特征是指数据的特点,主要包括以下四个方面:
1. Volume(数据量):所谓大数据,就是指数据量达到了一定的规模大小,通常需要使用分布式系统和算法进行处理和分析。数据的增长速度非常快,而且数据的来源和种类也更加多样化。
2. Velocity(处理速度):大数据通常需要快速处理和分析,这就需要使用高效的分布式系统和并行算法来快速处理数据。如Hadoop、Spark等分布式处理框架可以有效地解决大数据的处理速度问题。
3. Variety(数据种类):大数据的来源非常广泛,数据的种类也非常丰富,包括结构化数据、非结构化数据、半结构化数据、时间序列数据等等。这些数据需要使用不同的技术进行处理和分析。
4. Veracity(数据准确性):由于数据来源和种类的多样性,大数据的准确性也成为一项关键的挑战。针对数据质量的问题,需要采用有效的数据清洗和校验方案,确保在大数据分析和决策中使用的数据具有高度的准确性和可靠性。
综上所述,大数据的4V特征是指数据量大、处理速度快、数据种类丰富、数据准确性高的特点。在大数据的处理和分析过程中,需要采用有效的技术方案和方法,以便更好地挖掘数据的价值。
大数据技术包括哪些技术
1、大数据收集
数据的收集就是从数据源中把数据采集和存储到数据存储上。而数据源主要包括Flume NG、NDC,Netease Data Canal、Logstash2、Sqoop、Strom集群结构、Zookeeper等。
2、大数据的存储
采集到大量复杂信息后,就需要有一个存储的数据库。大数据存储,指用存储器,以数据库的形式,存储采集到的数据的过程,主要包括有Hadoop、HBase、Phoenix、Yarn、Mesos、Redis、Atlas、Kudu等,不同的存储数据库可适用于不同类型的数据。
3、大数据的清洗
随着业务数据量的增多,需要进行训练和清洗的数据会变得越来越复杂,这个时候就需要任务调度系统,比如oozie或者azkaban,对关键任务进行调度和监控。
4、大数据的查询分析
如何将这些庞大复杂的数据整合成我们所需要的信息呢?这就涉及到了数据的分析处理,主要会用到这些程序,如Hive、Impala、Spark、Nutch、Solr、Elasticsearch等。
5、大数据的可视化分析
何为可视化分析,就是指借助图形的方式,清楚并高效率的传送信息的分析手段。主要应用于庞大的数据关联分析,就是借助分析平台,对那些相对分散看似没用的信息进行关联分析,并得出完整的分析图表并用于指导决策服务的过程。主流的BI平台有如国外的敏捷BI Tableau、Qlikview、PowrerBI等,国内的SmallBI和新兴的网易有数等。
6、大数据挖掘
其实有关数据挖掘的算法非常多,而且不一样的算法适用于不同的数据类型,那么得出的数据特点也会不一样。但是通常情况下,创建模型的过程是很类似的,就是一开始要分析用户提供的数据,接着开始查找,不一样的类型模式有不一样的查询方式,然后分析结果得出模型的最佳参数,并将这些参数都应用在整个数据集,即可提取详细的统计信息
7、模型预测
大数据采集到后,除了能够通过分析计算反应过去和当前的信息情况,还可以通过建立科学的数据模型,通过模型得出新的数据,预测将来会发生的事情,从而提前做出应对政策。
8、结果呈现
再好的数据分析结论如果没有一个好的呈现方式,那么也是在做无用功,利用大数据分析得出的结论可以通过不用的方式呈现。如云计算、标签云等。借助云计算,可以完成对大数据的统一管理和实时高效的分析,最大限度的挖掘数据的价值,让大数据的意义发挥到最佳效果。标签云是一些列相关联的标签以及以此相对应的权重,比较典型的标签云有30-150个左右的标签,而权重是影响使用的字体大小或其他视觉呈现效果。
-
存储
+关注
关注
13文章
4353浏览量
86118 -
数据采集
+关注
关注
39文章
6245浏览量
113974 -
大数据
+关注
关注
64文章
8908浏览量
137721
发布评论请先 登录
相关推荐
缓存对大数据处理的影响分析
大数据的3V、4V、7V,到底是什么意思?

ADS1675最大数据吞吐率是是多少?
raid 在大数据分析中的应用
智慧城市与大数据的关系
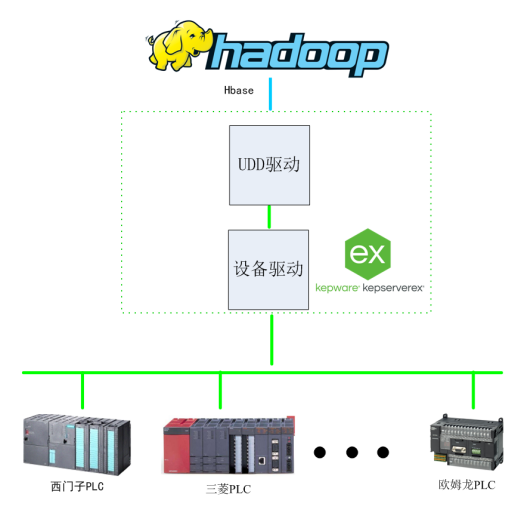
基于Kepware的Hadoop大数据应用构建-提升数据价值利用效能
使用CYW20829的BLE进行最大数据发送应用,BLE丢失数据如何解决?
大数据在军事方面的应用
大数据采集系统分为几类
大数据在军事方面的应用有哪些
大数据在军事训练领域的应用有哪些
大数据在部队管理中的运用有哪些
CYBT-343026传输大数据时会丢数据的原因?
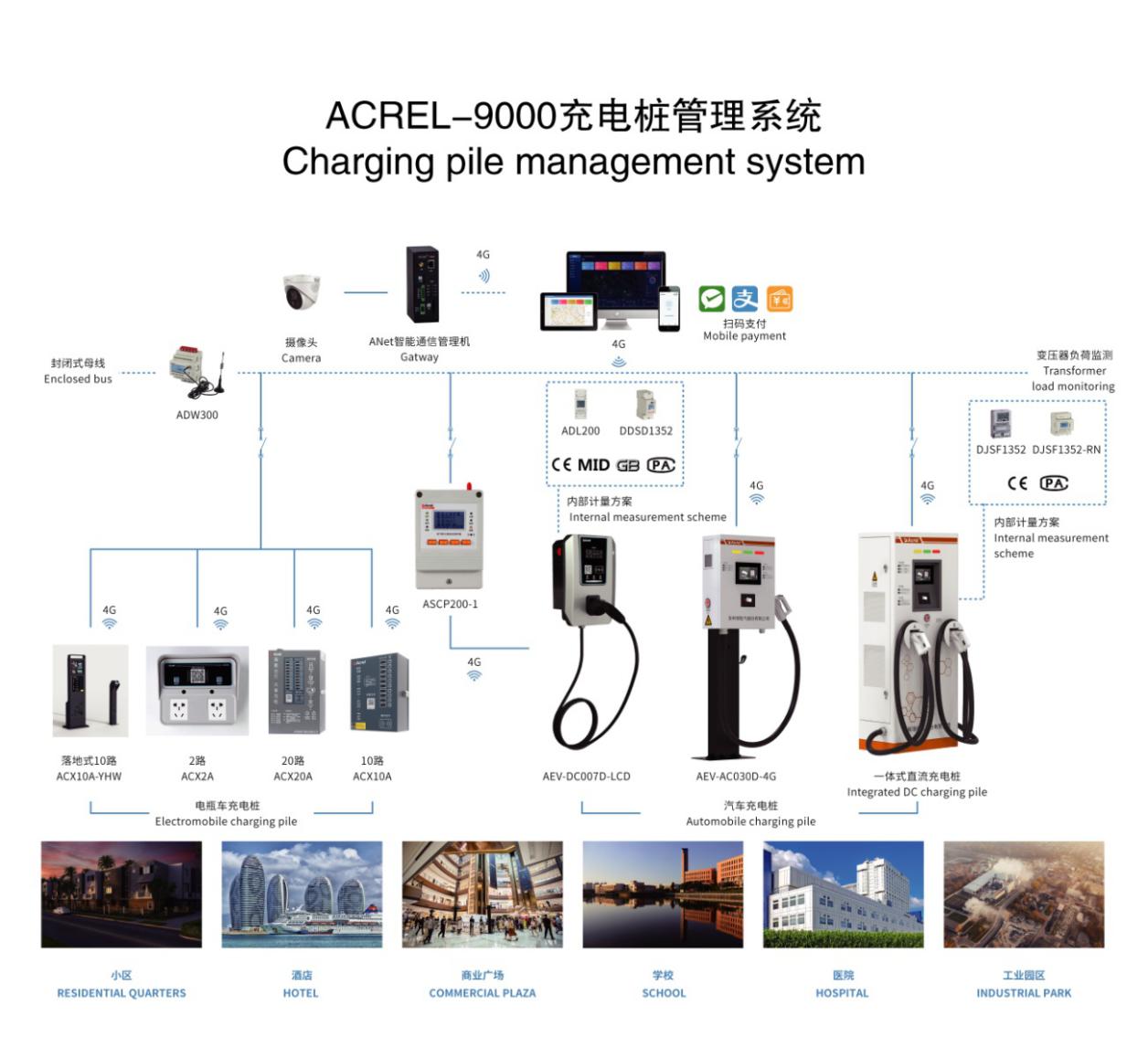
简析大数据技术下智能充电桩在网络系统中的应用





 工商网监
工商网监
评论