 正则化方法DropKey: 两行代码高效缓解视觉Transformer过拟合
正则化方法DropKey: 两行代码高效缓解视觉Transformer过拟合
美图影像研究院(MT Lab)与中国科学院大学突破性地提出正则化方法 DropKey,用于缓解 Vision Transformer 中的过拟合问题。该方法通过在注意力计算阶段随机 drop 部分 Key 以鼓励网络捕获目标对象的全局信息,从而避免了由过于聚焦局部信息所引发的模型偏置问题,继而提升了基于 Transformer 的视觉类算法的精度。该论文已被计算机视觉三大顶会之一 CVPR 2023 接收。
近期,基于 Transformer 的算法被广泛应用于计算机视觉的各类任务中,但该类算法在训练数据量较小时容易产生过拟合问题。现有 Vision Transformer 通常直接引入 CNN 中常用的 Dropout 算法作为正则化器,其在注意力权重图上进行随机 Drop 并为不同深度的注意力层设置统一的 drop 概率。尽管 Dropout 十分简单,但这种 drop 方式主要面临三个主要问题。
首先,在 softmax 归一化后进行随机 Drop 会打破注意力权重的概率分布并且无法对权重峰值进行惩罚,从而导致模型仍会过拟合于局部特定信息(如图 1)。其次,网络深层中较大的 Drop 概率会导致高层语义信息缺失,而浅层中较小的 drop 概率会导致过拟合于底层细节特征,因此恒定的 drop 概率会导致训练过程的不稳定。最后,CNN 中常用的结构化 drop 方式在 Vision Transformer 上的有效性并不明朗。
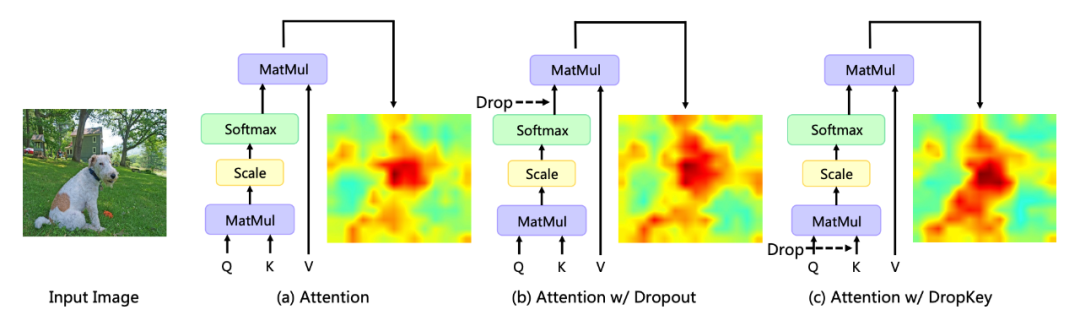
▲图1. 不同正则化器对注意力分布图的影响 美图影像研究院(MT Lab)与中国科学院大学在 CVPR 2023 上发表了一篇文章,提出一种新颖且即插即用的正则化器 DropKey,该正则化器可以有效缓解 Vision Transformer 中的过拟合问题。

论文链接:https://arxiv.org/abs/2208.02646
文章中对以下三个核心问题进行了研究:
第一,在注意力层应该对什么信息执行 Drop 操作?与直接 Drop 注意力权重不同,该方法在计算注意力矩阵之前执行 Drop 操作,并将 Key 作为基础 Drop 单元。该方法在理论上验证了正则化器 DropKey 可以对高注意力区域进行惩罚并将注意力权值分配到其它感兴趣的区域,从而增强模型对全局信息的捕获能力。
第二,如何设置 Drop 概率?与所有层共享同一个 Drop 概率相比,该论文提出了一种新颖的 Drop 概率设置方法,即随着自注意力层的加深而逐渐衰减 Drop 概率值。
第三,是否需要像 CNN 一样进行结构化 Drop 操作?该方法尝试了基于块窗口和交叉窗口的结构化 Drop 方式,并发现这种技巧对于 Vision Transformer 来说并不重要。
背景
Vision Transformer(ViT)是近期计算机视觉模型中的新范式,它被广泛地应用于图像识别、图像分割、人体关键点检测和人物互相检测等任务中。具体而言,ViT 将图片分割为固定数量的图像块,将每个图像块都视作一个基本单位,同时引入了多头自注意力机制来提取包含相互关系的特征信息。但现有 ViT 类方法在小数据集上往往会出现过拟合问题,即仅使用目标局部特征来完成指定任务。
为了克服以上问题,该论文提出了一种即插即拔、仅需要两行代码便可实现的正则化器 DropKey 用以缓解 ViT 类方法的过拟合问题。不同于已有的 Dropout,DropKey 将 Key 设置为 drop 对象并从理论和实验上验证了该改变可以对高注意力值部分进行惩罚,同时鼓励模型更多关注与目标有关的其他图像块,有助于捕捉全局鲁棒特征。
此外,该论文还提出为不断加深的注意力层设置递减的 drop 概率,这可以避免模型过度拟合低级特征并同时保证有充足的高级特征以进行稳定的训练。此外,该论文还通过实验证明,结构化 drop 方法对 ViT 来说不是必要的。
DropKey
为了探究引发过拟合问题的本质原因,该研究首先将注意力机制形式化为一个简单的优化目标并对其拉格朗日展开形式进行分析。发现当模型在不断地优化时,当前迭代中注意力占比越大的图像块,在下次迭代过程中会倾向于被分配更大的注意力权值。为缓解这一问题,DropKey 通过随机 drop 部分 Key 的方式来隐式地为每个注意力块分配一个自适应算子以约束注意力分布从而使其变得更加平滑。
值得注意的是,相对于其他根据特定任务而设计的正则化器,DropKey 无需任何手工设计。由于在训练阶段对 Key 执行随机 drop,这将导致训练和测试阶段的输出期望不一致,因此该方法还提出使用蒙特卡洛方法或微调技巧以对齐输出期望。此外,该方法的实现仅需两行代码,具体如图 2 所示。

▲图2.DropKey实现方法
一般而言,ViT 会叠加多个注意力层以逐步学习高维特征。通常,较浅层会提取低维视觉特征,而深层则旨在提取建模空间上粗糙但复杂的信息。因此,该研究尝试为深层设置较小的 drop 概率以避免丢失目标对象的重要信息。具体而言,DropKey 并不在每一层以固定的概率执行随机 drop,而是随着层数的不断加深而逐渐降低 drop 的概率。此外,该研究还发现这种方法不仅适用于 DropKey,还可以显著提高 Dropout 的性能。
虽然在 CNN 中对结构化 drop 方法已有较为详细的研究,但还没有研究该 drop 方式对 ViT 的性能影响。为探究该策略会不会进一步提升性能,该论文实现了 DropKey 的两种结构化形式,即 DropKey-Block 和 DropKey-Cross。
其中,DropKey- Block 通过对以种子点为中心的正方形窗口内连续区域进行 drop,DropKey-Cross 则通过对以种子点为中心的十字形连续区域进行 drop,如图 3 所示。然而,该研究发现结构化 drop 方法并不会带来性能提升。
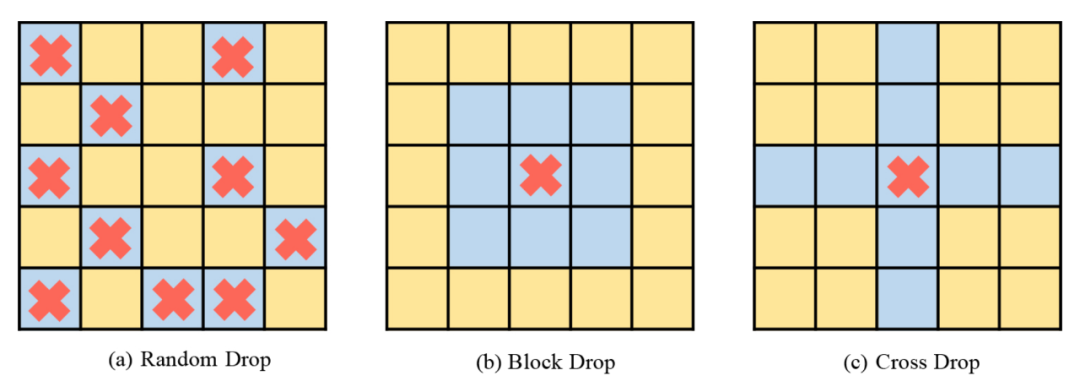
▲图3. DropKey的结构化实现方法
实验结果
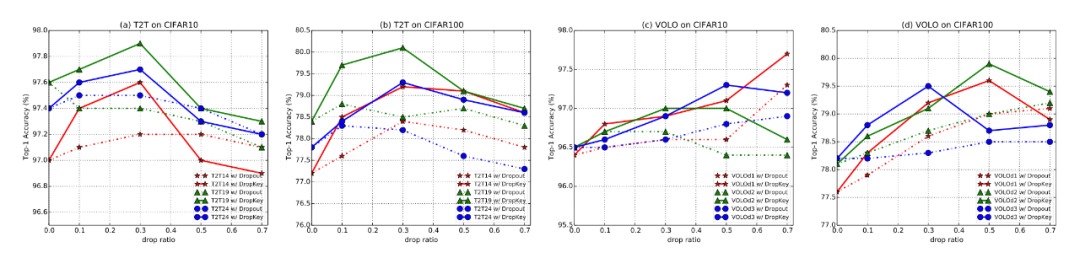
▲图4. DropKey和Dropout在CIFAR10/100上的性能比较

▲图5. DropKey和Dropout在CIFAR100上的注意力图可视化效果比较
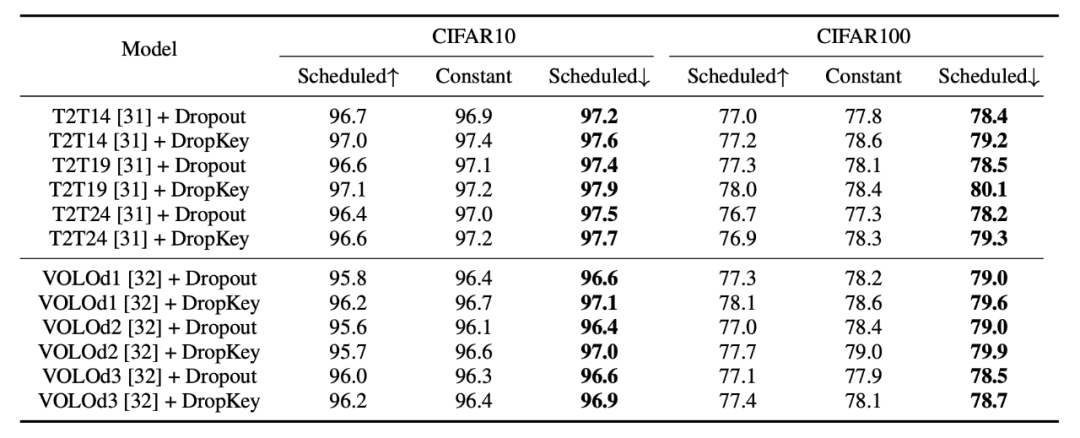
▲图6. 不同drop概率设置策略的性能比较
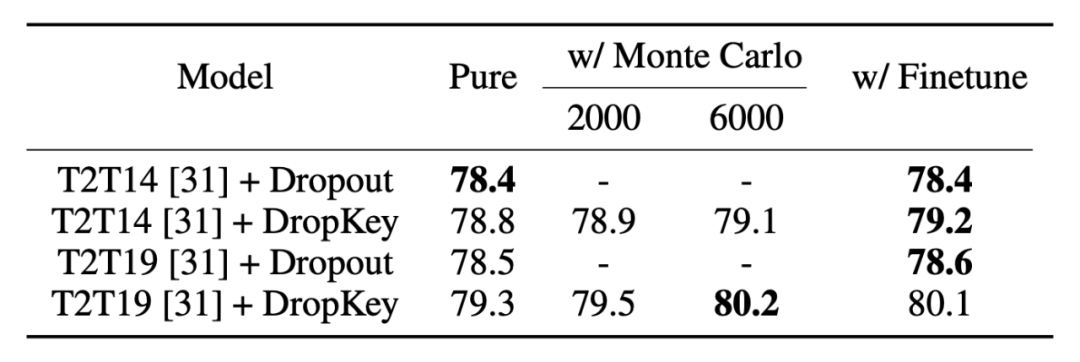
▲图7. 不同输出期望对齐策略的性能比较
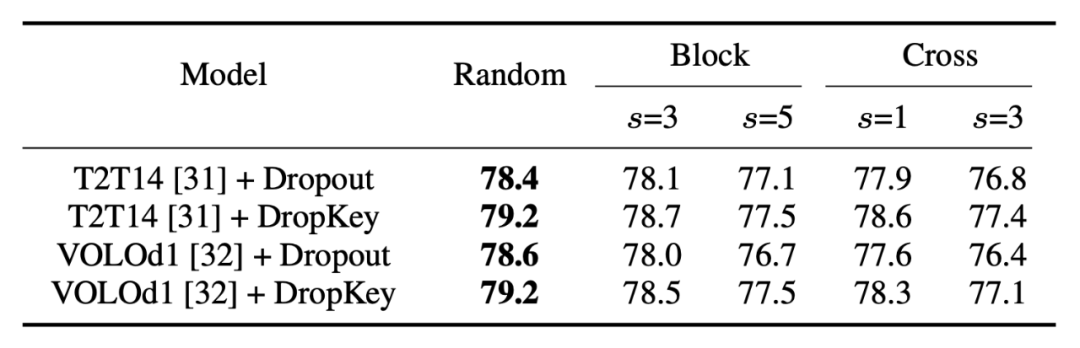
▲图8. 不同结构化drop方法的性能比较
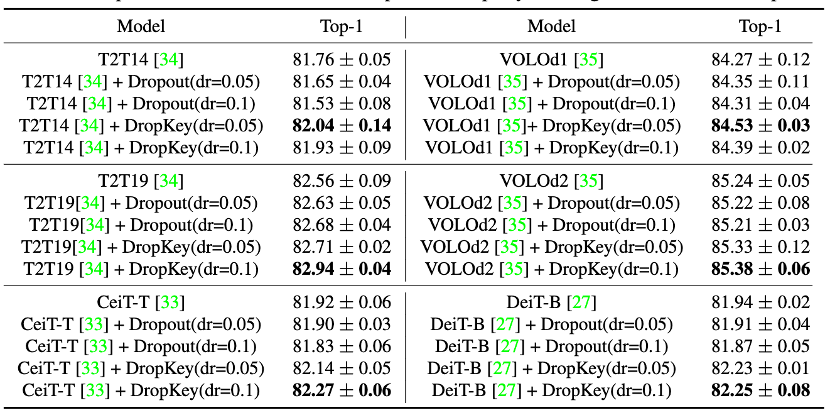
▲图9. DropKey和Dropout在ImageNet上的性能比较
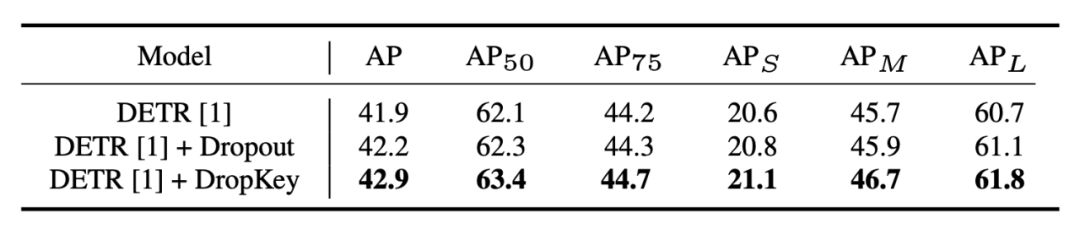
▲图10.DropKey和Dropout在COCO上的性能比较

▲图11.DropKey和Dropout在HICO-DET上的性能比较

▲图12.DropKey和Dropout在HICO-DET上的注意力图可视化比较
总结
该论文创新性地提出了一种用于 ViT 的正则化器,用于缓解 ViT 的过拟合问题。与已有的正则化器相比,该方法可以通过简单地将 Key 置为 drop 对象,从而为注意力层提供平滑的注意力分布。另外,该论文还提出了一种新颖的 drop 概率设置策略,成功地在有效缓解过拟合的同时稳定训练过程。最后,该论文还探索了结构化 drop 方式对模型的性能影响。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4610浏览量
92859 -
代码
+关注
关注
30文章
4786浏览量
68556 -
计算机视觉
+关注
关注
8文章
1698浏览量
45987
原文标题:CVPR 2023 | 正则化方法DropKey: 两行代码高效缓解视觉Transformer过拟合
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
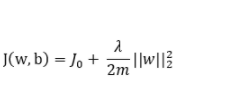
ucgui listbox显示不全 只有两行
过拟合的概念和用几种用于解决过拟合问题的正则化方法

【连载】深度学习笔记4:深度神经网络的正则化
权值衰减和L2正则化傻傻分不清楚?本文来教会你如何分清
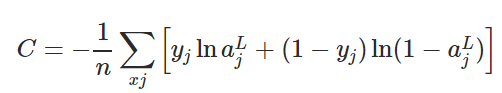
权值衰减和L2正则化傻傻分不清楚?
用于语言和视觉处理的高效 Transformer能在多种语言和视觉任务中带来优异效果

教你如何用两行代码搞定YOLOv8各种模型推理






 工商网监
工商网监
评论