 Segment Anything又能分辨类别了:Meta/UTAustin提出全新开放类分割模型
Segment Anything又能分辨类别了:Meta/UTAustin提出全新开放类分割模型
前几日,Meta 推出了「分割一切」AI模型Segment Anything,令网友直呼 CV 不存在了?!而在另一篇被CVPR 2023 收录的论文中,Meta、UTAustin 联合提出了新的开放语言风格模型(open-vocabulary segmentation, OVSeg),它能让 Segment Anything 模型知道所要分隔的类别。
从效果上来看,OVSeg 可以与 Segment Anything 结合,完成细粒度的开放语言分割。比如下图 1 中识别花朵的种类:sunflowers (向日葵)、white roses (白玫瑰)、 chrysanthemums (菊花)、carnations (康乃馨)、green dianthus (绿石竹)。

即刻体验:https://huggingface.co/spaces/facebook/ov-seg
项目地址:https://jeff-liangf.github.io/projects/ovseg/
研究背景
开放式词汇语义分割旨在根据文本描述将图像分割成语义区域,这些区域在训练期间可能没有被看到。最近的两阶段方法首先生成类别不可知的掩膜提案,然后利用预训练的视觉-语言模型(例如 CLIP)对被掩膜的区域进行分类。研究者确定这种方法的性能瓶颈是预训练的 CLIP 模型,因为它在掩膜图像上表现不佳。
为了解决这个问题,研究者建议在一组被掩膜的图像区域和它们对应的文本描述的收集的数据上对 CLIP 进行微调。研究者使用 CLIP 将掩膜图像区域与图像字幕中的名词进行匹配,从而收集训练数据。与具有固定类别的更精确和手动注释的分割标签(例如 COCO-Stuff)相比,研究者发现嘈杂但多样的数据集可以更好地保留 CLIP 的泛化能力。
除了对整个模型进行微调之外,研究者还使用了被掩膜图像中的「空白」区域,使用了他们称之为掩膜提示微调的方法。
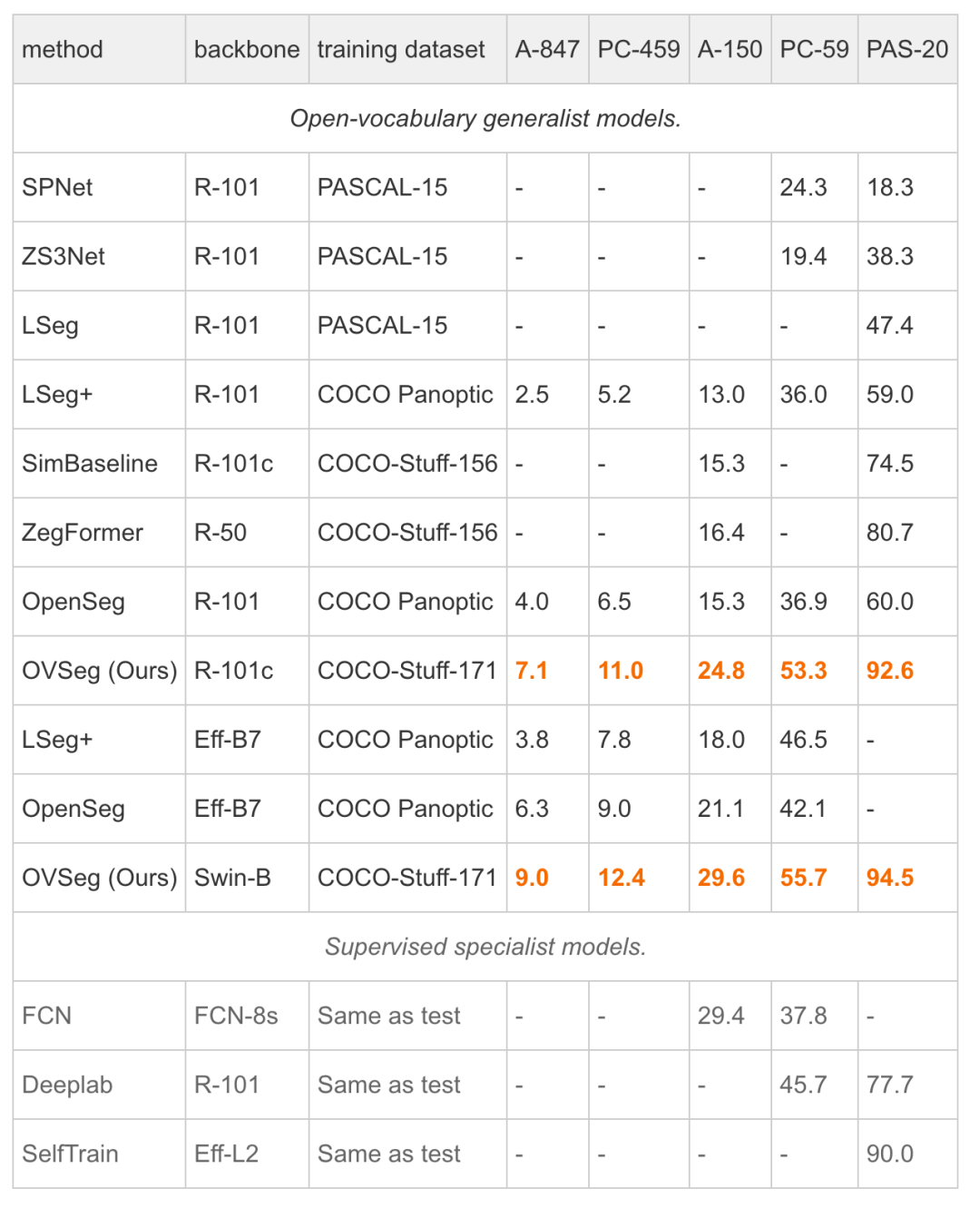
实验表明,掩膜提示微调可以在不修改任何 CLIP 权重的情况下带来显著的改进,并且它可以进一步改善完全微调的模型。特别是当在 COCO 上进行训练并在 ADE20K-150 上进行评估时,研究者的最佳模型实现了 29.6%的 mIoU,比先前的最先进技术高出 8.5%。开放式词汇通用模型首次与 2017 年的受监督专家模型的性能匹配,而不需要特定于数据集的适应。

论文地址:https://arxiv.org/pdf/2210.04150.pdf
论文解读
动机
研究者的分析表明,预训练的 CLIP 在掩膜建议上表现不佳,成为两阶段方法的性能瓶颈。
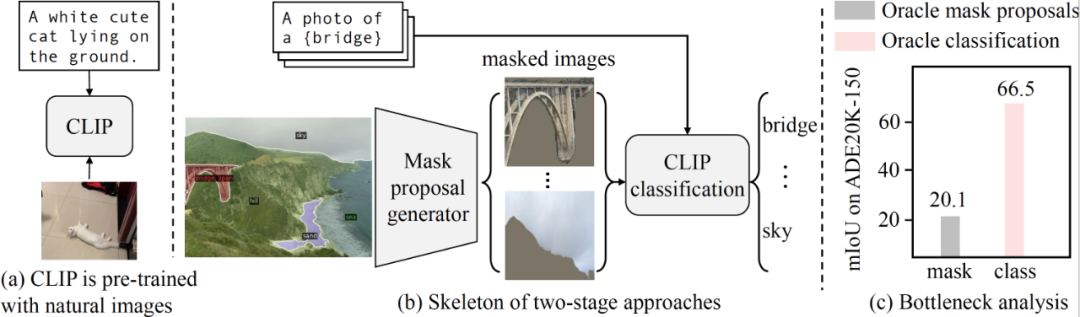
CLIP 是使用很少的数据增强在自然图像上进行预训练的。
两阶段的开放词汇语义分割方法首先生成类别不可知的掩膜建议,然后利用预训练的 CLIP 进行开放词汇分类。CLIP 模型的输入是裁剪的掩膜图像,与自然图像存在巨大的领域差距。
我们的分析表明,预训练的 CLIP 在掩膜图像上表现不佳。
方法
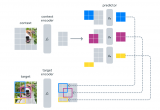
研究者的模型包括一个分割模型(例如 MaskFormer)和一个 CLIP 模型。
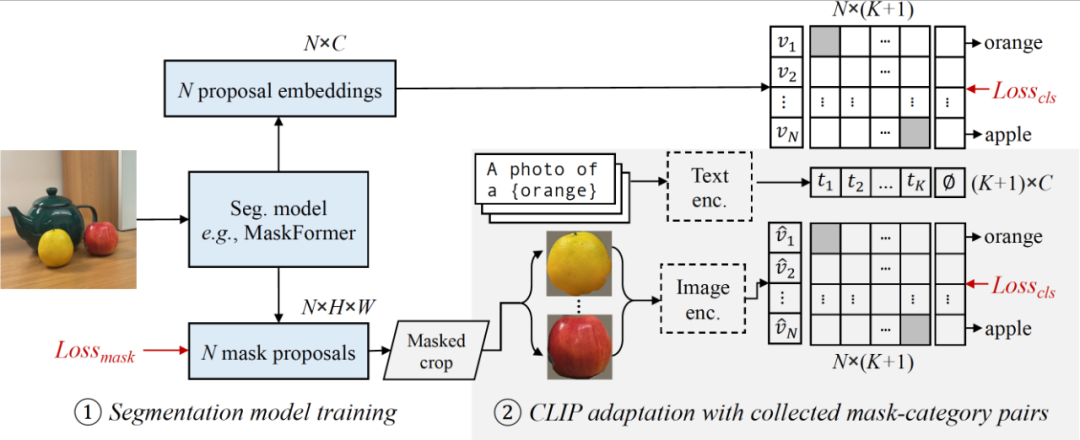
他们首先训练修改后的 MaskFormer 作为开放词汇分割的基线(第 3.1 节),然后从图像标题中收集多样的掩膜-类别对(第 3.2 节),并适应 CLIP 用于掩膜图像(第 3.3 节)。
结果
研究者首次展示开放词汇的通用模型可以在没有数据集特定调整的情况下与受监督的专业模型的性能相匹配。
更多分类示例如下所示。


审核编辑 :李倩
-
图像
+关注
关注
2文章
1084浏览量
40461 -
AI
+关注
关注
87文章
30887浏览量
269080 -
模型
+关注
关注
1文章
3243浏览量
48838
原文标题:分割一切后,Segment Anything又能分辨类别了:Meta/UTAustin提出全新开放类分割模型
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何在SAM时代下打造高效的高性能计算大模型训练平台
基于像素聚类进行图像分割的算法
通用AI大模型Segment Anything在医学影像分割的性能究竟如何?

Segment Anything量化加速有多强!

分割一切?Segment Anything量化加速实战

Meta开源I-JEPA,“类人”AI模型
基于 Transformer 的分割与检测方法

ICCV 2023 | 超越SAM!EntitySeg:更少的数据,更高的分割质量






 工商网监
工商网监
评论