 使用 NVIDIA AI Enterprise 3.0 优化生产级 AI 的性能和效率
使用 NVIDIA AI Enterprise 3.0 优化生产级 AI 的性能和效率

NVIDIA AI Enterprise 是一款端到端的安全云原生 AI 软件套件。最近发布的 NVIDIA AI Enterprise 3.0 加入了帮助优化生产级 AI 性能与效率的新功能。本文将详细介绍以下新功能及其工作原理。
· Magnum IO GPUDirect Storage
· VMware vSphere 8.0的 GPU 虚拟化功能
· Red Hat Enterprise Linux(RHEL)KVM 8 和 9
· 对 NVIDIA AI 的扩展支持
生产级 AI 功能
NVIDIA AI Enterprise 3.0 版本中的新 AI 工作流有助于缩短生产级 AI 的开发时间。这些工作流是常见 AI 用例的参考应用,包括联络中心智能虚拟助理、音频转录、数字指纹等。
未加密的预训练模型也首次包括在内,这确保了 AI 的可解释性并使开发者能够查看模型的权重和偏差,并了解模型的偏差。
NVIDIA AI Enterprise 现在支持 NGC 目录中发布的所有 NVIDIA AI 软件。已经使用过 NGC 的开发者现在可以无缝过渡到 NVIDIA AI Enterprise 并使用支持 50 多个 AI 框架、预训练模型和 SDK 的 NVIDIA Enterprise Support。
基础设施性能功能
NVIDIA AI Enterprise 3.0 包含许多有助于优化基础设施性能的新功能,因此用户可以从他们的 AI 投资中获得最大收益并最大程度地节约成本和时间。下面将对这些功能进行详细说明。
Magnum IO GPUDirect Storage
企业现在可以在部署 NVIDIA AI Enterprise 3.0 的情况下,利用 Magnum IO GPUDirect Storage 的性能优势来加速和扩展他们的 AI 工作负载。GPUDirect Storage 1.4 打通了本地或远程存储与 GPU 内存之间的直接数据路径,为复杂的工作负载提供无与伦比的性能。
GPUDirect Storage 简化并提高了存储和 GPU 缓冲区之间的数据流的效率,适用于在 GPU 上消耗或产生数据而不需要 CPU 处理的应用。该功能通过远程直接内存访问(RDMA),在从存储到 GPU 内存的直接路径上快速移动数据,减少延迟并通过消除回弹缓冲区产生的多余复制来减轻 CPU 的负担。
GPUDirect Storage 带来了明显的性能提升。与 NumPy 相比,使用 NVIDIA DALI 进行深度学习推理时,性能提高了 7.2 倍。
美国国家航空航天局(NASA)的火星探测器演示项目使用 NVIDIA IndeX 和 GPUDirect Storage 以及 27000 多个 NVIDIA GPU 来模拟逆向推进,在使用 PCIe 交换机和 NVLinks 以及 GPUDirect Storage 时,带宽提高了 5 倍。
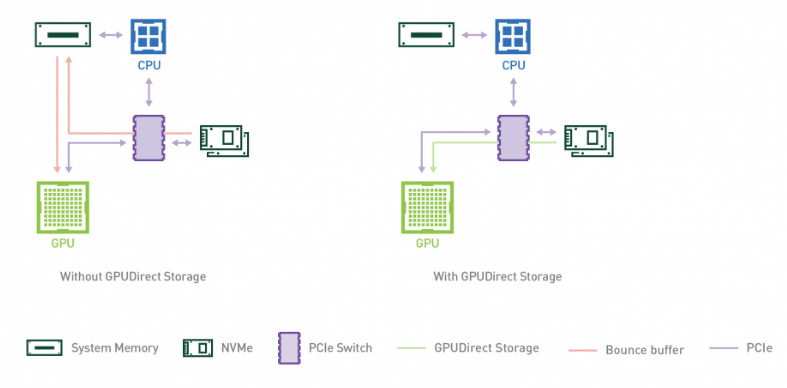
图 1. GPUDirect Storage 提供了一条从存储出发、完全跳过 CPU 的直接路径,消除了绑定在 CPU 上的回弹缓冲。
VMware vSphere 8.0 的 GPU 虚拟化功能
NVIDIA AI Enterprise 3.0 引入了对 VMware vSphere 8 的支持,包括多项可加速性能和提高运行效率的功能。VMware 环境现在可以在一个虚拟机上添加多达 8 个虚拟 GPU,vGPU 数量比之前的版本多了一倍。这提高了大型 ML 模型的性能,为复杂的 AI 和 ML 工作负载提供了更高的可扩展性。
随着设备组的引入,IT 管理员现在可以更好的控制虚拟机的放置。vSphere 附带的管理工具分布式资源调度(DRS)可确定虚拟机的最佳放置位置。
新的设备组功能提供了对 PCIe 设备的洞察,这些设备在硬件层面上(通过 NVLink 或 PCIe 开关)相互配对,IT 管理员可以从中选择一个子集,提交给虚拟机作出 DRS 调度决策。
通过设备组,IT 管理员可以确保设备子集被一起分配给虚拟机。例如,如果用户想要通过扩展 GPU 来加速大型模型,IT 管理员可以创建一个包含 GPU 的设备组并通过 NVLink 连接这些设备,比如图 2 中的设备组 1。
如果用户想要向外扩展到多台服务器以进行分布式训练,可以使用共享同一 PCIe 交换机的 GPU 和 NIC 组成设备组,比如图 2 中的设备组 2。
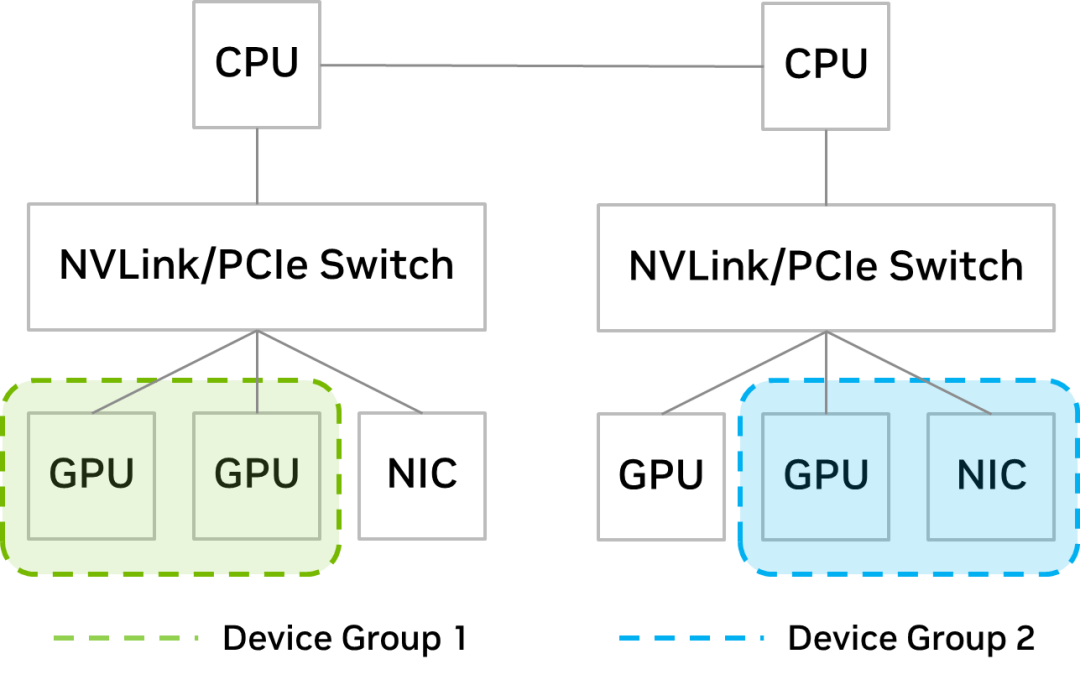
图 2. 有两个 GPU 的设备组(左)和服务器上有一个 GPU 与网卡的设备组(右)
Red Hat Enterprise Linux KVM
NVIDIA AI Enterprise 3.0 将虚拟化支持扩展至 Red Hat Enterprise Linux 8.4、8.6、8.7、9.0 和 9.1,使企业能够将 KVM 功能扩展到他们的 AI 工作负载。通过 RHEL KVM,管理员可以在一个虚拟机上添加多达 16 个虚拟 GPU,将计算密集型工作负载的处理速度提高数倍。
Fractional multi-vGPU 支持
管理员现在可以通过 NVIDIA AI Enterprise 3.0,为一台虚拟机配置多个 Fractional vGPU,从而更加灵活地根据工作负载优化虚拟机的配置。在该版本发布之前,每台虚拟机只能通过一个或多个整数份 GPU 加速。
管理员现在能够更加灵活地根据工作负载的计算需求,为一个虚拟机分配多个部分 vGPU 配置文件。例如,当运行具有不同计算需求的多个推理工作负载时,管理员可以根据工作负载的内存需求,为一个虚拟机分配不同数量帧缓冲器的 NVIDIA A100 Tensor Core GPU 的部分配置文件。
需要注意的是,所有部分配置文件必须是相同的板卡类型和系列。可以将一个或多个物理 GPU 分成这些份额的 vGPU 配置文件。该功能在 VMware vSphere 8 和 RHEL KVM 8 和 9 上均可以使用。
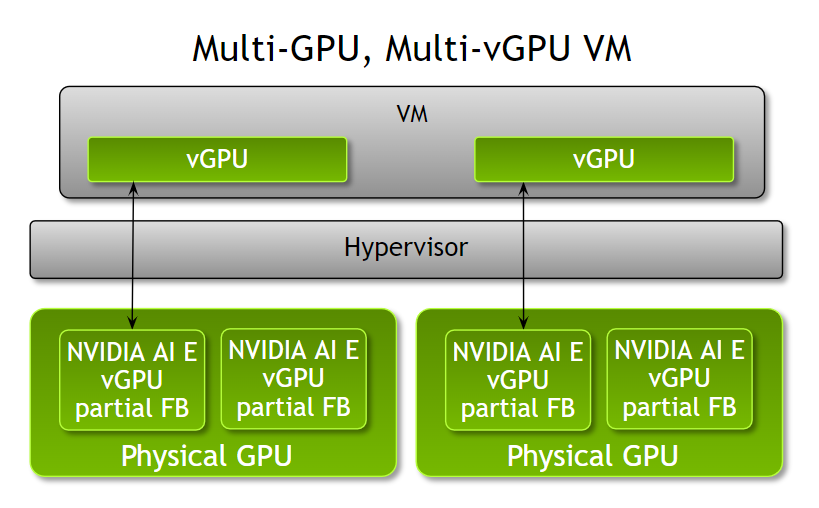
图 3. 将一个配置文件分成多个 vGPU 分配给一个虚拟机
对 NVIDIA AI 的扩展支持
NVIDIA AI Enterprise 为 NGC 目录中发布的所有 NVIDIA AI 软件提供支持,该目录目前包含 50 多个框架和模型。所有受支持的模型都标有“NVIDIA AI Enterprise Supported”以帮助用户轻松识别支持的软件。
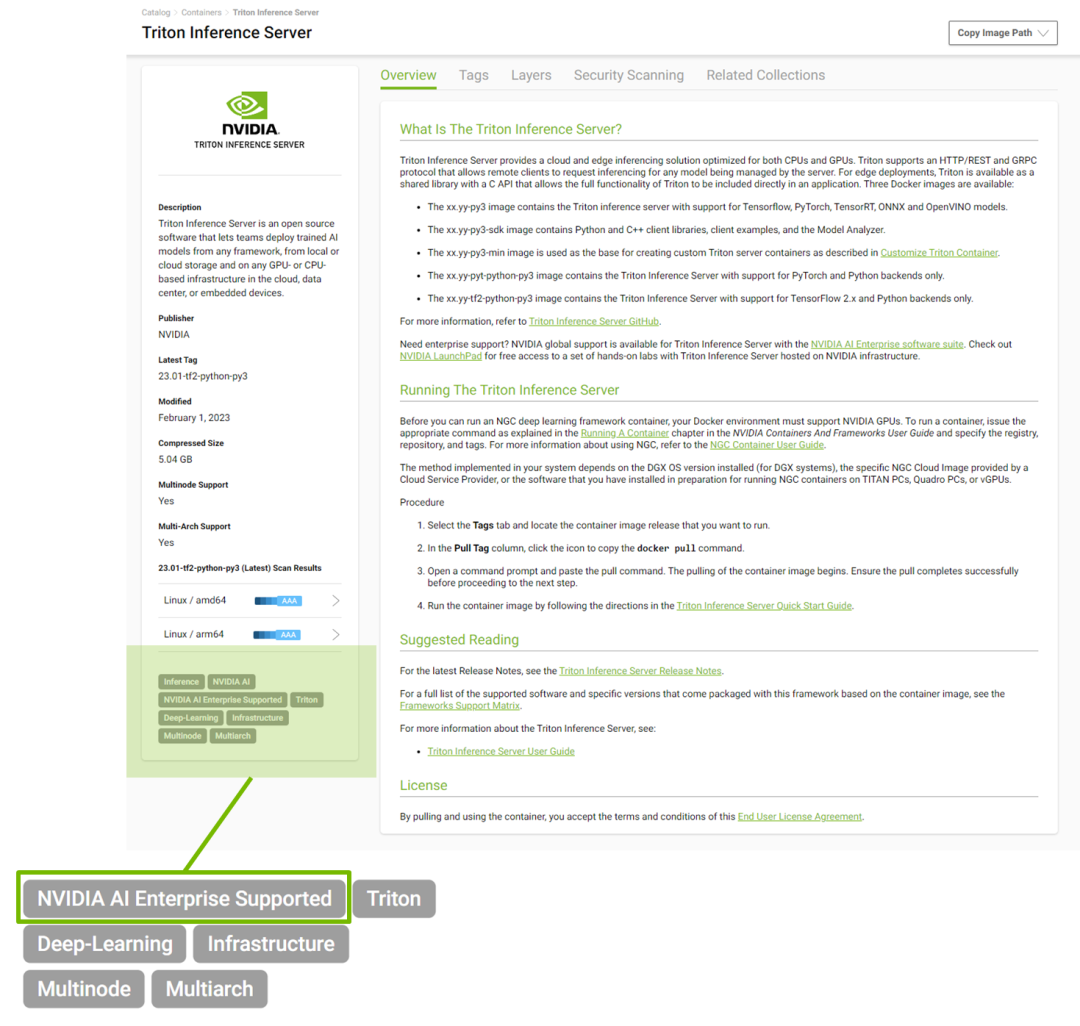
图 4. 所有 NVIDIA AI Enterprise 支持的模型在 NGC 目录中都有标注
总结
通过最新 3.0 版本的 NVIDIA AI Enterprise,企业可以使用最新的性能和效率优化功能缩短生产级 AI 的开发时间。NVIDIA LaunchPad 使用户可以在私有加速计算环境中即时、短期访问 NVIDIA AI Enterprise 软件套件,包括各种动手实操实验室。
即刻点击“阅读原文”或扫描下方海报二维码,在 NVIDIA On-Demand 上观看 GTC 精选回放,包括主题演讲相关精选、中国本地精选内容、生成式 AI 专题以及全球各行业及领域最新成果!
原文标题:使用 NVIDIA AI Enterprise 3.0 优化生产级 AI 的性能和效率
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
23文章
4124浏览量
99742
原文标题:使用 NVIDIA AI Enterprise 3.0 优化生产级 AI 的性能和效率
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
黑马-Java+AI新版V16零基础就业班百度云网盘下载+Java+AI全栈开发工程师
[完结15章]Java转 AI高薪领域必备-从0到1打通生产级AI Agent开发
Java转 AI高薪领域必备 从0到1打通生产级AI Agent开发 教程资料
NVIDIA与Google Cloud携手推进代理式与物理AI发展
Lenovo生产级AI解决方案:重构制造业的“交付周期革命”
嵌入式AI开发必看:杜绝幻觉,才是工业级IDE的核心底气
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
Magna AI加入NVIDIA Inception计划,推动生产级人工智能规模化发展
瑞芯微SOC智能视觉AI处理器
BPI-AIM7 RK3588 AI与 Nvidia Jetson Nano 生态系统兼容的低功耗 AI 模块
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的科学应用
汽车制造:AI 助力工艺优化,为整车生产提速

NVIDIA DOCA 3.0版本的亮点解析



评论