 什么是 NVLink?
什么是 NVLink?
NVLink 是加速系统中 GPU 和 CPU 处理器的高速互连技术,推动数据和计算加速得出可执行结果。
加速计算是一项曾经只有政府研究实验室中才有的高性能计算能力。如今,它已成为主流技术。
银行、汽车制造商、工厂、医院、零售商等机构需要处理和理解的数据日益增加,他们现在正在采用 AI 超级计算机来处理这些堆积如山的数据。
这些强大、高效的系统如同一条条“超级计算高速公路”。它们在多条并行路径上同时传输数据和计算,可以瞬间得出可执行结果。
GPU 和 CPU 处理器是“公路”沿途的资源,而快速互连通道是通往它们的“匝道”。NVLink 是加速计算互连通道的黄金标准。
那么,什么是 NVLink?
NVLink 是 GPU 和 CPU 之间的高速连接通道。它由一个强大的软件协议组成,通常通过印在计算机板上的多对导线实现,可以让处理器以闪电般的速度收发共享内存池中的数据。
如今,第四代 NVLink 连接主机和加速处理器的速度高达每秒 900GB/s。
这是传统 x86 服务器的互连通道——PCIe 5.0 带宽的 7 倍多。由于每传输 1 字节数据仅消耗 1.3 皮焦,因此 NVLink 的能效是 PCIe 5.0 的 5 倍。
NVLink 的历史
NVLink 最初作为 NVIDIA P100 GPU 的互连通道推出,之后便与每一代新的 NVIDIA GPU 架构同步发展。

2018 年,NVLink 首次亮相便被用于连接两台超级计算机——Summit 和 Sierra 的 GPU 和 CPU,成为了高性能计算领域的焦点。
这两套安装在美国橡树岭国家实验室和美国劳伦斯利弗莫尔国家实验室的系统正在推动药物研发、自然灾害预测等科学领域的发展。
带宽翻倍,继续发展
2020 年,第三代 NVLink 将每个 GPU 的最大带宽翻倍提高至 600GB/s,每个 NVIDIA A100 Tensor Core GPU 中都有十几条互连通道。
A100 为全球各地企业数据中心、云计算服务和 HPC 实验室的 AI 超级计算机提供动力。
如今,一个 NVIDIA H100 Tensor Core GPU 中包含 18 条第四代 NVLink 互连通道。这项技术已承担了一项新的战略任务——帮助打造全球领先的 CPU 和加速器。
芯片到芯片互联
NVIDIA NVLink-C2C 是一种板级互连技术,它能够在单个封装中将两个处理器连接成一块超级芯片。比如它通过连接两块 CPU 芯片,使 NVIDIA Grace CPU 超级芯片具有 144 个 Arm Neoverse V2 核心,为云、企业和 HPC 用户带来了高能效性能。
NVIDIA NVLink-C2C 还将 Grace CPU 和 Hopper GPU 连接成 Grace Hopper 超级芯片,将用于处理最棘手的 HPC 和 AI 工作的加速计算能力集合到一块芯片中。
计划在瑞士国家计算中心投入使用的 AI 超级计算机 Alps 将是首批使用 Grace Hopper 的计算机之一。这套高性能系统将在今年晚些时候上线,用于处理从天体物理学到量子化学等领域的大型科学问题。
Grace 和 Grace Hopper 还非常适合用于提升高要求云计算工作负载的能效。
例如 Grace Hopper 是最适合用于推荐系统的处理器。这些互联网的经济引擎需要快速、高效地访问大量数据,才能每天向数十亿用户提供数万亿条结果。
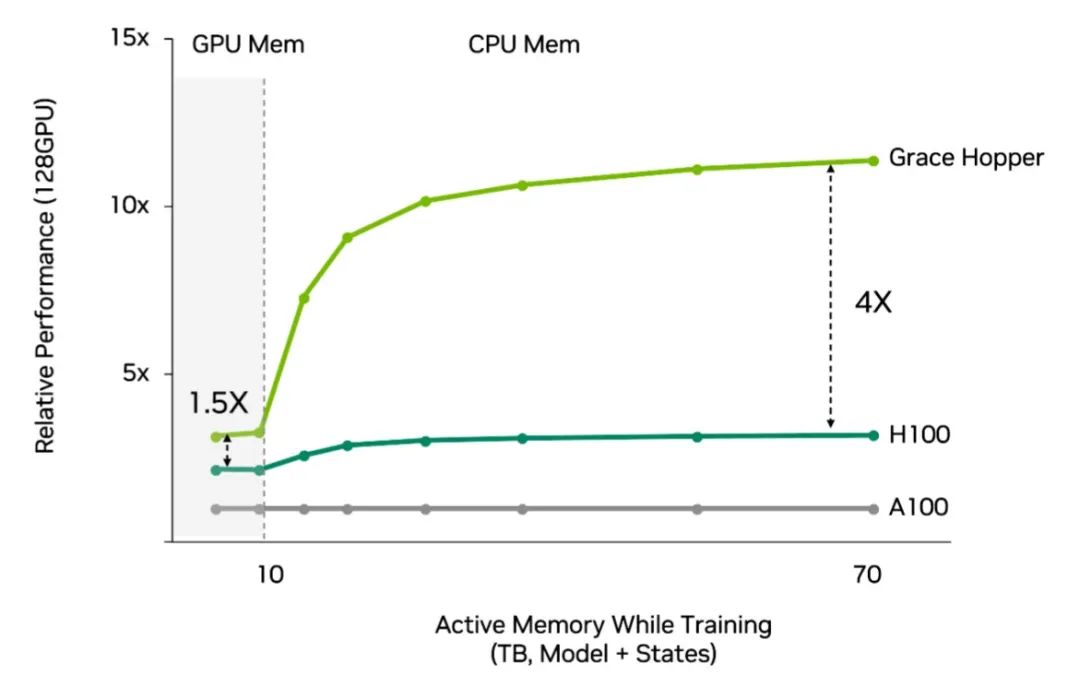
与使用传统 CPU 的 Hopper 相比,采用 Grace Hopper 的推荐系统的性能提高了 4 倍,并且效率更高。
另外,NVLink 还被用于为汽车制造商提供的强大系统级芯片,包括 NVIDIA Hopper、Grace 和 Ada Lovelace 处理器等。车载计算平台 NVIDIA DRIVE Thor 将数字仪表板、车载信息娱乐、自动驾驶、泊车等诸多智能功能统一整合到单个架构中。
“乐高式”计算链路
NVLink 的作用就像是乐高积木的凸粒和凹槽。它是构建超级系统以处理超大型 HPC 和 AI 工作的基础。
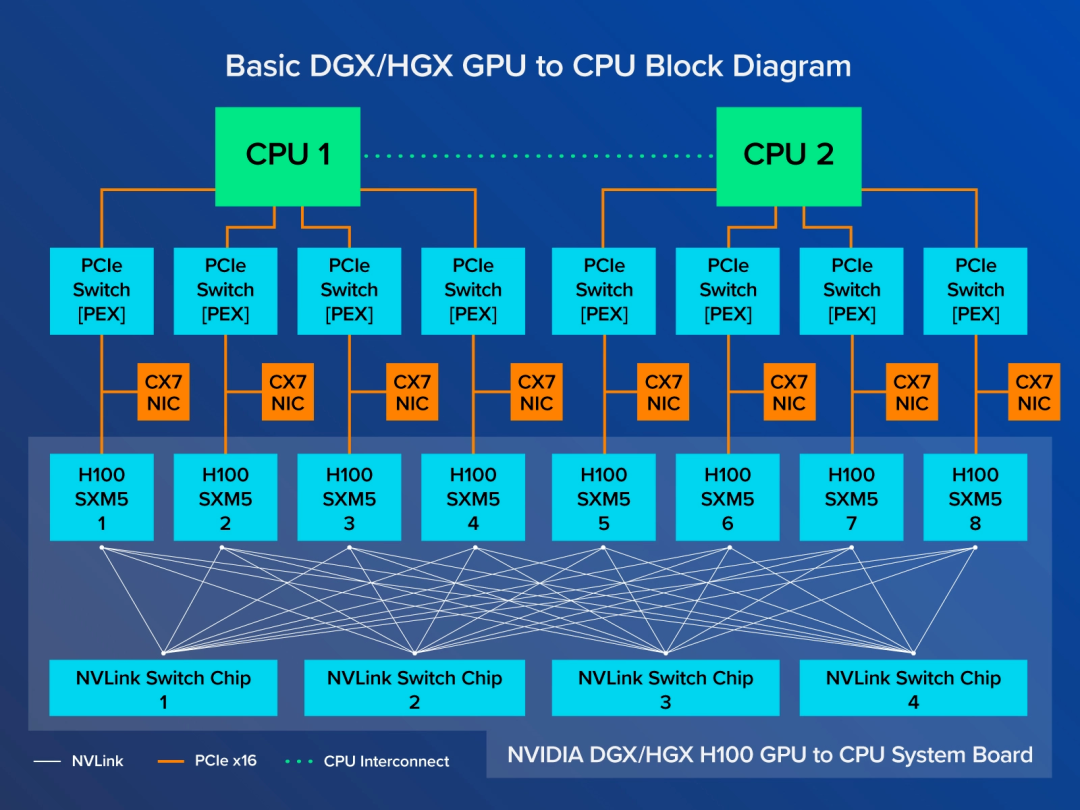
例如,NVIDIA DGX 系统中的八个 GPU 上的 NVLink 通过 NVSwitch 芯片共享快速、直接的连接。它们共同组成了一个 NVLink 网络,使服务器中的每一个 GPU 都是一套系统的一部分。
为了获得更强大的性能,DGX 系统本身可以堆叠成由 32 台服务器组成的模块化单元,形成一个强大、高效的计算集群。
用户可以利用 DGX 内部的 NVLink 网络与两者之间的 NVIDIA Quantum-2 InfiniBand 交换以太网,将 32 个 DGX 系统模块连接成一台 AI 超级计算机。例如,一台 NVIDIA DGX H100 SuperPOD 包含 256 个 H100 GPU,可提供最高 1 EXAFLOP 的峰值 AI 性能。
如要进一步提高性能,用户还可以使用云中的 AI 超级计算机,例如微软Azure使用数万个 A100 和 H100 GPU 打造的超级计算机。OpenAI 等团队正在使用这项服务训练一些全球最大的生成式 AI 模型。
这再次印证了加速计算的力量。
原文标题:什么是 NVLink?
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3772浏览量
91019
原文标题:什么是 NVLink?
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
挑战英伟达NVLink!英特尔/谷歌等成立联盟,推出UALink 1.0

分布式通信的原理和实现高效分布式通信背后的技术NVLink的演进
鸿海再获AI领域大单,独家供货英伟达GB200 NVLink交换器
科技巨头组建“复仇者联盟”,挑战英伟达的NVLink技术
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
一文详解基于以太网的GPU Scale-UP网络

全面解读英伟达NVLink技术

什么是NVIDIA?InfiniBand网络VSNVLink网络

NVLink的演进:从内部互联到超级网络

NVLink技术之GPU与GPU的通信

NVIDIA宣布推出NVIDIA Blackwell平台以赋能计算新时代
英伟达AI服务器NVLink版与PCIe版有何区别?又如何选择呢?
深度解读Nvidia AI芯片路线图

英伟达推出为中国大陆定制的H20 AI GPU芯片
英伟达和华为/海思主流GPU型号性能参考






 工商网监
工商网监
评论