 基于鲲鹏处理器的高性能计算实践
基于鲲鹏处理器的高性能计算实践
我国在高性能计算领域取得了显著进步,天河二号和神威太湖之光先后登顶Top500国际超算排行榜,2016、2017年连续获得戈登贝尔HPC应用大奖。在“十四五”规划中,我国在高性能计算领域将继续贯彻“国产替代”战略,新一代E级超级计算机都将采用国产处理器。
然而,目前国内高校还没有采用国产处理器的校级计算平台。这主要有以下三个原因:①基于国产处理器的计算平台在使用习惯上与目前X86 CPU集群差异很大,用户不习惯;②目前主流计算软件都是基于X86处理器开发,在国产处理器上需要重新编译与适配;③许多计算软件的应用尚未针对国产处理器进行性能调优,运行速度无法保证。
为应对上述用户操作难、应用部署难、运行速度慢这三个挑战,我们开展了以下工作:
1)通过挂载统一文件系统和作业调度系统,将不同的计算设备融合在统一的并行文件系统之上,为用户提供一致的体验;
2)利用容器快速部署面向ARM集群的高性能计算应用,以模块和镜像形式向用户提供预编译软件;
3)对于预编译的应用软件,进行了正确性校验及性能调优。
本文将介绍上海交通大学采用华为鲲鹏920处理器建设的校级计算平台,该平台是国内高校建设的首个基于国产ARM处理器的计算集群(以下简称ARM集群)。这台ARM集群与原有的X86 CPU集群、GPU集群共享一套并行文件系统,采用Infiniband网络高速互联,实践了统一数据基座的理念。
我们这个工作有两个创新点:
1)针对使用异构处理器、异构互联网络的多个计算集群,提出了一套新的网络拓扑方案,使得这些计算集群可以共享同一并行文件系统;
2)率先在华为ARM集群上完成多个常用高性能计算应用的正确性校验与性能调优,有力推动了国产高性能计算平台的软件生态建设。
上海交通大学校级高性能计算平台于2013年建设了第一期,当时采用的是Intel Xeon处理器、XeonPhi协处理器和NVIDIA GPU加速器的混合计算架构,计算能力位列2013年11月Top500榜单第138位。2019年学校启动二期建设,分别建设了基于Intel Xeon处理器面向高性能计算的同构集群和基于NVIDIA GPU加速器面向人工智能计算的异构集群。2020年我校建设第3套计算集群,采用了华为鲲鹏920处理器。
1. 背景介绍
1.1 计算节点
ARM集群共配置100个计算节点,每个节点搭载双路128核鲲鹏920处理器,配有192 GB DDR4 2933内存。华为鲲鹏920采用7纳米芯片制程工艺,基于ARMv8微架构,具体参数规格参见表1。
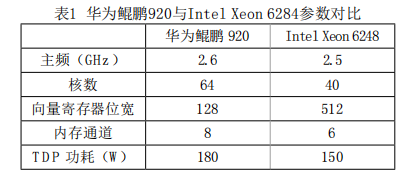
相比主流的Intel Xeon 6248处理器,华为鲲鹏920的核数和内存通道更多,因此提供了更高的并发度和内存访问带宽。但在向量化位宽上,鲲鹏920为Intel主流处理器的1/4。基于以上特征,鲲鹏920更加适合访存密集型应用的计算
1.2 高速互联网络
上海交大校级计算平台中的Intel CPU集群采用的是Intel 100 Gbps Omini-Path高速互联网络,GPU集群和ARM集群则采用Mellanox 100 Gbps Infiniband EDR高速互联网络。作为目前两大主流高速互联网络,其通信协议提供了一种基于交换的架构,由处理器节点之间、处理器节点和存储节点之间的点对点双向串行链路构成。
1.3 文件系统
校级计算平台采用Lustre并行文件系统,它是一种基于对象的并行文件系统,具有高可用、高性能、高可扩展性等特点,可以为大规模计算集群提供兼容POSIX的统一文件系统接口。其在Linux操作系统上运行,并采用客户端-服务端模式的网络架构。Lustre的服务端由一组服务器组成,用于提供元数据服务和对象存储服务;客户端则是Lustre文件系统的访问接口,可以挂载Lustre文件系统。Lustre各节点服务器之间使用Lnet高速网络协议互联。
1.4 作业调度系统
校级计算平台部署了CentOS7.6操作系统,在这套Linux系统上,我们挂载了SLURM作业调度系统。SLURM是一个开源、容错、高度可扩展的集群管理和作业调度系统,作为集群工作负载管理器,它有三个关键功能:①它在一段时间内为用户分配对资源(计算节点)的独占和/或非独占访问,以便他们可以执行工作;②它提供了一个框架,用于在分配的节点集上启动,执行和监视工作(通常是并行作业);③它通过管理待处理工作的队列来仲裁资源争用。
2. 系统设计 2.1 网络拓扑设计
ARM集群网络接入的整体思路类似于CPU+GPU异构集群,所有ARM节点接入Infiniband交换机实现节点间的互联,后通过路由节点(LNet Router)桥接至OmniPath网络,做到Infiniband和OmniPath两种异构网络之间的互通。
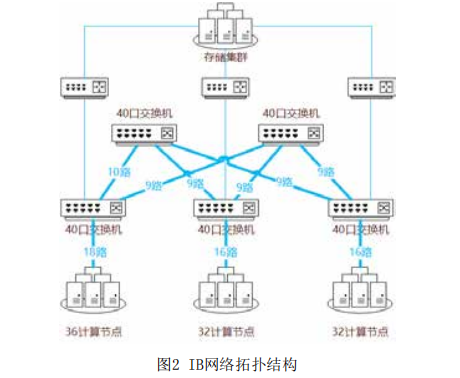
ARM集群的IB网络包含5台40口小型交换机和3台路由节点。其中3台交换机作为接入层交换机,分出一半端口直接与节点相连;剩余2台作为核心层交换机,与接入层交换机进行网状连接。3台接入层交换机又分别通过对应的路由节点接入存储集群。节点与交换机之间、交换机与交换机之间每条物理线路支持200Gbps带宽,整个接入层与计算节点之间合计有10000Gbps通信带宽;而接入层与核心层之间合计有11000Gbps带宽。由于IB交换机自带路由选择功能,可以确保接入层与交换层的数据流量均匀分摊到每一条等价链路上,因此在这个胖树拓扑结构下,任意两个节点之间都可以始终确保享有100Gbps的可用通信带宽。
2.2 共享文件系统挂载
ARM集群挂载Lustre文件系统分为两个步骤:
步骤一:编译安装Lustre客户端。安装的Lustre客户端版本需与服务端适配,因此需要选择合适的操作系统版本,同时编译Lustre客户端过程中指定内核与IB驱动。实践中,我们采用了ARM架构定制化的CentOS 7.6系统,编译安装了2.12.4版本Lustre客户端。
步骤二:配置lnet路由。对于3组ARM集群节点来说,须赋予不同的LNET标签(类似不同子网),且与存储集群、X86超算集群等其它集群不同。之后,分别在存储服务端、ARM节点和路由节点配置对应的Lnet路由,连通OPA和IB网络。
经过以上两个步骤,即可在ARM集群成功挂载Lustre文件系统,从而形成统一的数据基座。
3. 性能调优与验证
为解决ARM集群运行速度慢的问题,我们选择了LAMMPS和GATK作为本次应用调优与验证的算例。这两款应用2020年在我校X86 CPU集群上占到全年使用机时的35%。
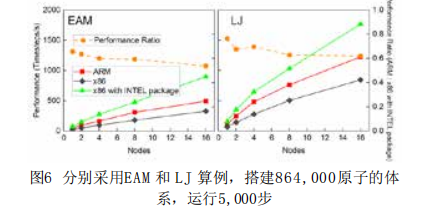
采用LAMMPS的两个最基本算例EAM和LJ,测试ARM、X86以及X86上加入User-Intel加速包这三种模式,对比1, 2, 4, 8 和16个节点的运行速度(Timesteps/s)。两个算例EAM和LJ均为864,000原子体系,在NVE系统下运行5,000步。ARM单节点计算速度是Intel主流处理器(不含User-Intel加速包)的2倍,扩展到16个节点仍保持1.5倍的优势。当X86编译使用User-Intel加速包后,ARM集群上LAMMPS的计算性能为Intel主流平台的60%左右。
基于上述由Broad Institute提供的分析流程及相应的测试数据,测试X86和ARM上GATK 4.2的性能。由于在ARM集群上GATK 的HaplotypeCaller模块缺少Intel为X86开发的GKL加速包(Intel GKL Utils),因此速度下降明显。而MarkDuplicates及BQSR相关工具未经过底层优化,其在ARM集群上的性能约为x86集群的70%与50%。
为应对ARM集群建设中遇到的用户操作难、应用部署难以及运行速度慢这三个挑战,我们提出了一套新的网络拓扑方案,使得ARM集群可以和现有X86集群可以共享同一并行文件系统,用户可以实现无差别的数据访问。另外,还利用Singularity为ARM集群快速部署了30多款常用的高性能计算应用软件,并对其中使用率最高的LAMMPS和GATK应用进行了性能调优和评估,性能可以达到主流X86集群的60%-70%。ARM集群在2021年暑期面向校内进行试运行,期间整机月平均利用率超过70%。
审核编辑 :李倩
-
处理器
+关注
关注
68文章
19548浏览量
231872 -
ARM
+关注
关注
134文章
9217浏览量
371165 -
gpu
+关注
关注
28文章
4832浏览量
129802
原文标题:基于鲲鹏处理器的高性能计算实践
文章出处:【微信号:架构师技术联盟,微信公众号:架构师技术联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
香山是什么?“香山” 高性能开源 RISC-V 处理器项目介绍
英伟达发布高性能计算处理器丹佛计划
华为表示鲲鹏920是目前业界最高性能ARM-based处理器
华为推出基于ARM架构的服务器处理器鲲鹏920
基于NXP QorIQ 64位T1042处理器的高性能计算机
基于T4240多核处理器的高性能计算机产品特点


高性能处理器RK3588数据手册
鲲鹏Validated认证帮助密码模块构建全面的高性能密码计算服务
面向后E级计算的高性能处理器技术参考和借鉴
Fujitsu、NVIDIA、AMD和Intel高性能处理器架构分析





 工商网监
工商网监
评论