 MAE再发力,跨模态交互式自编码器PiMAE席卷3D目标检测领域
MAE再发力,跨模态交互式自编码器PiMAE席卷3D目标检测领域
本文提出了一种基于MAE的跨模态交互式自编码器PiMAE,PiMAE同时具有强大的3D点云和RGB图像特征提取能力。作者通过三个方面的独特设计来促进多模态学习过程中的交互效果。并对提出的PiMAE进行了广泛的实验,该框架在多个下游任务上都展示出了非常出色的性能提升效果,这也侧面表明MAE模式在基础视觉感知任务上仍然不过时,具有进一步研究的价值。

论文链接: https://arxiv.org/abs/2303.08129 代码链接: https://github.com/BLVLab/PiMAE
从2021年kaiming大佬首次提出MAE(Masked Autoencoders)以来,计算机视觉社区已经出现了很多基于MAE的工作,例如将MAE建模拓展到视频序列中,或者直接对MAE原始结构进行改进,将MAE嵌入到层次的Transformer结构中等等。截止到现在,MAE原文在谷歌学术的引用量已经达到1613。

MAE以其简单的实现方式、强大的视觉表示能力,可以在很多基础视觉任务中展现出良好的性能。但是目前的工作大多是在单一视觉模态中进行,那MAE在多模态数据融合方面表现如何呢?本文为大家介绍一项刚刚被视觉顶会CVPR2023接收的工作,在这项工作中,作者重点探索了点云数据和RGB图像数据,并且提出了一种基于MAE的自监督扩模态协同感知框架PiMAE。具体来说,PiMAE可以从三个方面来提升模型对3D点云和2D图像数据的交互性能:
1. PiMAE设计了一个多模态映射模块来对两个不同模态的masked和可见的tokens进行对齐,这一设计强调了mask策略在两个不同模态中的重要性。
2. 随后,作者为PiMAE设计了两个MAE支路和一个共享的解码器来实现masked tokens之间的跨模态交互。
3. 最后PiMAE通过一个新型的跨模态重建模块来进一步提升两个模态的表征学习效果。
作者在两个大规模多模态RGB-D场景理解基准(SUN RGB-D和ScannetV2)上对PiMAE进行了大量评估,PiMAE在3D目标检测、2D目标检测以及小样本图像分类任务上都展现出了优越的性能。
一、介绍
深度学习技术目前已经成为很多自动化装备的基础感知手段,例如工业机器人和自动驾驶。在这些实际场景中,机器可以通过摄像头和众多传感器获得大量的3D或2D点云数据以及RGB图像数据。由于成对的2D像素和3D点云可以更全面的呈现同一场景的不同视角,将这些多模态信息高效的结合起来可以提高模型决策的准确性。在本文中,作者旨在探索这样一个问题:如何设计一个高效的多模态(3D点云和RGB模态)无监督交互学习框架,来实现更好的表征学习?为此,作者选用kaiming提出的MAE作为基础架构,MAE可以通过一种简单的自监督任务实现一个强大的ViT预训练框架。但是MAE在多种模态交互的情况下表现如何,仍然是未知的。
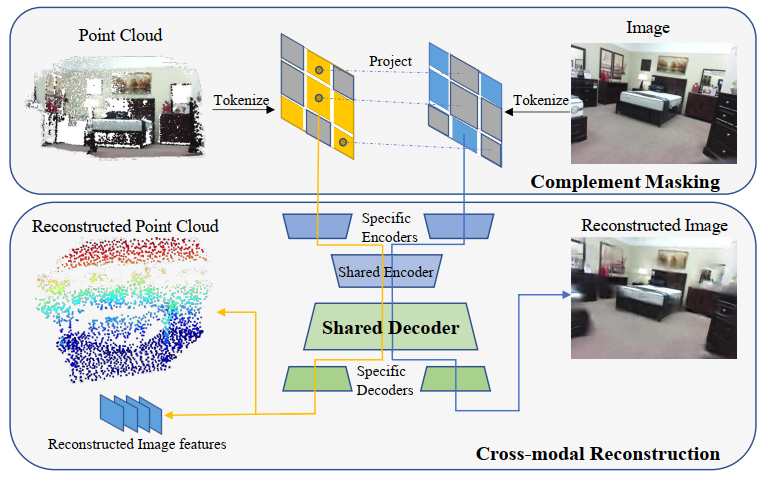
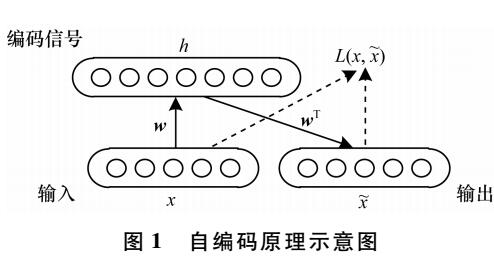
为了探索多模态3D点云和RGB图像数据交互融合性能,本文提出了PiMAE,这是一种简单而有效的多模态MAE框架,PiMAE可以通过交互机制来学习更鲁棒的3D和2D特征。PiMAE的整体框架如上图所示,具体来说,PiMAE将成对的3D点云和图像数据作为输入,并对两种输入做一种互补的mask操作。然后对其进行编码得到tokens,将3D点云token投影到RGB图像块中,明确对齐两种模态之间的Mask关系。作者认为通过这种mask策略可以帮助点云token从图像嵌入中获得互补信息,反之亦然。随后作者设计了一种对称的自动编码器结构来进行模态特征融合,自编码器由模态特定编码器(Specific Encoders)的独立分支和共享编解码器构成,PiMAE通过多模态重构任务(即点云重构和图像重构)来完成两种模态的交互和表征学习。
二、方法介绍
给定3D点云和RGB多模态数据后,PiMAE通过一种联合嵌入的方式来学习跨模态特征。在具体操作中,作者首先对点云数据进行采样并执行聚类算法将点云数据嵌入到token中,然后对点云token进行随机mask。mask后的token随后被转换到2D平面中,同时RGB图像块以互补mask的形式也嵌入到RGB token中。随后两个模态的token数据通过PiMAE的联合编解码器进行特征建模和融合。
PiMAE中的编码器-解码器架构同时整合了模态独立分支和模态共享分支,其中前者用来保持模型对特定模态的学习,后者鼓励模型通过跨模态的特征交互来实现模态之间的高效对齐。
2.1 token投影和对齐
在对点云和RGB图像进行处理时,作者遵循MAE和Point-M2AE[1]中的做法,对于RGB图像,作者将图像先分成不重叠的图像块,并且为每个块添加位置编码嵌入和模态嵌入,随后将他们送入到投影层。对于点云数据,先通过最远点采样(Farthest Point Sampling,FPS)和KNN算法提取聚类中心token,然后同样为每个中心token添加编码嵌入和模态嵌入,并送入到线性投影层。
2.1.1 投影
为了实现多模态token之间的对齐,作者通过将点云token投影到相机的2D图像平面上来建立 3D点云和RGB图像像素之间的嵌入联系。对于3D点云 ,可以使用下面定义的投影函数 Proj 计算出相应的2D坐标:
,可以使用下面定义的投影函数 Proj 计算出相应的2D坐标:
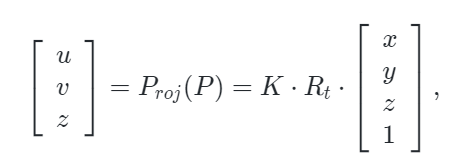
其中 K∈3×4,Rt∈4×4是相机的内在和外置参数矩阵。(x,y,z),(u,v)是点 P 的原始3D坐标和投影得到的2D坐标。
2.1.2 Mask对齐方式
由于点云token是由一系列聚类中心构成,作者随机从中选择一部分中心点作为采样区域。对于可见点云标记Tp,将它们的中心点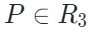 投影到相应的2D相机平面并获得其2D坐标
投影到相应的2D相机平面并获得其2D坐标 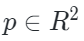 它可以自然地落入形状为 H×W(即图像形状)的区域内,可以通过以下方式来获得其相对应图像块的索引
它可以自然地落入形状为 H×W(即图像形状)的区域内,可以通过以下方式来获得其相对应图像块的索引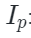
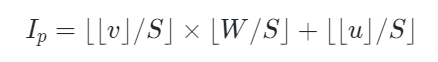
其中 u 和 v表示二维坐标 p 的 x 轴值和 y 轴值,S 是图像块大小。
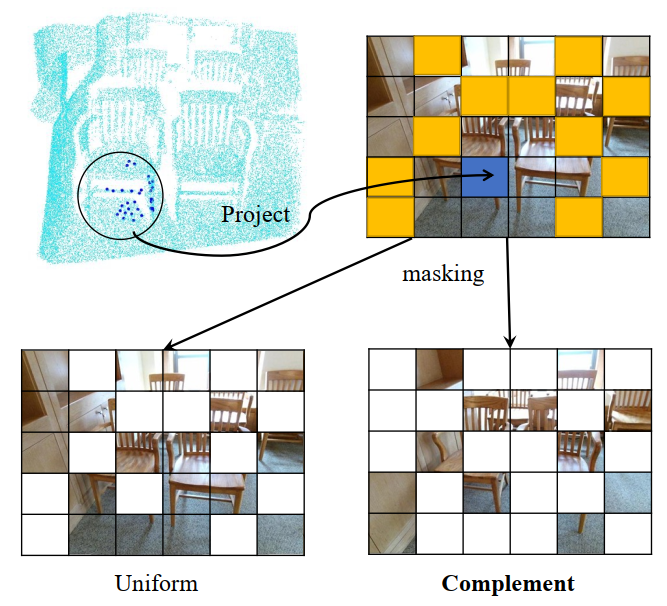
在对每个可见点云token进行投影和索引后,就可以获得它们对应的图像块,如上图所示。随后作者使用了一种显示的mask策略来实现token对齐,具体来说,一个随机采样的点云区域(上图黑色圆圈处)被投影到图像块(蓝色方块)上,其他点云区域以类似的方式进行采样和投影(黄色方块),来构成正向Mask模式(Uniform)。相反,上图右下区域是相应的互补Mask模式(Complement)。
2.2 编码器和解码器
2.2.1 编码器
PiMAE的编码器遵循AIST++[2]的设计,由两个模块构成:模态特定编码器和跨模态编码器。前者用于更好地提取特定于当前模态的特征,后者用于进行跨模态特征之间的交互。在这一过程中,编码器侧重于保持不同模态特征的完整性,可以形式化表示为:
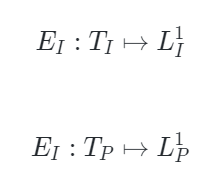
其中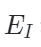 和
和 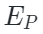 是特定于图像和特定于点云的编码器,
是特定于图像和特定于点云的编码器,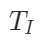 和
和 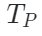 是可见图像和点云token,
是可见图像和点云token,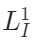 和
和 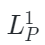 是图像和点云相应的嵌入空间。
是图像和点云相应的嵌入空间。
2.2.2 解码器
原始MAE框架中的解码器是建立在一个具有统一表征能力的编码基础之上,但是本文的设定是编码器同时捕获图像和点云数据的特征表示。由于两种模态之间的差异,需要使用专门的解码器将这些特征解码为各自的模态。形式上,作者将PiMAE的共享解码器的输入表示为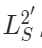 ,其中包括编码的可见特征和两种模态的mask tokens。随后共享解码器会对这些特征
,其中包括编码的可见特征和两种模态的mask tokens。随后共享解码器会对这些特征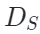 执行跨模态交互:
执行跨模态交互: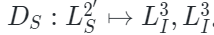 。然后,在单独模态的解码器阶段,解码器将特征重构回原始图像和点云空间
。然后,在单独模态的解码器阶段,解码器将特征重构回原始图像和点云空间 
。其中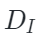 和
和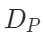 是图像特定和点云特定解码器,
是图像特定和点云特定解码器,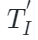 和
和 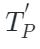
是可见图像和点云区域,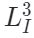 和
和 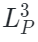 是图像和点云嵌入空间,重构过程的损失函数如下:
是图像和点云嵌入空间,重构过程的损失函数如下:
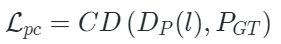
其中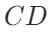 是
是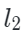 Chamfer Distance函数(倒角距离),
Chamfer Distance函数(倒角距离),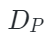 表示解码器重构函数,
表示解码器重构函数,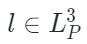 是点云嵌入表示,
是点云嵌入表示,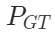 是点云ground-truth(即点云输入)。
是点云ground-truth(即点云输入)。
2.3 跨模态重构
本文使用三种不同的损失联合训练PiMAE:点云重建损失、图像重建损失和跨模式重建损失。在最后的重建阶段,作者利用先前对齐的关系来获得mask点云区域相应的二维坐标。然后,对重建的图像特征进行上采样,这样每个具有2D坐标的mask点云都可以与重建的图像特征相关联。最后,mask点云token通过一个跨模态预测头来恢复相应的可见图像特征。形式上,跨模式重建损失定义为:
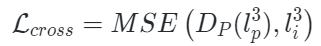
其中 表示均方误差损失函数,
表示均方误差损失函数,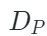 是解码器的跨模态重建函数,
是解码器的跨模态重建函数,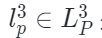 是点云表示,
是点云表示,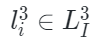 是图像表示。PiMAE通过联合以上损失来进行训练,通过这样的设计,PiMAE可以分别学习3D和2D特征,同时保持两种模态之间的强交互性。
是图像表示。PiMAE通过联合以上损失来进行训练,通过这样的设计,PiMAE可以分别学习3D和2D特征,同时保持两种模态之间的强交互性。
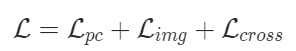
三、实验效果
本文的实验在两个大规模多模态RGB-D场景理解基准(SUN RGB-D和ScannetV2)上进行,作者先在SUN RGB-D训练集对PiMAE进行预训练,并在多个下游任务上对PiMAE进行评估,包括3D目标检测、3D单目目标检测、2D目标检测和小样本图像分类。
3.1 室内3D目标检测
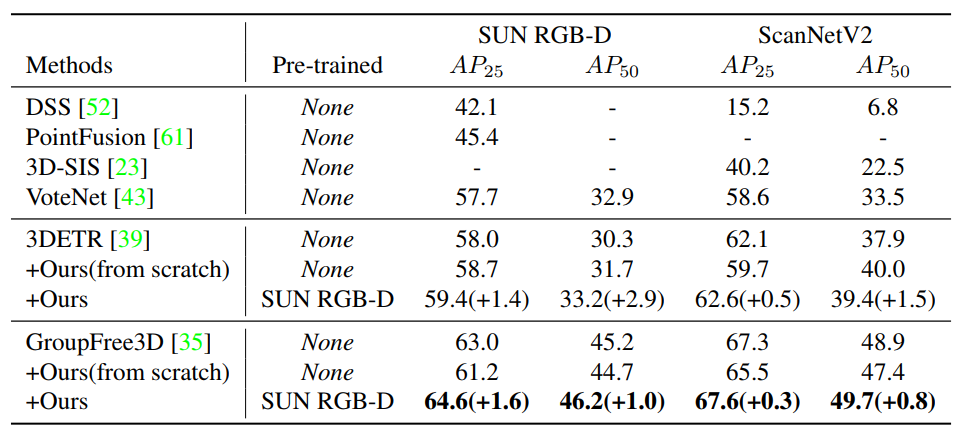
对于室内的3D目标检测任务,作者将PiMAE的3D特征编码器加入到不同的backbone网络中来提高特征提取的能力,从而实现3D目标检测的能力。作者以两个SOTA模型3DETR和GroupFree3D来作为baseline模型,如下表所示,本文的PiMAE为两个模型都带来了显着的性能提升,在所有数据集上都超过了之前的基线方法。
3.2 室外单目3D目标检测
除了室内环境,作者也展示了更具挑战性的室外场景效果。与室内预训练数据相比,室外场景的数据具有很大的数据分布差距。如下图所示,本文方法对MonoDETR方法实现了实质性的改进,这证明,PiMAE预训练对室内和室外场景都具有很强的泛化能力。

3.3 2D目标检测
对于2D目标检测任务,作者直接将PiMAE中的2D分支特征提取器部署在DETR上,并在ScanNetV2 2D检测数据集上进行评估。效果如下表所示,PiMAE预训练可以显著提高DETR的检测性能。

3.4 小样本图像分类
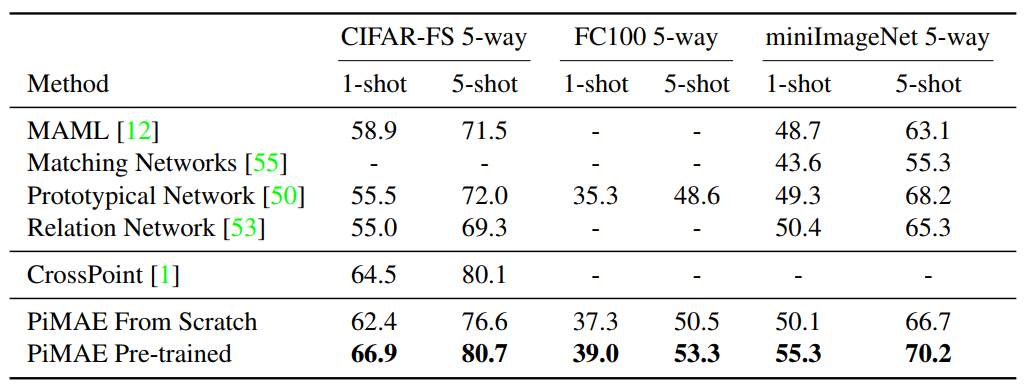
对于few-shot图像分类任务,作者选取了三个不同的基准来探索PiMAE图像编码器的特征提取能力。为了验证PiMAE的有效性,作者没有改动原有模型的分类器,仅在特征编码器中添加一个线性层,并基于[CLS] token作为输入来预测类别。下表展示了PiMAE在小样本图像分类任务上的结果。与从头开始训练的模型相比,经过PiMAE预训练的模型具有显著的性能提升。
此外,为了验证PiMAE跨模态交互设计的有效性,作者在下图中可视化了共享编码器中的注意力图。可以看到,PiMAE更专注于具有更高注意力值的更多前景目标,显示出较强的跨模态理解能力。

四、总结
本文提出了一种基于MAE的跨模态交互式自编码器PiMAE,PiMAE同时具有强大的3D点云和RGB图像特征提取能力。作者通过三个方面的独特设计来促进多模态学习过程中的交互效果。首先,通过一种显示的点云图像对齐mask策略可以实现更好的特征融合。接下来,设计了一个共享解码器来同时对两种模态中的token进行处理。最后,跨模态重建机制可以高效的对整体框架进行优化。作者对提出的PiMAE进行了广泛的实验,PiMAE在多个下游任务上都展示出了非常出色的性能提升效果,这也侧面表明MAE模式在基础视觉感知任务上仍然不过时,具有进一步研究的价值。
审核编辑 :李倩
-
解码器
+关注
关注
9文章
1143浏览量
40738 -
编码器
+关注
关注
45文章
3641浏览量
134499 -
目标检测
+关注
关注
0文章
209浏览量
15606
原文标题:CVPR 2023 | MAE再发力,跨模态交互式自编码器PiMAE席卷3D目标检测领域
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于变分自编码器的异常小区检测
基于深度自编码网络的慢速移动目标检测
是什么让变分自编码器成为如此成功的多媒体生成工具呢?

Torch 3D通过AR工具来开拓3D设计领域
英伟达再出新研究成果 可以渲染合成交互式3D环境的AI技术
自编码器介绍
自编码器基础理论与实现方法、应用综述
自编码器神经网络应用及实验综述
华南理工开源VISTA:双跨视角空间注意力机制实现3D目标检测SOTA
自编码器 AE(AutoEncoder)程序

工业仪器3D交互式产品展示的亮点
如何搞定自动驾驶3D目标检测!






 工商网监
工商网监
评论