 浅析4个计算机视觉领域常用迁移学习模型
浅析4个计算机视觉领域常用迁移学习模型
导读
使用SOTA的预训练模型来通过迁移学习解决现实的计算机视觉问题。
如果你试过构建高精度的机器学习模型,但还没有试过迁移学习,这篇文章将改变你的生活。至少,对我来说是的。
我们大多数人已经尝试过,通过几个机器学习教程来掌握神经网络的基础知识。这些教程非常有助于了解人工神经网络的基本知识,如循环神经网络,卷积神经网络,GANs和自编码器。但是这些教程的主要功能是为你在现实场景中实现做准备。
现在,如果你计划建立一个利用深度学习的人工智能系统,你要么(i)有一个非常大的预算用于培训优秀的人工智能研究人员,或者(ii)可以从迁移学习中受益。
什么是迁移学习?
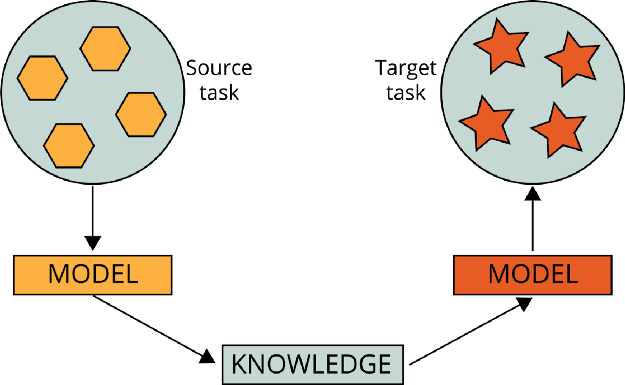
迁移学习是机器学习和人工智能的一个分支,其目的是将从一个任务(源任务)中获得的知识应用到一个不同但相似的任务(目标任务)中。
例如,在学习对维基百科文本进行分类时获得的知识可以用于解决法律文本分类问题。另一个例子是利用在学习对汽车进行分类时获得的知识来识别天空中的鸟类。这些样本之间存在关联。我们没有在鸟类检测上使用文本分类模型。
迁移学习是指从相关的已经学习过的任务中迁移知识,从而对新的任务中的学习进行改进
总而言之,迁移学习是一个让你不必重复发明轮子的领域,并帮助你在很短的时间内构建AI应用。
迁移学习的历史
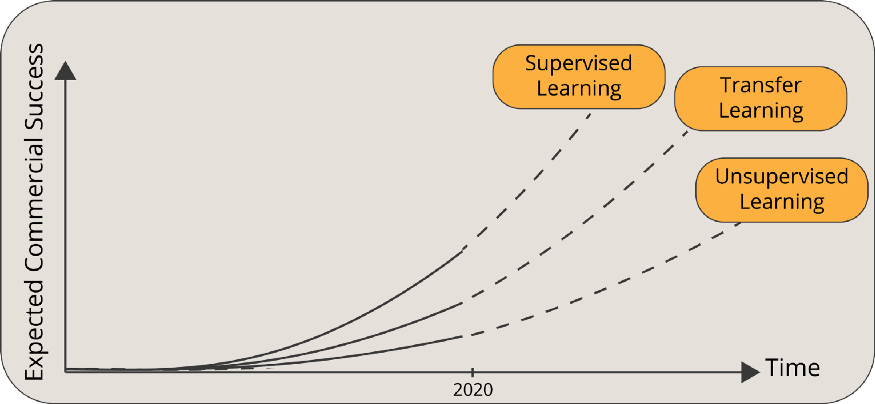
为了展示迁移学习的力量,我们可以引用Andrew Ng的话:
迁移学习将是继监督学习之后机器学习商业成功的下一个驱动因素
迁移学习的历史可以追溯到1993年。Lorien Pratt的论文“Discriminability-Based Transfer between Neural Networks”打开了潘多拉的盒子,向世界介绍了迁移学习的潜力。1997年7月,“Machine Learning”杂志发表了一篇迁移学习论文专刊。随着该领域的深入,诸如多任务学习等相邻主题也被纳入迁移学习领域。“Learning to Learn”是这一领域的先驱书籍之一。如今,迁移学习是科技企业家构建新的人工智能解决方案、研究人员推动机器学习前沿的强大源泉。
迁移学习是如何工作的?
实现迁移学习有三个要求:
由第三方开发开源预训练模型
重用模型
对问题进行微调
开发开源预训练模型
预训练的模型是由其他人创建和训练来解决与我们类似的问题的模型。在实践中,几乎总是有人是科技巨头或一群明星研究人员。他们通常选择一个非常大的数据集作为他们的基础数据集,比如ImageNet或Wikipedia Corpus。然后,他们创建一个大型神经网络(例如,VGG19有143,667,240个参数)来解决一个特定的问题(例如,这个问题用VGG19做图像分类。)当然,这个预先训练过的模型必须公开,这样我们就可以利用这些模型并重新使用它们。
重用模型
在我们掌握了这些预先训练好的模型之后,我们重新定位学习到的知识,包括层、特征、权重和偏差。有几种方法可以将预先训练好的模型加载到我们的环境中。最后,它只是一个包含相关信息的文件/文件夹。然而,深度学习库已经托管了许多这些预先训练过的模型,这使得它们更容易访问:
TensorFlow Hub
Keras Applications
PyTorch Hub
你可以使用上面的一个源来加载经过训练的模型。它通常会有所有的层和权重,你可以根据你的意愿调整网络。
对问题进行微调
现在的模型也许能解决我们的问题。对预先训练好的模型进行微调通常更好,原因有两个:
这样我们可以达到更高的精度。
我们的微调模型可以产生正确的格式的输出。
一般来说,在神经网络中,底层和中层通常代表一般的特征,而顶层则代表特定问题的特征。由于我们的新问题与原来的问题不同,我们倾向于删除顶层。通过为我们的问题添加特定的层,我们可以达到更高的精度。
在删除顶层之后,我们需要放置自己的层,这样我们就可以得到我们想要的输出。例如,使用ImageNet训练的模型可以分类多达1000个对象。如果我们试图对手写数字进行分类(例如,MNIST classification),那么最后得到一个只有10个神经元的层可能会更好。
在我们将自定义层添加到预先训练好的模型之后,我们可以用特殊的损失函数和优化器来配置它,并通过额外的训练进行微调。
计算机视觉中的4个预训练模型
这里有四个预先训练好的网络,可以用于计算机视觉任务,如图像生成、神经风格转换、图像分类、图像描述、异常检测等:
VGG19
Inceptionv3 (GoogLeNet)
ResNet50
EfficientNet
让我们一个一个地深入研究。
VGG-19
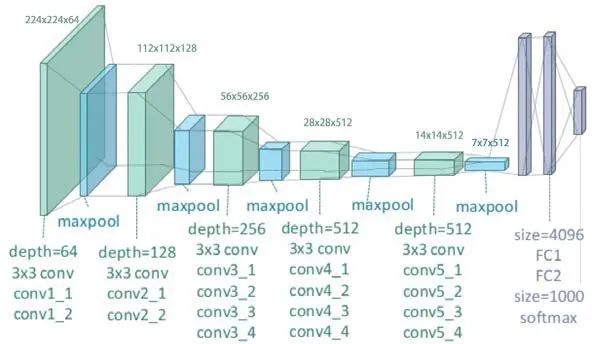
VGG是一种卷积神经网络,深度为19层。它是由牛津大学的Karen Simonyan和Andrew Zisserman在2014年构建和训练的,论文为:Very Deep Convolutional Networks for large Image Recognition。VGG-19网络还使用ImageNet数据库中的100多万张图像进行训练。当然,你可以使用ImageNet训练过的权重导入模型。这个预先训练过的网络可以分类多达1000个物体。对224x224像素的彩色图像进行网络训练。以下是关于其大小和性能的简要信息:
大小:549 MB
Top-1 准确率:71.3%
Top-5 准确率:90.0%
参数个数:143,667,240
深度:26
Inceptionv3 (GoogLeNet)
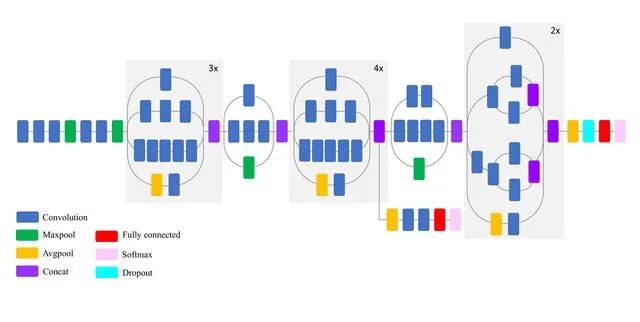
Inceptionv3是一个深度为50层的卷积神经网络。它是由谷歌构建和训练的,你可以查看这篇论文:“Going deep with convolutions”。预训练好的带有ImageNet权重的Inceptionv3可以分类多达1000个对象。该网络的图像输入大小为299x299像素,大于VGG19网络。VGG19是2014年ImageNet竞赛的亚军,而Inception是冠军。以下是对Inceptionv3特性的简要总结:
尺寸:92 MB
Top-1 准确率:77.9%
Top-5 准确率:93.7%
参数数量:23,851,784
深度:159
ResNet50 (Residual Network)
ResNet50是一个卷积神经网络,深度为50层。它是由微软于2015年建立和训练的,论文:[Deep Residual Learning for Image Recognition](http://deep Residual Learning for Image Recognition /)。该模型对ImageNet数据库中的100多万张图像进行了训练。与VGG-19一样,它可以分类多达1000个对象,网络训练的是224x224像素的彩色图像。以下是关于其大小和性能的简要信息:
尺寸:98 MB
Top-1 准确率:74.9%
Top-5 准确率:92.1%
参数数量:25,636,712
如果你比较ResNet50和VGG19,你会发现ResNet50实际上比VGG19性能更好,尽管它的复杂性更低。你也可以使用更新的版本,如ResNet101,ResNet152,ResNet50V2,ResNet101V2,ResNet152V2。
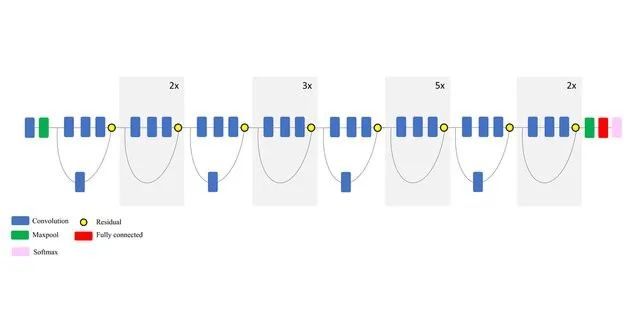
EfficientNet
EfficientNet是一种最先进的卷积神经网络,由谷歌在2019年的论文“efficient entnet: Rethinking Model Scaling for convolutional neural Networks”中训练并发布。EfficientNet有8种可选实现(B0到B7),甚至最简单的EfficientNet B0也是非常出色的。通过530万个参数,实现了77.1%的最高精度性能。
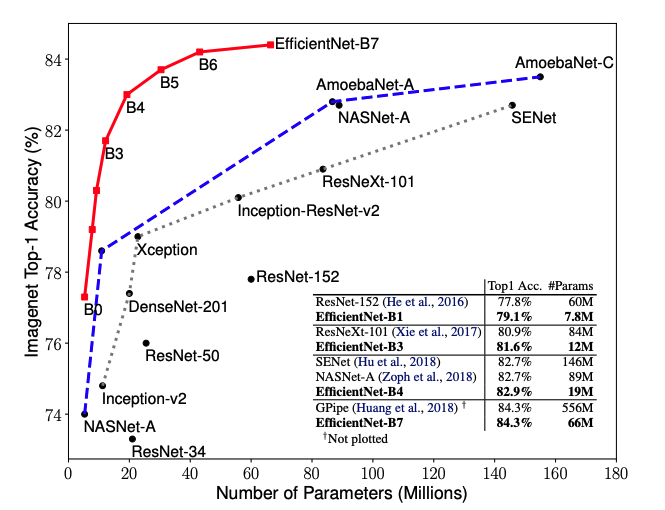
EfficientNetB0的特性简要介绍如下:
尺寸:29 MB
Top-1 准确率:77.1%
Top-5 准确率:93.3%
参数数量:~5,300,000
深度:159
其他的计算机视觉问题的预训练模型
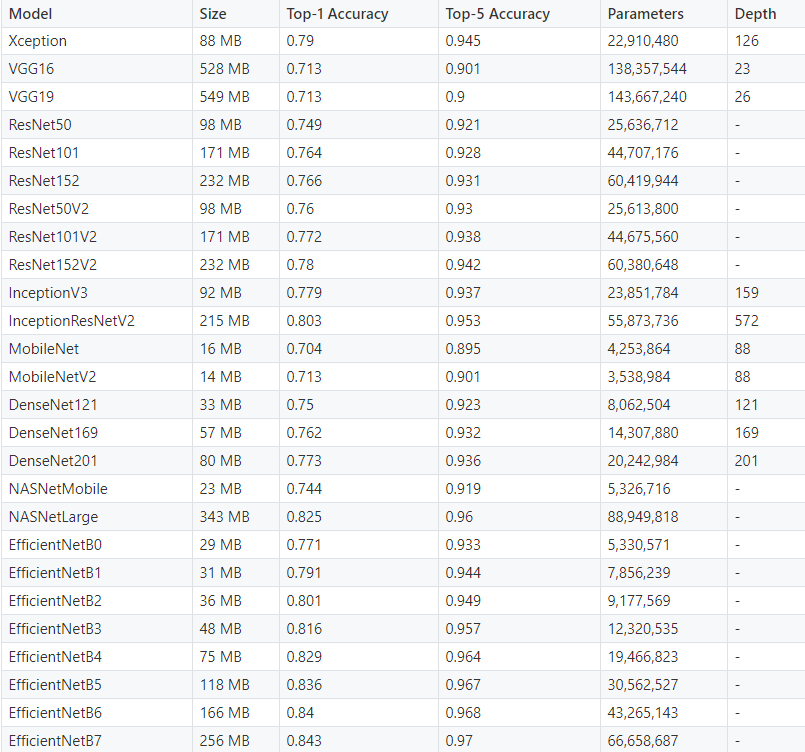
我们列出了四种最先进的获奖卷积神经网络模型。然而,还有几十种其他模型可供迁移学习使用。下面是对这些模型的基准分析,这些模型都可以在Keras Applications中获得。
总结
在一个我们可以很容易地获得最先进的神经网络模型的世界里,试图用有限的资源建立你自己的模型就像是在重复发明轮子,是毫无意义的。
相反,尝试使用这些训练模型,在上面添加一些新的层,考虑你的特殊计算机视觉任务,然后训练。其结果将比你从头构建的模型更成功。
审核编辑:刘清
-
人工智能
+关注
关注
1800文章
48083浏览量
242164 -
计算机视觉
+关注
关注
8文章
1703浏览量
46245 -
机器学习
+关注
关注
66文章
8460浏览量
133414 -
卷积神经网络
+关注
关注
4文章
368浏览量
11987
原文标题:4个计算机视觉领域常用迁移学习模型
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论