 机器学习相关介绍:没有免费午餐定理
机器学习相关介绍:没有免费午餐定理
一、没有免费午餐定理
1995年,D.H.Wolpert等人提出没有免费午餐定理(No Free Lunch Theorem)。该定理具体描述为:任何一个预测函数,如果在一些训练样本上表现好,那么必然在另一些训练样本上表现不好,如果不对数据在特征空间的先验分布有一定假设,那么表现好与表现不好的情况一样多。因此,没有一个机器学习算法在任何情况下表现均优。
二、未假设先验分布的预测
假设一台计算机只有两个存储单元,并假设计算机的存储单元不是属于第一类就是属于第二类。当已知一个存储单元属于第一类,预测另一个存储单元的类别。该预测问题可能包含两种情况:
(1)第一个和第二个存储单元均属于第一类。
(2)第一个存储单元属于第一类,第二个存储单元属于第二类。
若没有假设两种情况的先验概率分布(即默认两种情况先验概率相同),则两种情况出现的概率相同。此时,无论预测第二个存储单元属于哪种类别,正确或错误预测的概率均为50%。
当假设计算机的存储单元为三个或三个以上时,正确或错误预测每个存储单元的概率均为50%(如图一所示,图一中圆圈代表第一类,叉代表第二类)。
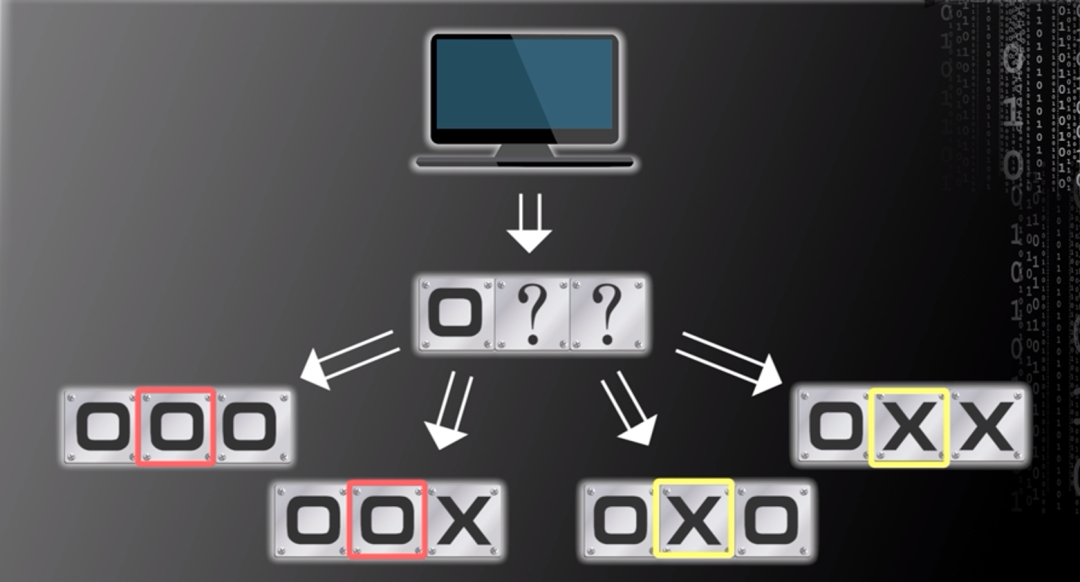
图一,图片来源:中国慕课大学《机器学习概论》 因此,即使增加已知存储单元类别的个数,正确或错误预测每个未知存储单元的概率也为50%。
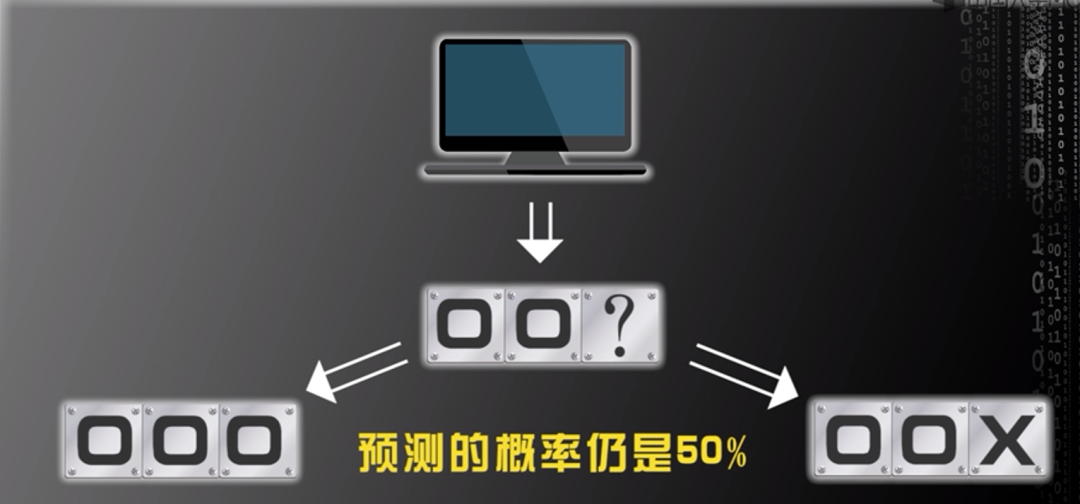
图片来源:中国慕课大学《机器学习概论》 综上,可得到推论:无论计算机的存储单元有多少,无论已知多少个类别信息,如果默认各种情况先验概率相同,正确预测的概率均为50%。即默认各种情况先验概率相同的情况下,所有的机器学习算法与随机猜测的结果相同。 三、假设先验分布的预测 如图二所示,如果预测图中问号处的图形,则多数人可能预测偏上的问号是圈,偏下的问号是叉。该预测与所有流行的机器学习算法做出的预测相同。
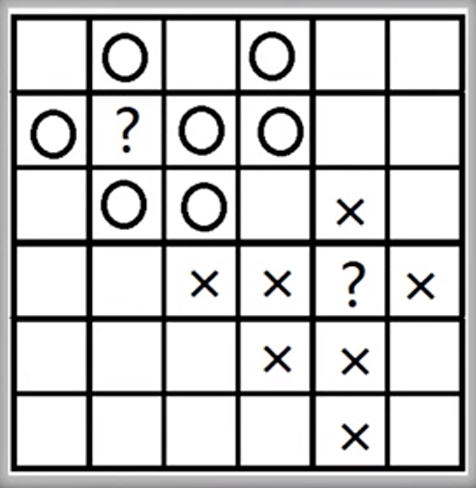
图二,图片来源:中国慕课大学《机器学习概论》 机器学习算法偏向做出上述预测的原因是开发人员在设计机器学习算法时假设:在特征空间上距离接近的样本属于同一类别的概率更高。基于此假设,图二中问号处图形的各种情况先验概率不同。偏上的问号是圆圈的先验概率高,是叉的先验概率低;偏下的问号是叉的先验概率高,是圆圈的先验概率低。
四、先验假设是否准确的讨论 先验假设不一定准确,下文举例说明。
例一:假设明天太阳会照常升起。该假设基于人们数千次或数万次看见太阳升起,基于过去的书籍中对太阳升起的多次记录,基于如万有引力的论证,并通过类比推广得出。此种方式得出的假设不能保证基于该假设的预测结果准确率达到100%。
例二:图二的预测中,如果圆圈代表花朵,叉代表蜜蜂,那么偏上的问号处可能是蜜蜂,该蜜蜂落入花丛中,并通知其他蜜蜂到此地采蜜。
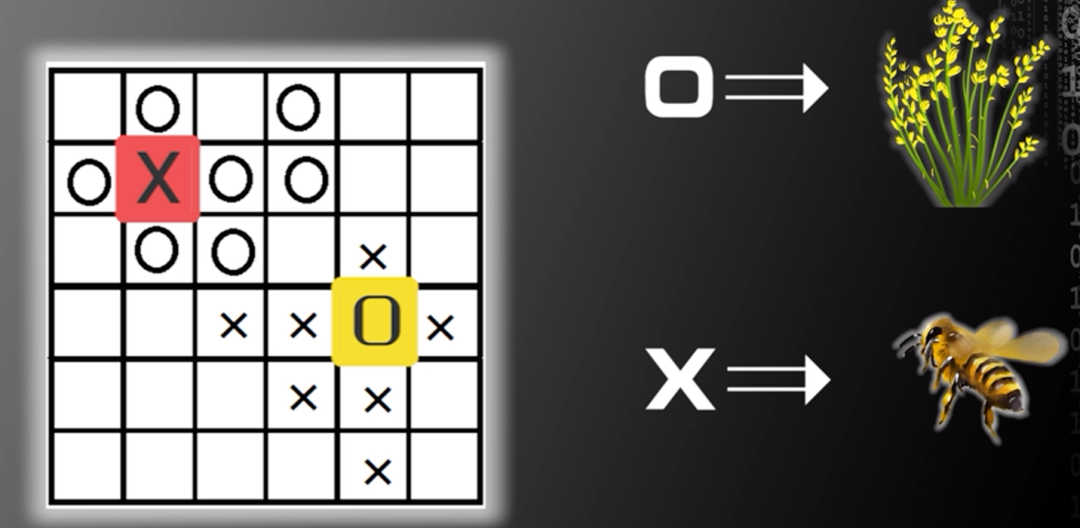
图片来源:中国慕课大学《机器学习概论》
审核编辑 :李倩
-
算法
+关注
关注
23文章
4646浏览量
93717 -
计算机
+关注
关注
19文章
7575浏览量
89098 -
云机器学习
+关注
关注
0文章
2浏览量
1859
原文标题:机器学习相关介绍(5)——没有免费午餐定理
文章出处:【微信号:行业学习与研究,微信公众号:行业学习与研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐








 工商网监
工商网监
评论