 不同的Verilog代码功耗与面积(PPA)差距能有多大?
不同的Verilog代码功耗与面积(PPA)差距能有多大?
ISP模块中的同样功能,两份代码,仿真功能都是OK的,区别是多打了一拍。PCLK时钟30MHz,且两个hsync脉冲之间的blanking是满足line_buf中数据移位输出的,如果不满足呢,那就必须多锁存一拍。
此处,在blanking时间必足够的情况下,经验丰富的老鸟可以敏锐发现问题,右下代码重复锁存,可能有提高timing的效果但并不明显,同时也浪费了19200个寄存器,存在面积浪费,那么实战一下,来对比下PPA的区别,结果一定让你“惊喜”。
优化前能跑25ns周期,即频点最大可到40MHz,
优化后能跑20ns周期,即频点最大可到50MHz,Performance性能提高25%。
PR结果:
RTL优化前如下:Density:59.67%,Gates=427032 Cells=65286 Area=3214018.7 um^2
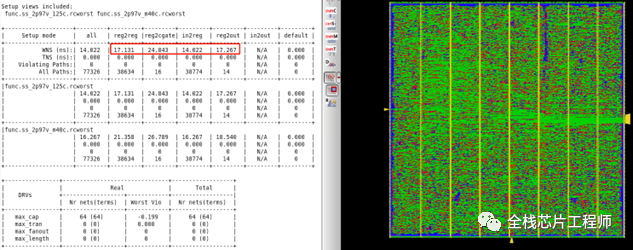
RTL优化后如下:Density:36.29%,Gates=259699 Cells=48340 Area=1954598.6 um^2
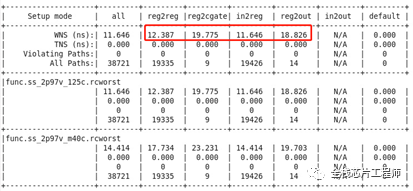
PR结论:gate从427032门降低到了259699门,节省了40%面积。在布线面积足够、timing都满足情况下,本次RTL优化节省了30%功耗、40%面积。
RTL设计优化永远止境,ICer要反复思考,追求PPA极致。
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Verilog
+关注
关注
28文章
1351浏览量
110100 -
RTL
+关注
关注
1文章
385浏览量
59786 -
Verilog语言
+关注
关注
0文章
113浏览量
8233 -
PPA
+关注
关注
0文章
21浏览量
7496
原文标题:不同的Verilog代码,性能、功耗、面积(PPA)差距能有多大?
文章出处:【微信号:全栈芯片工程师,微信公众号:全栈芯片工程师】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
数字前端生存指南—PPA
PPA是数字IC设计逃不开的概念,分别是P(Performance)、P(Power)和A(Area),分别代表芯片的性能、功耗和面积。
PPA分析概述
本材料的预期受众是任何级别的系统设计师,或任何其他具有对深入了解如何选择单个IP并将其组合成自定义SoC.功率、性能和面积(PPA)分析收集与以下各项相关的数据三个类别。除了成本之外,通常还需要
发表于 08-08 06:20
Verilog代码书写规范
Verilog代码书写规范
本规范的目的是提高书写代码的可读性、可修改性、可重用性,优化代码综合和仿真的结果,指导设计工程师使用
发表于 04-15 09:47
•106次下载
Verilog代码覆盖率检查
Verilog代码覆盖率检查是检查验证工作是否完全的重要方法,代码覆盖率(codecoverge)可以指示Verilog代码描述的功
发表于 04-29 12:35
•8430次阅读
中美医疗水平差距有多大?
中美医疗水平差距究竟有多大?中国这些年在医疗水平上全面赶超欧美了吗?近日,一位上海医生网友在知乎上关于中美医疗技术水平差距的回答,让医疗界网友直呼为深度好文:“一针见血,字字珠玑,太深刻了!”
什么样的Verilog代码风格是好的风格?
写代码是给别人和多年后的自己看的。 关于Verilog代码设计的一些风格和方法之前也写过一些Verilog有什么奇技淫巧?





 工商网监
工商网监
评论