 什么是无声语音接口?
什么是无声语音接口?
可穿戴设备依赖于具有标准物理能力的人机界面,如语音、触摸或运动。虽然这种形式的机器交互适用于大多数消费者,但残疾人可能很难或无法操作标准的可穿戴设备。为了使更多人能够使用可穿戴设备,研究人员正在研究新的人机界面。
最近,康奈尔大学的一个团队发表了一篇论文,描述了一副为不能发声的用户配备了无声语音接口(SSI)的智能眼镜。本文将讨论无声语音接口和来自康奈尔大学的可穿戴原型。
什么是无声语音接口?
无声语音接口(Silent speech interface,简称SSI)允许人们无需发声就能与机器互动。虽然AI助手(如苹果的Siri)等技术是通过声音交流工作的,但SSI通过与语音相关的动作来完成交流。
SSI技术通过嘴巴和舌头的运动而不是声音来识别语音。为了做到这一点,SSI依赖于各种不同的传感器,包括放置在嘴巴附近的振动传感器,用于检测人们嘴巴的振动,以及跟踪和分类与语音相关运动的摄像头。在许多情况下,这些信息会被机器学习算法处理,该算法会解释嘴巴的动作,并将其翻译成文字。
虽然大多数人可能找不到SSI的用途,但这项技术对于因疾病或受伤而失声的人来说是必不可少的,可以让他们更容易地交流。例如,患有声带损伤或影响语言的神经系统疾病的患者可以从SSI中获益良多。
康奈尔大学开发无摄像头SSI眼镜
最近,康奈尔大学的研究人员在SSI技术方面取得了重大进展,发明了基于SSI的智能眼镜。
该系统被称为EchoSpeech,是一种新颖的、侵入性最小的SSI技术,它使用低功率有源声学传感来捕捉由无声语音引起的细微皮肤变形,并将这些信息转换为可操作的数据。这款智能眼镜的原型建立在康奈尔大学之前对一种类似的声学传感可穿戴设备(“EarIO”)的研究基础上,EarIO可以从耳朵内追踪面部运动。
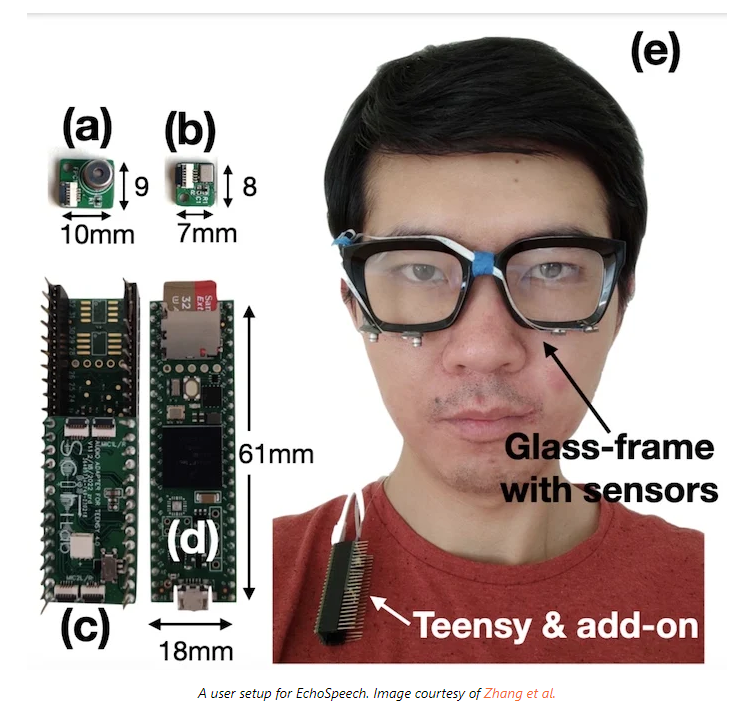
该系统依靠安装在眼镜框架上的一系列扬声器和麦克风向皮肤发射听不见的声波。发出的声波产生沿多条路径传播的回声,并被系统解释推断为佩戴者的无声语音。EchoSpeech完全可以在标准的智能手机上运行,只需要1到6分钟的训练数据,并以73.3 mW的低功耗实时运行。该团队的深度学习算法可以实时分析回声,准确率约为95%。
该系统通过12名用户研究进行了评估,成功展示了识别31个独立命令和三到六位连接数字的能力,单词错误率(WER)分别为4.5%(标准3.5%)和6.1%(标准4.2%)。此外,在行走和噪声注入等场景中测试了系统的鲁棒性。
更私密、低功耗、易使用
大多数SSI技术使用面部摄像头,从用户和与其交流的人那里收集数据。除了造成隐私问题外,可穿戴摄像头还会收集高带宽视频数据。
由于EchoSpeech不需要可穿戴摄像机,设备只捕捉音频数据,这比图像或视频数据需要的带宽要少得多,并且可以通过蓝牙实时发送到手机。隐私信息永远不会脱离用户的控制,因为数据是在智能手机上本地处理的(不用在云中处理)。研究人员表示,纯音频传感器的电池效率也更高:音频传感器可以工作10个小时,而摄像头只能工作30分钟。
康奈尔大学的研究小组表示,他们发现EchoSpeech在很多应用中都有应用价值,从默念密码来解锁智能手机,到跳过播放列表中的歌曲。该设备还可以与智能手机配对,在说话不方便的地方与他人交谈,比如嘈杂的餐厅或安静的图书馆。研究人员表示,该界面与手写笔和CAD等设计软件兼容,从而消除了对鼠标和键盘的需求。
审核编辑:刘清
-
人机界面
+关注
关注
5文章
526浏览量
44129 -
SSI
+关注
关注
0文章
38浏览量
19242 -
可穿戴设备
+关注
关注
55文章
3813浏览量
166997
原文标题:什么?无声语音接口?
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
omap4460开发板录音后播放无声音是怎么回事?
TLV320AIC33更换后数字mic无声音是怎么回事?
功放SR5200中置音箱无声音是什么原因?怎么解决?
TMS320C6000 MCBSP转语音带音频处理器(VBAP)接口

tas5711 EVM配置以后无声音输出是怎么回事?
TAS2552+AM4379为什么无声音输出?
TLV320AIC23B-Q1无声音输出的原因?
LM4916规格书中的BTL方案接后无声音输出,是什么问题呢?
LM4991 WSON封装手工搭建的电路,通电后扬声器无声音,为什么?
谷歌AI新突破:为无声视频智能配音
MCU配对简化了语音控制接口设计
微软发布视频编辑新功能:自动消除无声片段
未来之声 | 人形机器人说话篇:无声!






 工商网监
工商网监
评论