 文献综述:确保人工智能可解释性和可信度的来源记录
文献综述:确保人工智能可解释性和可信度的来源记录
最近,人工智能(AI)和机器学习(ML)模型在各个领域的应用都取得了显著的进展,相关讨论也在不断增多。学界认为,AI和ML模型应当是透明的,可解释的和可信的。
在此背景下,可解释AI(XAI)领域在迅速扩张。通过解释一些复杂模型,比如深度神经网络(DNN)结果如何生成,可解释AI在提高人工智能系统可信度和透明度方面前景广阔。此外,许多研究员和业内人士认为,使用数据起源去解释这些复杂的模型有助于提高基于人工智能系统的透明度。
本文对数据起源、可解释AI(XAI)和可信赖AI(TAI)进行系统的文献综述,以解释基本概念,说明数据起源文件可以用来提升基于人工智能系统实现可解释性。此外,文中还讨论了这个领域近期的发展模式,并对未来的研究进行展望。
对于有意了解关于数据起源,XAI和TAI的实质的诸多学者和业界人士,希望本文能成为助力研究的一个起点。
一文章提纲
1. 引言
2. XAI和TAI的基本概念
3. 数据起源, XAI, TAI的文献计量分析
4. 数据起源, XAI, TAI的关系的思考
5. 数据起源, XAI, TAI未来十年发展趋势
6. 结论
二内容总结
引言
人工智能的应用广泛,且对人类影响深远。但现有的模型只有结果而不涉及过程,因此,很多人担心这些模型不透明,不公平。比如“机器学习和深度学习是怎么工作,怎么产生结果”是一个黑箱问题。对此,有一个解决办法是通过XAI,也就是建设TAI去解释复杂模型。
作者引用文献阐述XAI和TAI的技术方法——数据起源的重要性和有效性。本文对这三者进行文献综述并关注他们在数据科学中的应用。基于关键词在Scopus文献库中进行文献搜索,采用滚雪球的策略研究2010年到2020年的论文。
XAI和TAI的基本概念
AI可解释性和可信度的背景
作者先列举了多例AI和机器学习的漏洞证明了提高可解释性的重要。又说明TAl的基本原则是建立合法透明的AI系统。然后列举各个国家在数据科学领域到XAI方法和战略计划,学者Wing扩充了计算机系统的维度,并认为需要权衡多种维度。
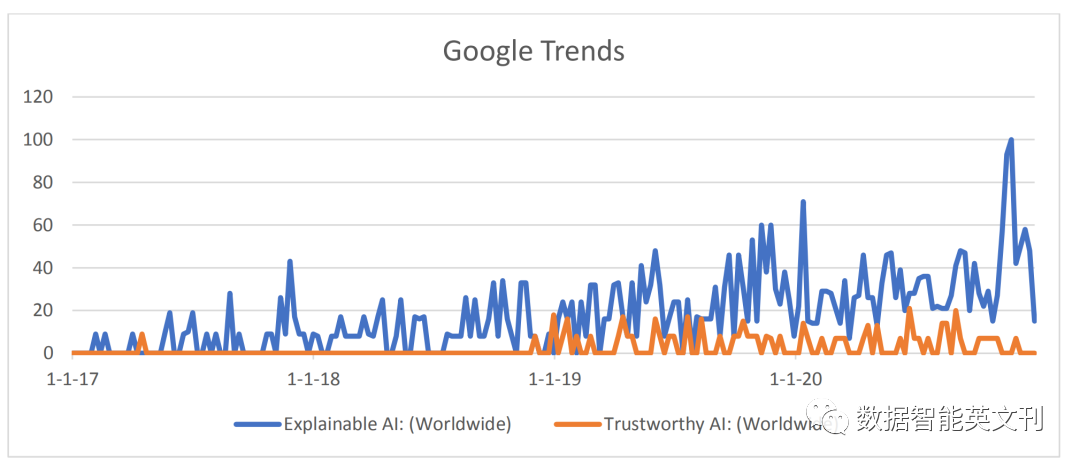
图1 XAI和TAI的谷歌趋势
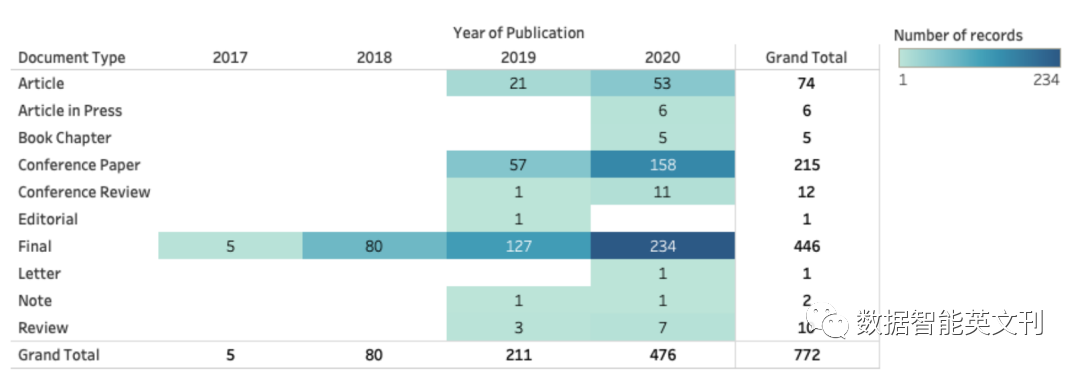
图2 文献库中论文的时间分布
实现XAI和TAI的技术途径
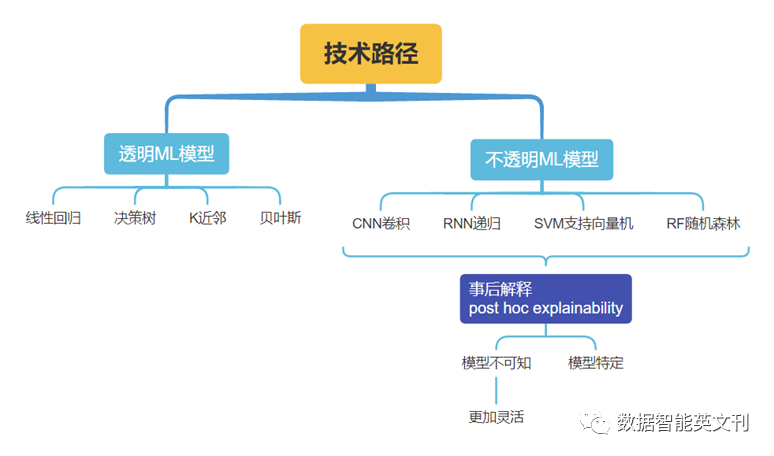
图3 ML模型分类及对应XAI方法
这些方法可以生成结果,但是为了增加AI系统的透明度,需要应用数据起源作为XAI的补充技术。
多方面的文献计量分析
文中进行文献计量分析去搜集这三者之间在论文中相互关联的证据。作者说明选择数据库的原因和查询的关键字以及分析工具是Bibliometrix和VOS Viewer。

图4 参考文献标题中的单词可视化词云
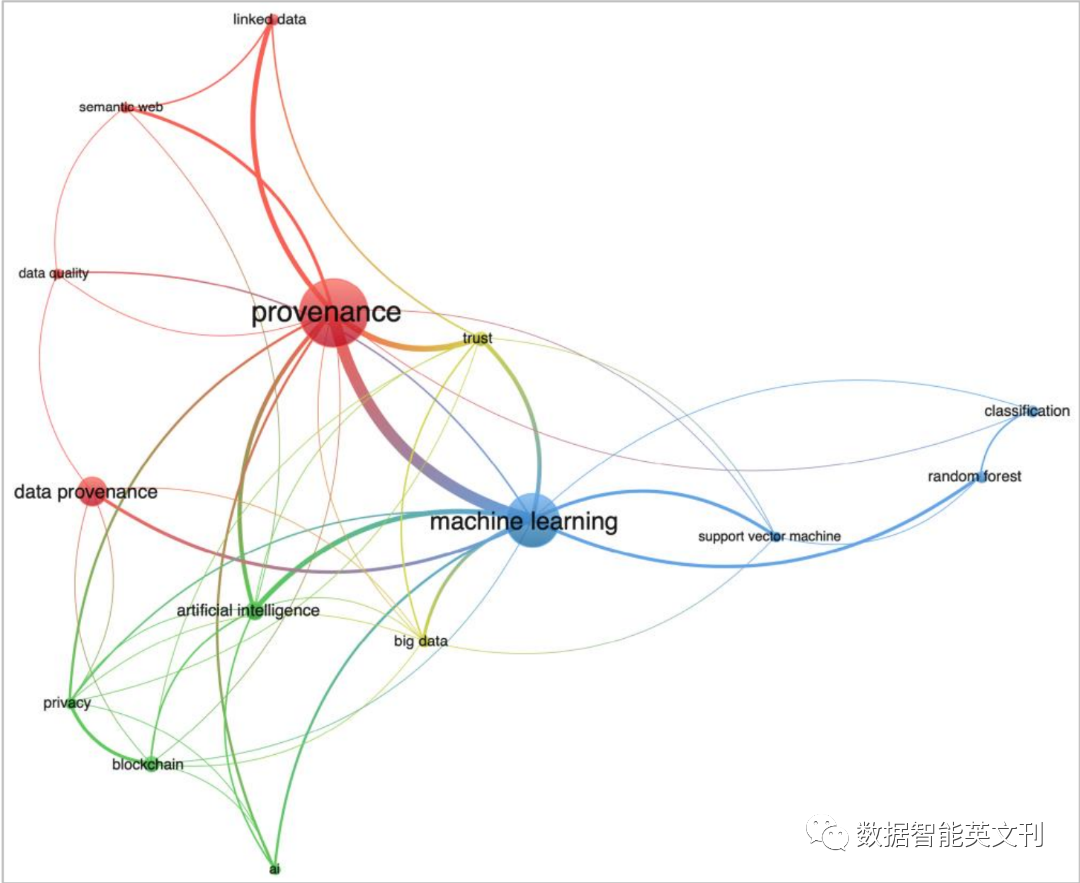
图5 关键词共现图聚类
三者关系思考
来源标准的关注度和相关工作增加
作者进行文献综述,整理研究主题后得出:
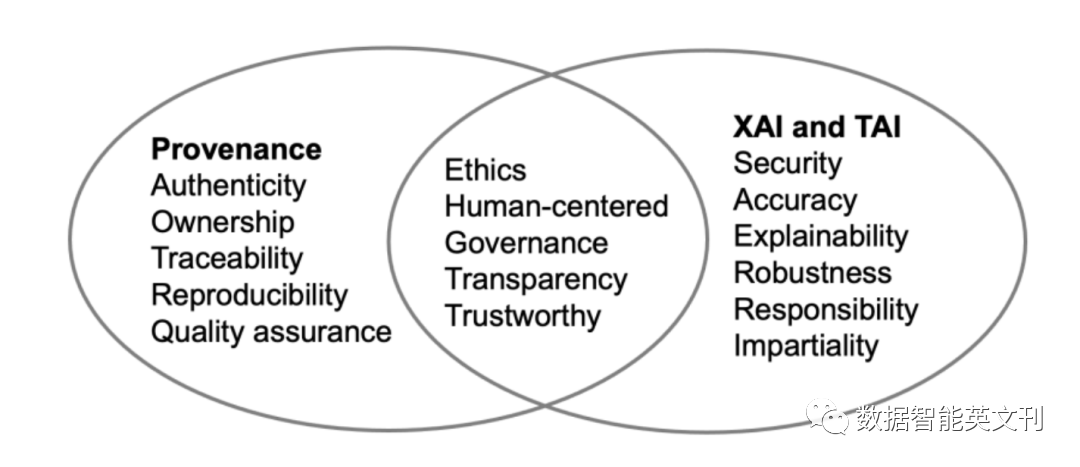
图6 三者话题相似度
文中也介绍了一些能够使得Provenance文档化的工具,比如W3C PROV本体,OpenML等。
数据起源实践及对XAI和TAI的支持
对于现实世界的实践,作者进行文献综述,讲述数据起源模型类别,W3C PROV的六个组件,然后作者简单介绍Renku等应用工具软件。
未来十年展望
本部分讨论了在AI/ML模型中造成偏差的原因,数据不可追踪,没有数据起源支持的决定是不可信的。
这项工作是社会-技术交叉领域问题,需要从两方面解决问题。
开发数据起源功能应用前应掌握用户需求
应开发更多的自动化工具记录数据起源,并将其标准化、使数据起源记录可查询可访问。
结论
用事后解释的方法来解释AI或机器学习模型是不够的,需要数据起源加入增加系统可信度和透明度。作者总结了文章行文顺序,强调数据起源对于XAI和TAI的重要性。
审核编辑 :李倩
-
神经网络
+关注
关注
42文章
4771浏览量
100752 -
自动化
+关注
关注
29文章
5570浏览量
79264 -
人工智能
+关注
关注
1791文章
47258浏览量
238417
原文标题:文献综述:确保人工智能可解释性和可信度的来源记录
文章出处:【微信号:AI智胜未来,微信公众号:AI智胜未来】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论