 基于神经匹配的二维地图视觉定位
基于神经匹配的二维地图视觉定位
主要内容:
提出了一种基于人类使用的2D语义图以亚米精度定位图像的算法,OrienterNet,通过将BEV图与OpenStreetMap中开放可用的全局地图相匹配来估计查询图像的位置和方向,使任何人都能够在任何可用地图的地方进行定位。 OrienterNet只受相机姿态的监督,学习以端到端的方式与各种地图元素进行语义匹配。引入了一个大规模的众包图像数据集,该数据集以汽车、自行车和行人的不同角度在12个城市进行拍摄得到。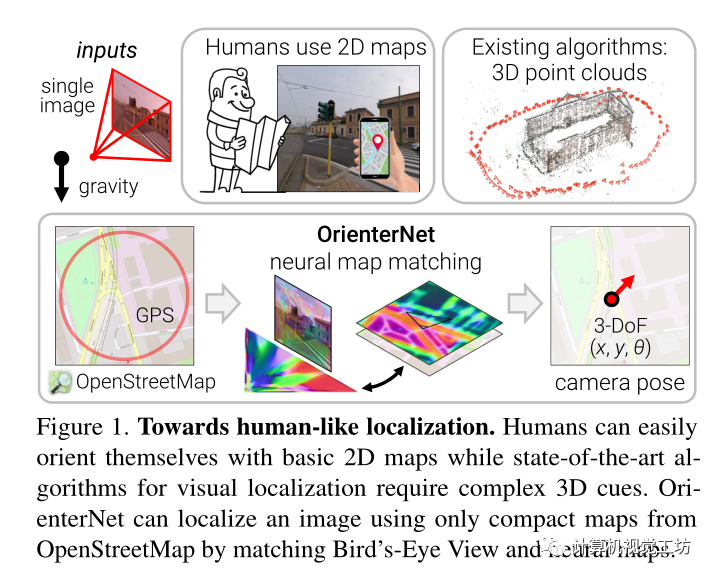
Motivation:
作为人类,我们直观地理解我们所看到的局部场景和我们所处场景的全局地图之间的关系。当我们迷失在未知区域时,我们可以通过使用不同的地理特征仔细比较地图和周围环境来准确定位我们的位置。
传统的视觉定位算法通常很复杂,其依赖于图像匹配,并且需要冗余的3D点云和视觉描述子,而且使用激光雷达或摄影测量构建3D地图是昂贵的,并且需要更新数据来捕捉视觉外观的变化,3D地图的存储成本也很高,因为它们比基本的2D地图大几个数量级。这些限制了其在移动设备上执行定位,现在的方法一般需要昂贵的云基础设施。
这就引出了一个重要的问题:我们如何像人类一样教机器从基本的2D地图进行定位? 本文就根据这个问题提出了第一种方法,该方法可以在给定人类使用的相同地图的情况下,以亚米精度定位单个图像和图像序列。
这些平面图只对少数重要物体的位置和粗略的二维形状进行编码,而不对其外观和高度进行编码。这样的地图非常紧凑,尺寸比3D地图小104倍,因此可以存储在移动设备上,并用于大区域内的设备上定位。该解决方案也不需要随着时间的推移构建和维护昂贵的3D地图,也不需要收集潜在的敏感地图数据。
其算法估计2D地图中图像的3-DoF姿态,位置和航向。
该估计是概率性的,因此可以在多相机设备或图像序列的多个视图之前或跨多个视图与不准确的GPS融合。所得到的解决方案比消费级GPS传感器准确得多,并且基于特征匹配达到了接近传统算法的精度水平。
使用的2D地图与传统地图的区别: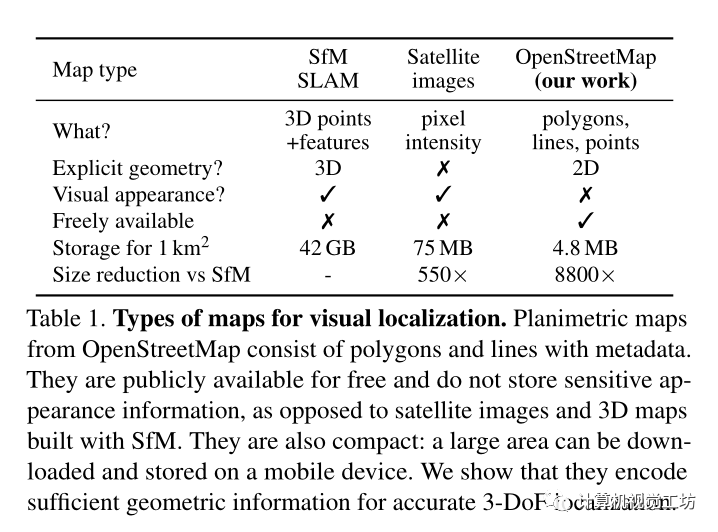
Pipeline: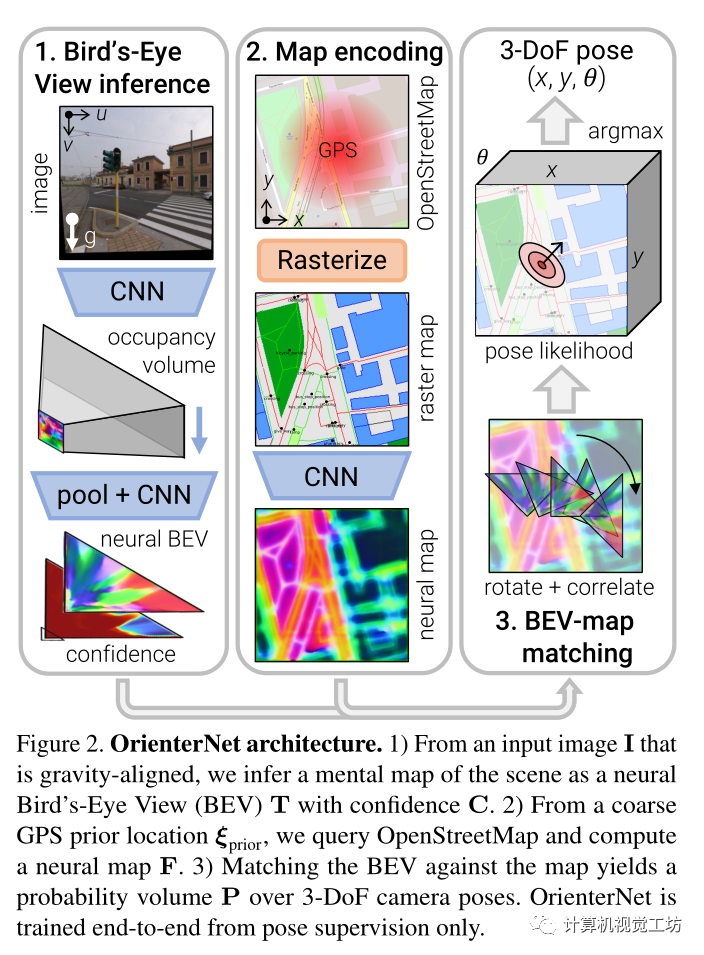
输入:
输入为具有已知相机内参的图像I。通过根据已知重力计算的单应性对图像进行校正,使其roll和tilt为零,然后其主轴为水平。还有一个粗略的位置先验ξ。从OpenStreetMap查询地图数据,将其作为以ξ先验为中心的正方形区域,其大小取决于先验的噪声程度。数据由多边形、线和点的集合组成,每个多边形、线或点都属于给定的语义类,其坐标在同一局部参考系中给定。
OrienterNet由三个模块组成:
1)图像CNN从图像中提取语义特征,并通过推断场景的3D结构将其提升为鸟瞰图(BEV)表示
2) OSM map由map-CNN编码为嵌入语义和几何信息的神经map F。
3) 通过将BEV与地图进行穷举匹配来估计相机姿态ξ上的概率分布
论文技术点:
鸟瞰图BEV推理:
从一个图像I中推断一个BEV表示 ,其分布在与相机截头体对齐的L×D的网格上,由N维特征组成,网格上每个特征都被赋予了一个置信度,有矩阵
,其分布在与相机截头体对齐的L×D的网格上,由N维特征组成,网格上每个特征都被赋予了一个置信度,有矩阵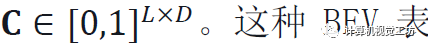 。
。
这种BEV表示类似于人类在地图中自我定位时从环境中推断出的心理地图。
图像和地图之间的跨模态匹配需要从视觉线索中提取语义信息,算法依靠单目推理将语义特征提升到BEV空间,分两步来获得神经BEV:
i)通过将图像列映射到极射线来将图像特征转移到极坐标表示
ii)将极坐标网格重新采样为笛卡尔网格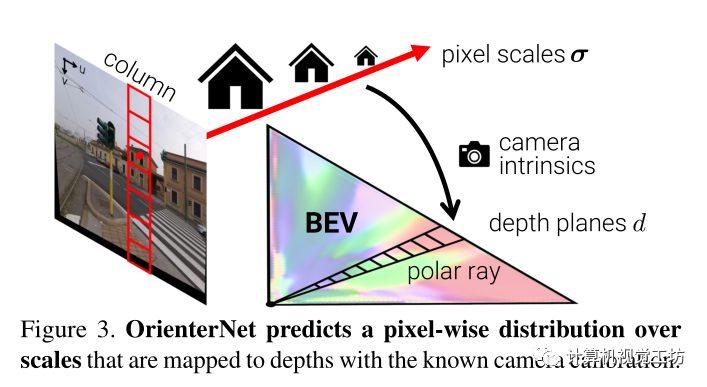
神经map编码:
将平面图编码为结合了几何和语义的W×H神经图
Map data:OpenStreetMap元素根据其语义类定义为多边形区域、多段线或单点。区域的例子包括建筑足迹、草地、停车场;线条包括道路或人行道中心线、建筑轮廓;点包括树木、公交车站、商店等。这些元素提供了定位所需的几何约束,而它们丰富的语义多样性有助于消除不同姿势的歧义。
预处理:首先将区域、线和点光栅化为具有固定地面采样距离
▲(例如50cm/pixel)的3通道图像。
编码:将每个类与学习的N维嵌入相关联,生成W×H×3N的特征图。然后通过一个CNN 将其编码到神经图F中,其提取有助于定位的几何特征。F不是归一化的,因为我们让Φ映射将其范数调制为匹配中的重要权重。F通常看起来像一个距离场,在那里我们可以清楚地识别建筑物的角落或相邻边界等独特特征。
基于模板匹配的姿态估计:
概率体:
估计一个相机姿态ξ上的离散概率分布。这是可解释的,并充分反映了估计的不确定性。因此在不明确的情况下,分布是多模式的。图4显示了各种示例。这样就可以很容易地将姿态估计与GPS等附加传感器相融合。计算这个体积是容易处理的,因为姿势空间已经减少到三维。它被离散化为每个地图位置和以规则间隔采样的K个旋转。 这产生了W×H×K概率体积P,使得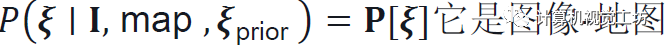
它是图像-地图匹配项M和位置先验的组合Ω:
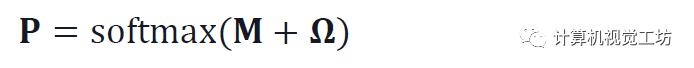
图像-地图匹配:
将神经map F和BEV T进行穷举匹配,得到分数体M。通过将F与由相应姿势变换的T相关来计算每个元素,如:
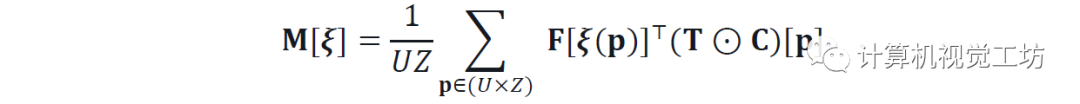
其中ξ(p)将2D点p从BEV变换为地图坐标系。置信度C掩盖相关性以忽略BEV空间的一些部分,例如被遮挡的区域。该公式得益于通过旋转T K次并在傅立叶域中执行作为分批乘法的单个卷积的有效实现。
姿态推断: 通过最大似然估计单个姿态: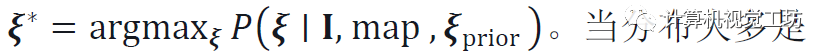 。当分布大多是单峰分布时,可以获得一个不确定性度量,作为P在ξ*周围的协方差。
。当分布大多是单峰分布时,可以获得一个不确定性度量,作为P在ξ*周围的协方差。
序列和多相机定位:
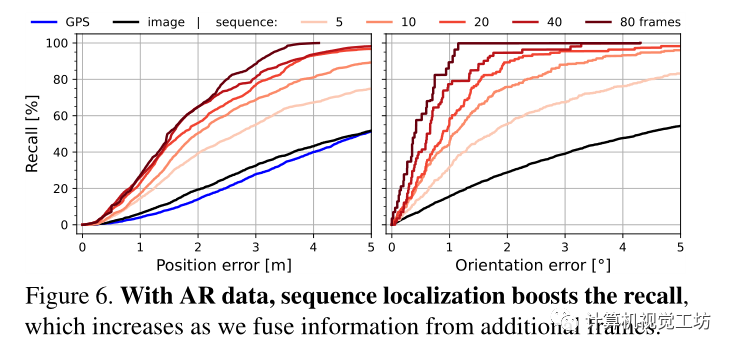
单图像定位在几乎没有表现出独特语义元素或重复模式的位置是模糊的。当多个视图的相对姿势已知时,可以通过在多个视图上积累额外的线索来消除这种挑战。这些视图可以是来自VI SLAM的具有姿势的图像序列,也可以是来自校准的多摄像机设备的同时视图。图5显示了这样一个困难场景的例子,通过随着时间的推移累积预测来消除歧义。不同的帧在不同的方向上约束姿势,例如在交叉点之前和之后。融合较长的序列会产生更高的精度(图6)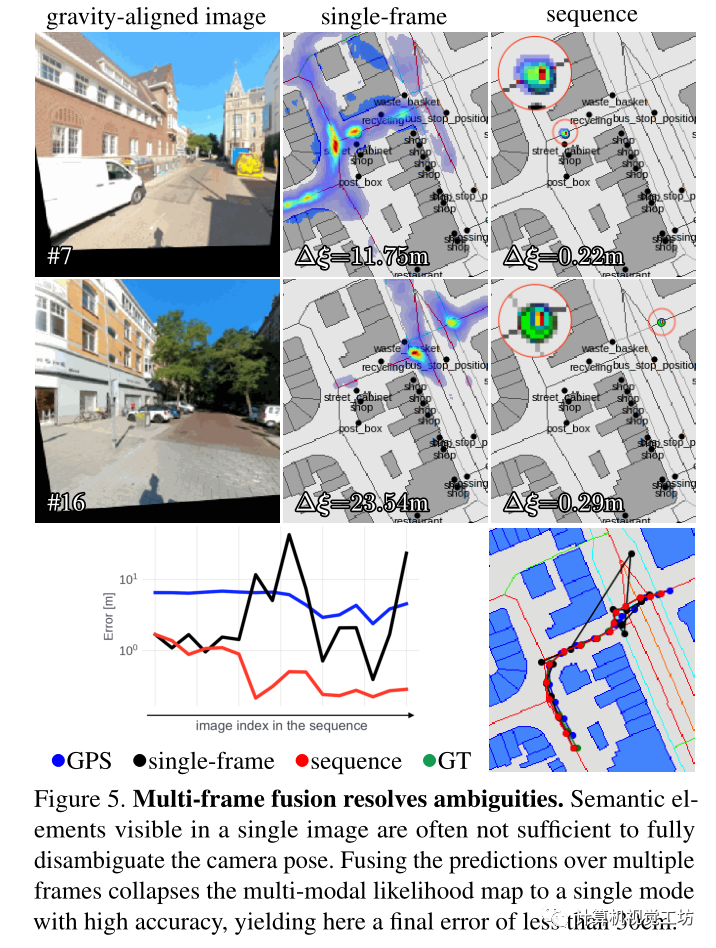
将ξi表示为视图i的未知绝对姿态,将ξij表示为视图j到i的已知相对姿态。对于任意参考视图i,将所有单视图预测的联合似然表示为:
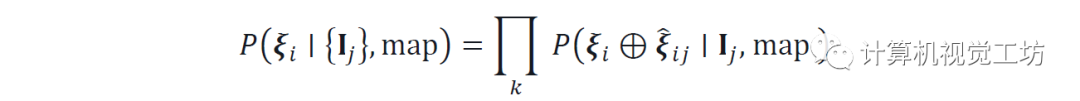
其中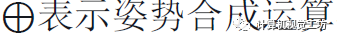
表示姿势合成运算符。这是通过将每个概率体积Pj扭曲到参考帧i来有效计算的。也可以通过迭代扭曲和归一化来定位连续流的每个图像,就像经典的马尔可夫定位一样。
实验:
在驾驶和AR的背景下评估了定位模型。图4显示了定性示例,而图5说明了多帧融合的有效性。
实验表明:
1)OrienterNet在2D地图定位方面比现有的深度网络更有效;
2) 平面图比卫星图像更准确地定位;
3) 在考虑多个视图时,OrienterNet比嵌入式消费级GPS传感器准确得多。
在MGL数据集的验证拆分上评估了OrienterNet的设计。这确保了摄像机、动作、观看条件和视觉特征的分布与训练集相同。报告了三个阈值1/3/5m和1/3/5°时的位置和旋转误差的召回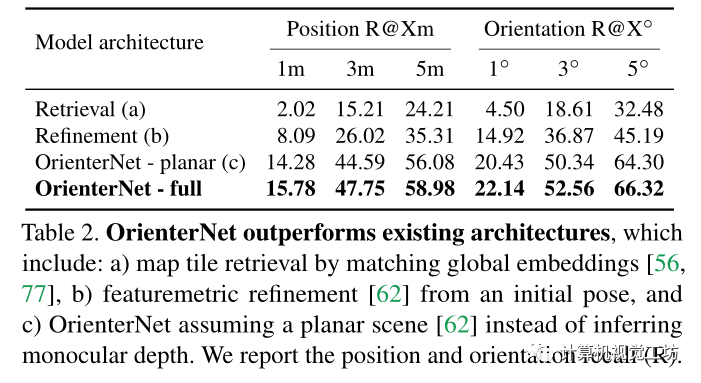
使用KITTI数据集考虑驾驶场景中的定位。为了评估零样本性能使用了他们的Test2分割,该分割与KITTI和MGL训练集不重叠。图像由安装在城市和住宅区行驶的汽车上的摄像头拍摄,并具有RTK的GT姿势。使用OSM map来扩充数据集。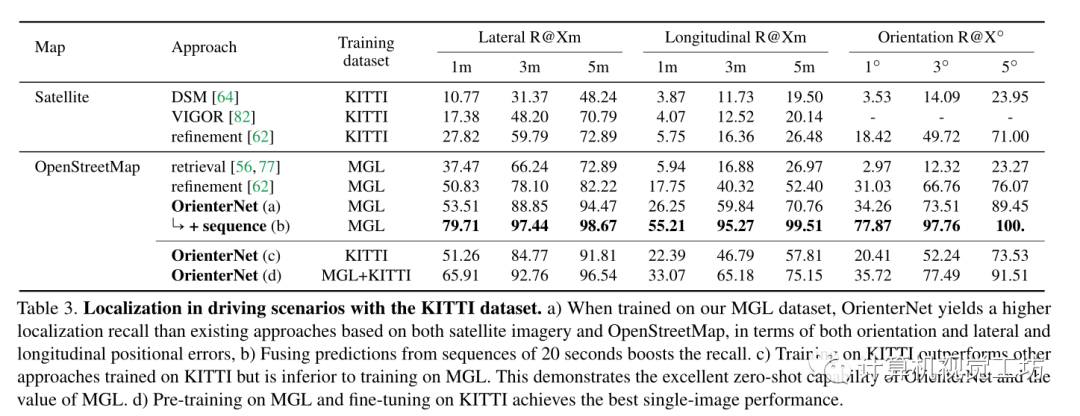
用于增强现实(AR)的头戴式设备的定位。 因为没有公共基准可以为在不同的户外空间使用AR设备拍摄的图像提供地理对齐的GT姿势。因此用Aria眼镜记录了自己的数据集。它展示了AR的典型模式,带有嘈杂的消费者级传感器和行人的视角和动作。 包括两个地点:i)西雅图市中心,有高层建筑;ii)底特律,有城市公园和较低的建筑。记录了每个城市的几个图像序列,所有图像序列都大致遵循多个街区的相同循环。
记录每幅校准的RGB图像和GPS测量值,并从离线专有的VI SLAM系统中获得相对姿态和重力方向。通过基于GPS、VI约束和OrienterNet的预测联合优化所有序列来获得伪GT全局姿态。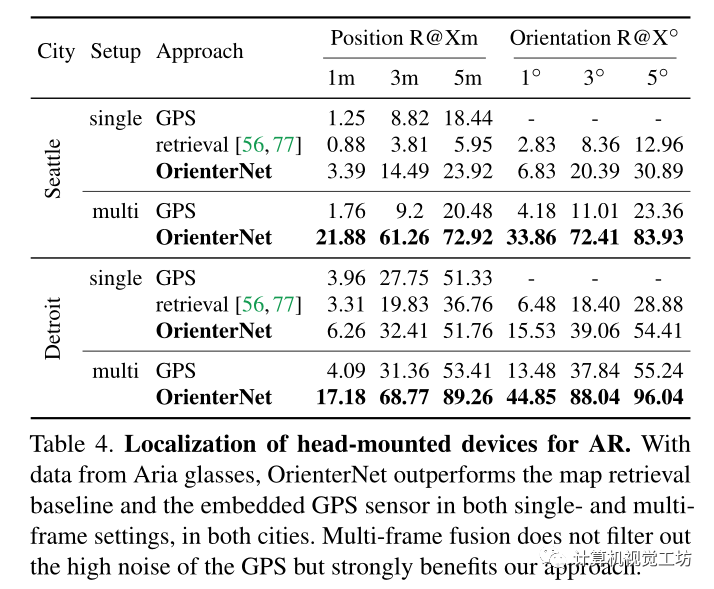
总结:
OrienterNet是第一个深度神经网络,可以在人类使用的2D平面图中以亚米精度定位图像。OrienterNet通过将输入地图与源自视觉观察的心理地图相匹配,模仿人类在环境中定位自己的方式。与机器迄今为止所依赖的大型且昂贵的3D地图相比,这种2D地图非常紧凑,因此最终能够在大型环境中进行设备上定位。OrienterNet基于OpenStreetMap的全球免费地图,任何人都可以使用它在世界任何地方进行定位。
审核编辑:刘清
-
传感器
+关注
关注
2554文章
51546浏览量
757508 -
gps
+关注
关注
22文章
2904浏览量
166954
原文标题:ETH最新工作:基于神经匹配的二维地图视觉定位(CVPR2023)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
二维影像扫描引擎可以应用于哪些行业?

二维扫码头有效扫描距离是多少,影响二维扫描头扫码的因素有哪些

RS232接口的二维影像扫描引擎,广泛用在医疗设备上扫一维二维码

工业视觉在条码/二维码识别领域的应用

二维码识读设备有哪些类型

labview按行读取二维数组之后再按读取顺序重新组成二维数组如何实现?
agv叉车激光导航和二维码导航有什么区别?适用什么场景?选哪种比较好?
工业二维码扫描设备如何助力流水线生产?

如何为柜式终端设备选配(集成)二维码模块?

技术|二维PDOA平面定位方案








 工商网监
工商网监
评论