 基于Diffusion Probabilistic Model的医学图像分割
基于Diffusion Probabilistic Model的医学图像分割

前言
在前面的一篇文章ICLR 2023:基于 diffusion adversarial representation learning 的血管分割中,我们已经介绍过了 diffusion model 在医学图像分割上的一个应用,推荐对 diffusion model 不了解的同学优先阅读,其中讲了一些基本概念。上一篇文章是将 diffusion 应用到自监督学习中,而 MedSegDiff 是一个有监督的框架,现在已更新到 V2 版本, V2 版本区别于 V1 使用了 Transformer,且适用于多分类。MedSegDiff-V1 已被接收在 MIDL 2023。
MedSegDiff
MedSegDiff 在原版 DPM 的基础上引入了动态条件编码,增强 DPM 在医学图像分割上的分步注意力能力。特征频率解析器(FF-Parser)可以消除分割过程中损坏的给定掩码中的高频噪声。DPM 是一种生成模型,由两个阶段组成,正向扩散阶段和反向扩散阶段。在正向过程中,通过一系列步骤 T,将高斯噪声逐渐添加到分割标签 x0 中。在反向过程中,训练神经网络通过反向噪声过程来恢复原始数据: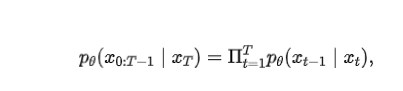
其中 theta 是反向过程参数。从高斯噪声开始,p(xT) 表示原始图像,反向过程将潜在变量分布 p(xT) 转换为数据分布 p(x0)。反向过程逐步恢复噪声图像,以获得最终的清晰分割。该模型使用 U-Net 作为学习网络,步长估计函数由原始图像先验条件确定:
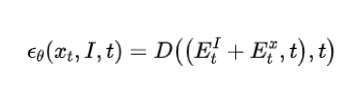
其中 EI 是条件特征嵌入,即原始图像嵌入,Ex 是当前步骤的分割映射特征嵌入。这两个组件被添加并发送到 U-Net 的解码器进行重建。步长索引 t 与新增的嵌入和解码器功能集成在一起,使用共享的 look-up table 进行嵌入,这在 DDPM 的论文中有介绍。总而言之,MedSegDiff 模型基于 DPM,使用 U-Net 进行学习。步长估计函数由原始图像先验得到,步长索引与新增的嵌入和解码器功能集成在一起。使 MedSegDiff 在三项具有不同图像模式的医学分割任务中表现不错。先看下 MedSegDiff 整体流程图:
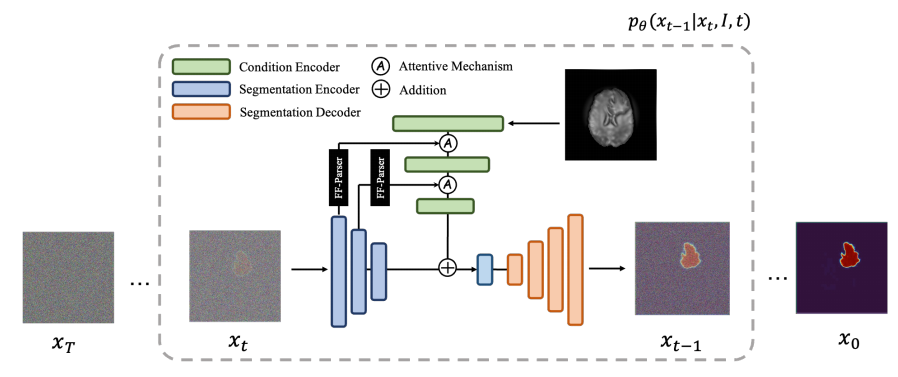
下面我们将逐一介绍动态条件编码和 FF-Parser。
动态条件编码
对于 MRI 或超声之类的低对比度图像,很难将感兴趣的对象与背景分开。所以使用动态条件编码方法来解决这个问题。可以注意到,原始图像包含准确的目标分割信息,不过很难与背景区分开,而当前步骤的 grand truth 包含增强的目标区域,但不准确。
为了整合这两个信息来源,使用类似注意力的机制将条件特征图的每个尺度与当前步骤的编码特征融合。这种融合是首先对两个特征图分别应用层归一化,然后将它们相乘以获得 affine map 来实现的,再将 affine map 与条件编码特征相乘以增强注意力区域。如 MedSegDiff 流程图所示,此操作应用于中间两个阶段,其中每个阶段都是在 Resnet34 之后实现的卷积阶段。但是,集成当前条件编码功能可能会产生额外的高频噪声。为了解决这个问题,使用 FF-Parser 来限制特征中的高频分量。
FF-Parser
FF-Parser 的流程如下图所示:
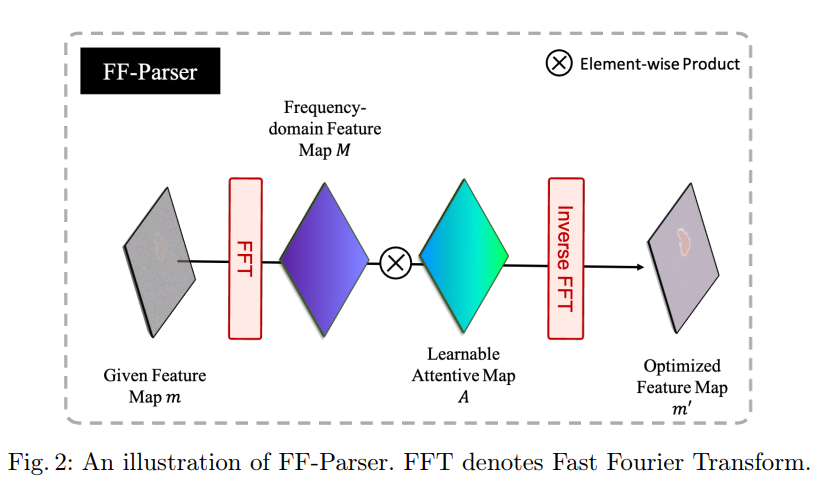
FF-Parser 是频率滤波器的可学习版本,它可以全局调整特定频率的分量,以限制高频分量进行自适应集成。首先使用二维 FFT(快速傅立叶变换)沿空间维度对解码器特征图 m 进行变换,生成频谱 M。然后,将参数化的注意力地图 A 与 M 相乘以调整频谱,得出 M'。最后,使用逆向 FFT 将 M' 反向回空间域,以获得修改后的特征图 m'。使用 FF-Parser 可以学习适用于傅里叶空间特征的权重图,该权重图可用于全局调整特定频率的分量。这种技术不同于空间注意力,后者调整特定空间位置的组成部分。
实验
下图分别是脑部 MRI、眼底视盘和甲状腺结节的超声图像分割结果的可视化,可以看出 MedSegDiff 在简单解刨结构的二分类上效果还是不错的。
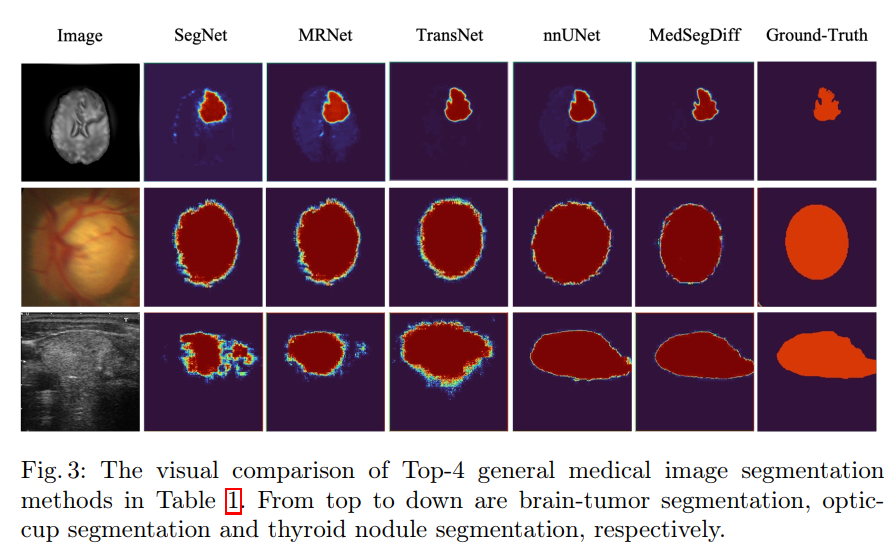
对比其他 SOTA 方法的结果如下表:
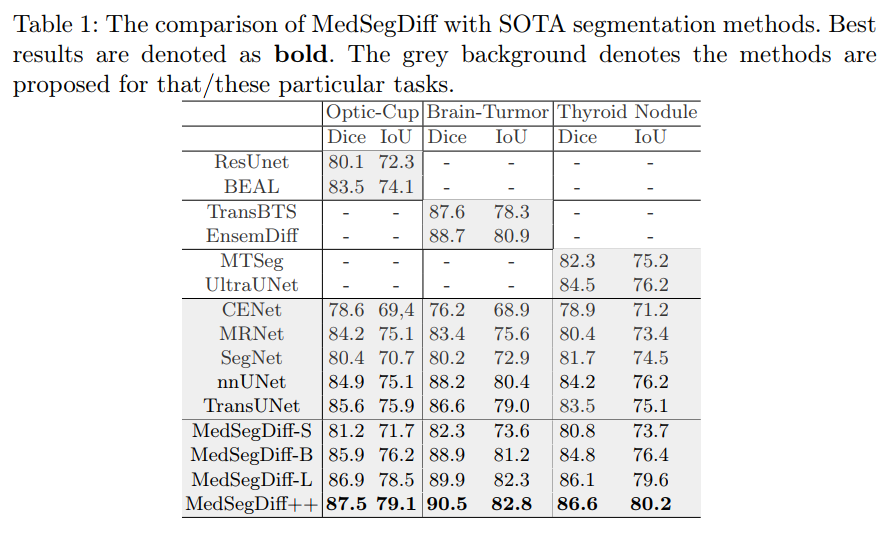
MedSegDiff-V2
MedsegDiff-v2 通过将 Transformer 机制整合到原始的U-Net骨干中,增强了基于扩散的 MedSegDiff-v1。具体来说,MedsegDiff-v2 引入了新的 Spectrum-Space Transformer(SS-former),对噪声和语义特征之间的相互作用进行建模。验证了 Medsegdiff-v2 对具有不同模态图像的五个分割数据集的十八个器官的有效性。
概述
如下图所示,MedsegDiff-v2 结合了锚点条件和语义条件两种不同的条件方式,以提高扩散模型的性能。锚点条件将锚分割特征(条件模型的解码分割特征)集成到扩散模型的编码特征中。即允许使用粗略但静态的参照来初始化扩散模型,有助于减少扩散方差。
然后将语义条件强加于扩散模型的 embedding,理解为将条件模型的语义 embedding 集成到扩散模型的 embedding 中。这种条件集成由 SS-former 实现,它弥合了噪声和语义嵌入之间的鸿沟,并利用 Transformer 的全局和动态特性抽象出更强的特征表达形式。
Medsegiff-v2 是使用 DPM 的标准噪声预测损失 Lnoise 和锚损失 Lanchor 进行训练的。Lanchor 是 Dice loss 和 CE loss 的组合。总损失函数表示为: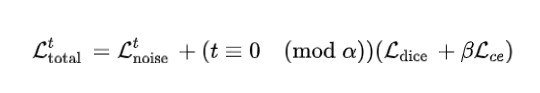
其中 t ≡ 0 (mod α) 通过超参数 α 控制监督条件模型的时间,β 是另一个用于加权交叉熵损失的经验超参数。总而言之,Medsegdiff-v2 显著提高了 MedsegDiff 的性能。该方法采用了新的基于 Transformer 的条件 U-Net 框架和两种不同的条件方式,以提高扩散模型的性能。
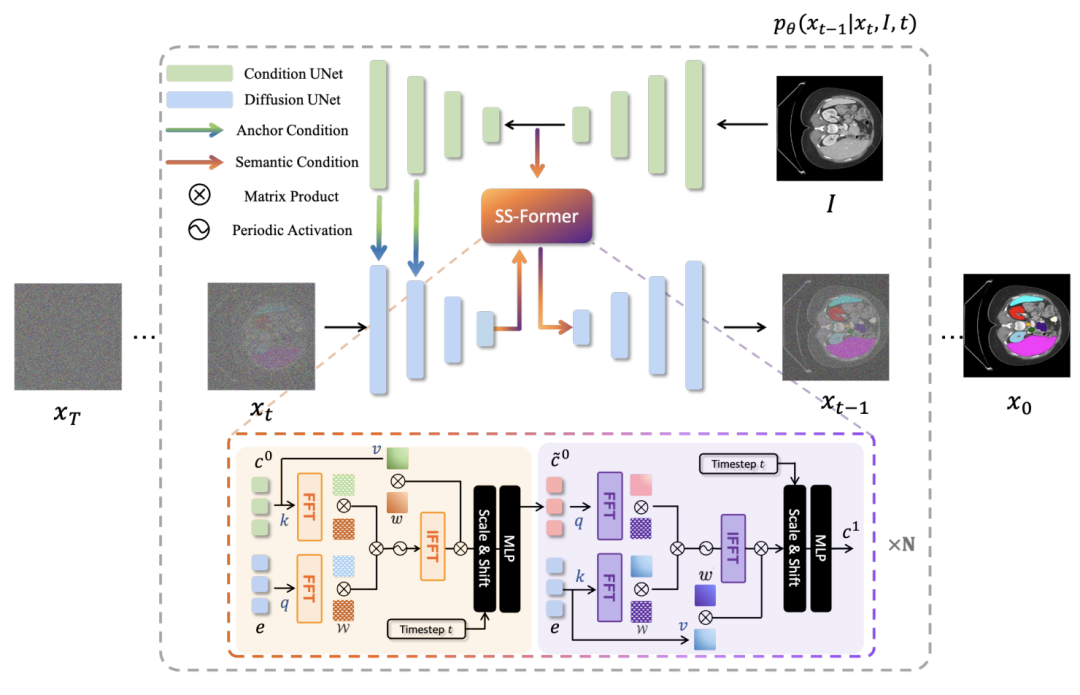
Anchor Condition with Gaussian Spatial Attention
与卷积层相比,Transformer 具有更强的表示性,但对输入方差更敏感。为了克服这种负面影响,所以使用了锚条件运算,如上面概述中的介绍,该运算将条件模型的解码分割特征(锚点)集成到扩散模型的编码器特征中。此外,还使用了高斯空间注意力来表示条件模型中给定分割特征的不确定性(概率)。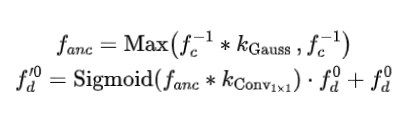
在第一个公式中,表示在锚点特征上应用高斯核以进行平滑激活,因为锚点可能不完全准确,且高斯核的均值和方差是可以学习的。选择平滑 ground truth 和原始图之间的最大值以保留最相关的信息,从而生成平滑的锚特征。在第二个公式中,将平滑锚点特征集成到扩散模型中以获得增强特征。首先应用 1x1 卷积将锚特征中的通道数减少到 1(经常作用于解码器的最后一层)。最后,在锚点特征上使用 sigmoid 激活函数,将其添加到扩散模型的每个通道中,类似于空间注意力的实现。
Semantic Condition with SS-Former
关于 SS-Former 的作用,我们只做简单的总结。对比 MedSegDiff-v1,是一种将条件模型分割 embedding 集成到扩散模型 embedding 中的新架构,其使用频谱空间注意力机制来解决扩散和分割 embedding 之间的域差距。此外,注意力机制在傅里叶空间中合并语义和噪声信息,和 MedSegDiff-v1 是类似的。
实验
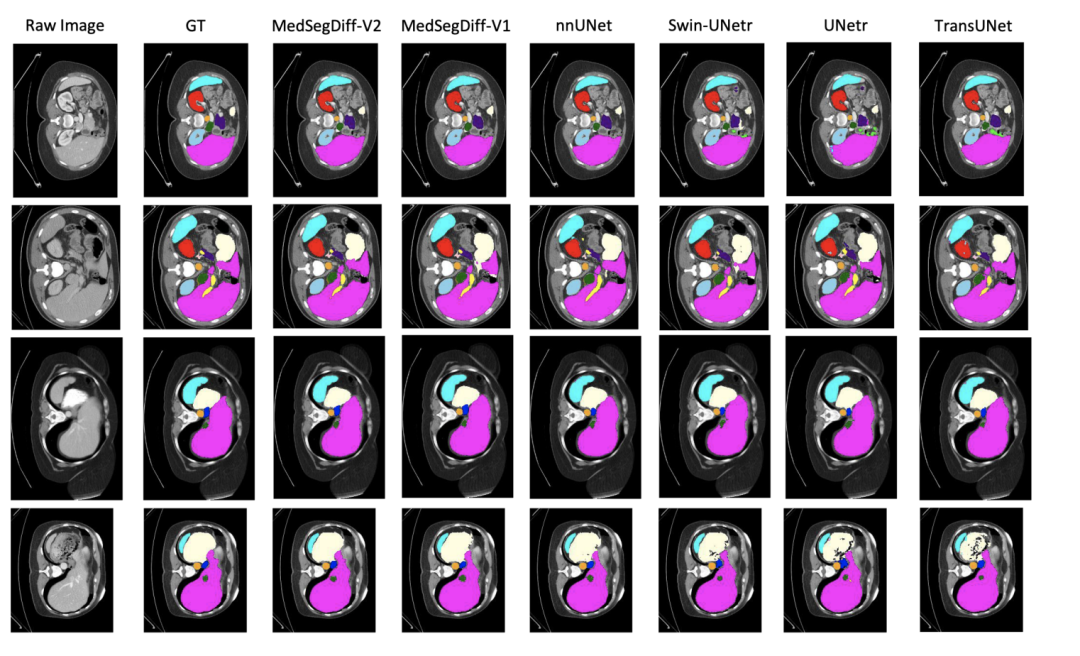
Medsegiff-v2 是可以进行多分类任务的,只是目前 Github 还没有维护多分类的代码,不过 Medsegiff-v2 的实现代码已经提交了。下图为在腹部 CT 图像中的多器官分割上的表现。
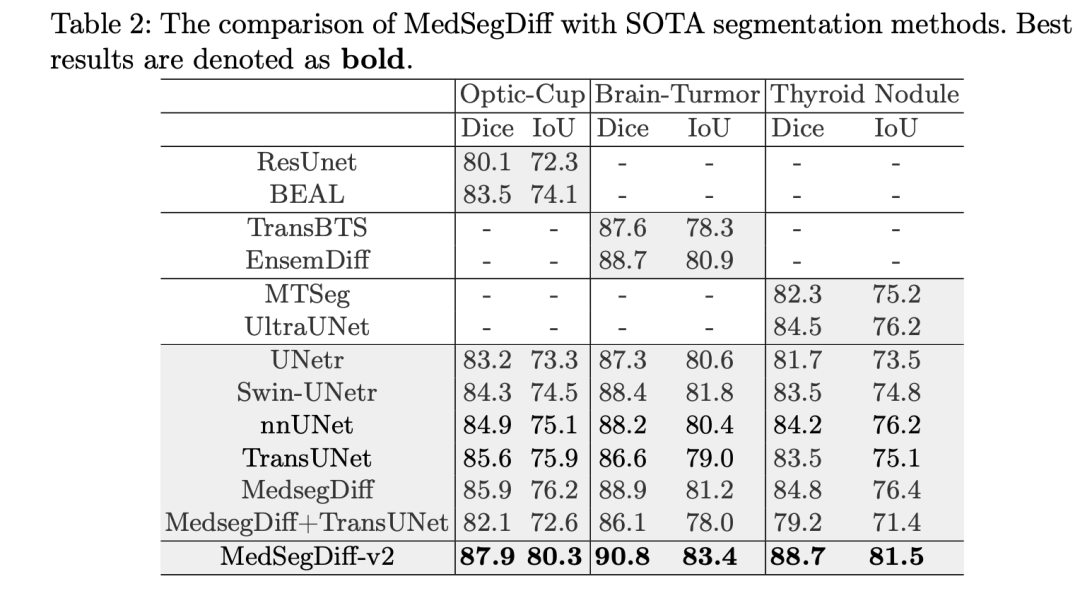
对比其他 SOTA 方法的结果如下表:
总结
关于 diffusion model 在医学图像分割上的应用,其是否能适应多分类且复杂的解刨结构还需要进一步探索,训练和推理时的效率也低于常规的有监督神经网络,可以进一步优化。
审核编辑:刘清
-
解码器
+关注
关注
9文章
1225浏览量
43753 -
MRI
+关注
关注
0文章
68浏览量
17342 -
DPM
+关注
关注
0文章
28浏览量
11535 -
高斯噪声
+关注
关注
0文章
11浏览量
8480
原文标题:MedSegDiff:基于 Diffusion Probabilistic Model 的医学图像分割
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于MLP的快速医学图像分割网络UNeXt相关资料分享
深度学习在医学图像分割与病变识别中的应用实战
基于多级混合模型的图像分割方法

基于深度特征聚合网络的医学图像分割方法
什么是图像分割?图像分割的体系结构和方法

DDFM:首个使用扩散模型进行多模态图像融合的方法




评论