 HLS for循环优化
HLS for循环优化
FOR循环优化
基本概念
从下面的例子中来解释for循环中的基本概念:
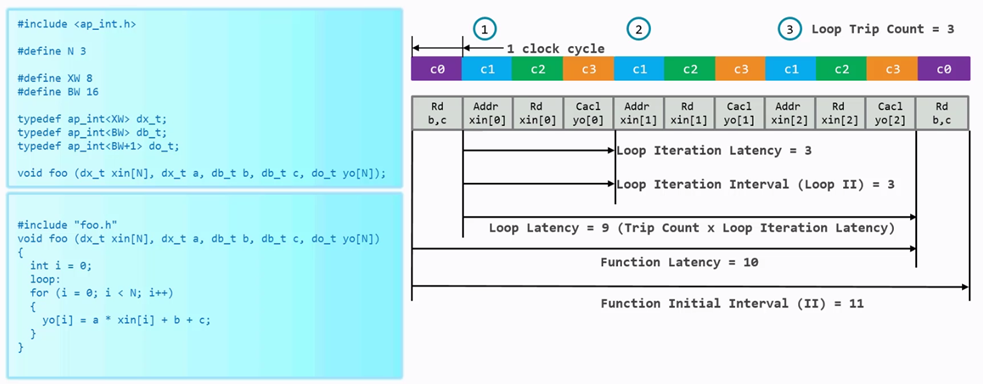
图 4.1 for循环基本概念
由于N等于3,因此每次循环可以分成4个步骤来完成:
c0:读取数据b和c;
c1:获取数据xin 0处地址;
c2:读取对应地址上的数据;
c3:计算yo[0]的值。
后面的计算都是三个时钟周期计算出一个值,因此对一次循环来说,Loop Iteration Latency为3,Loop Iteration Interval也是3,Loop Latency是9,再加上前面读b和c的值的一个周期,整个函数的Latency是10,函数间的Initial Interval是11.
Pipeline
对for循环常用的优化是pipeline,pipeline的原理如下图4.2所示。
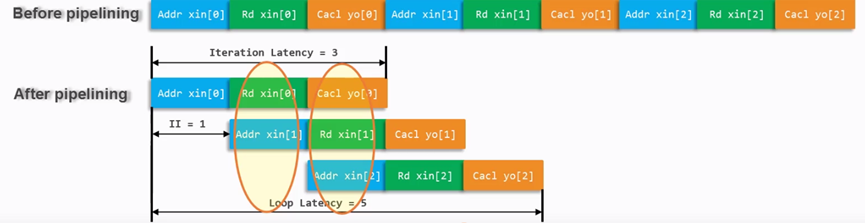
图 4.2 pipeline优化原理
在优化结束后,Loop Iteration Latency为3,Loop Iteration Interval变成1,Loop Latency为5.
如果对函数做pipeline,那么会自动把函数下面的for循环都做unrolling处理;如果对外层的for循环做pipeline,那么会自动对内层的for循环做unrolling处理。
Unrolling
默认情况下for循环是折叠的,就是电路被时分复用。当展开后,资源增加。如下图所示将for循环展开成3倍的情况,资源也扩大了3倍。

图 4.3 展开成3倍
也可以部分展开,循环次数为6,但展开成3倍,程序如下所示:
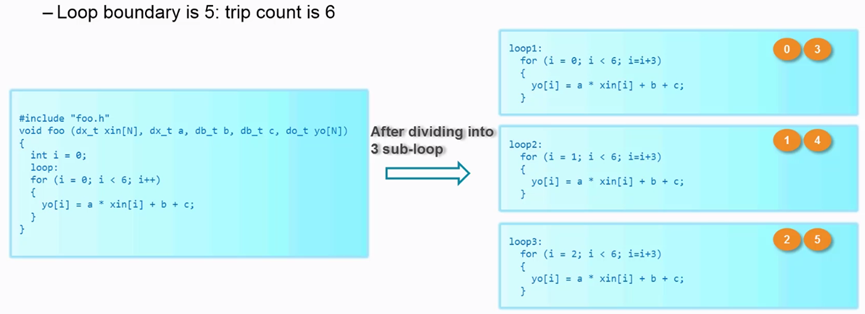
展开后,程序被分成3部分,资源也复制了3份。
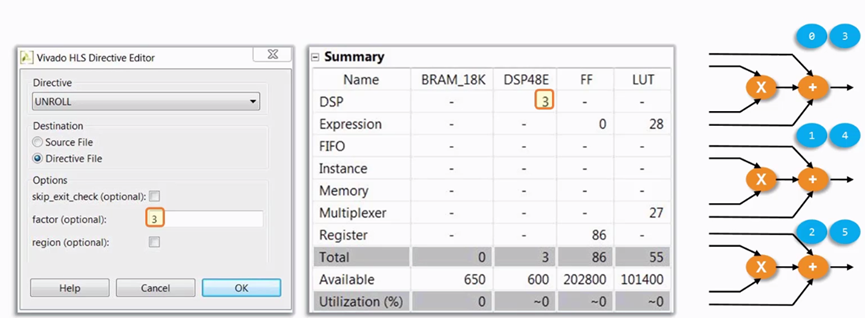
图 4.4 Unroll的设置
Merge
当几个for循环执行的内容很相似时,如下面的程序所示:

两个for循环分别对两个数据做加法和减法,在HLS综合后,会先进行第一个for循环的计算,完成后再进行第二个for循环的计算。这样综合出的Latency为18,Interval为19。
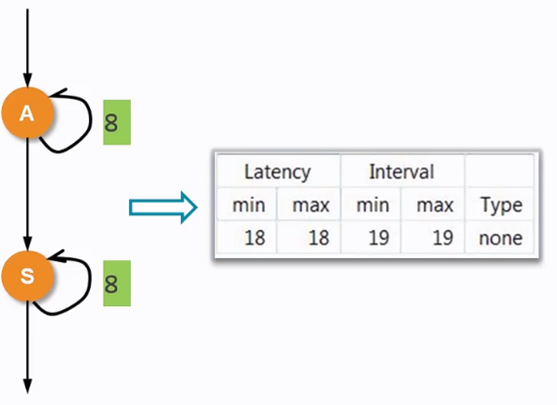
图 4.5 综合后延迟
在HLS中提供了Merge的选项,合并的是for所作用的region,合并后综合后的延迟如下图4.6所示。
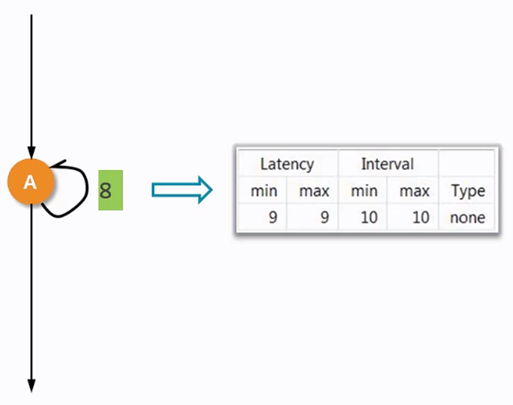
图 4.6 Merge后的延迟
上面的例子中两个循环的边界相同,如果两个循环的边界不同,则以最大的作为合并后的边界;如果一个边界是变量,另一个是常量,则不能合并;如果两个循环边界都是变量,依然不能合并。
还可以将for循环封装成一个函数,并在上一层中例化两次,并对函数采用Allocation来使函数并行执行,在allocation中有limit选项,可以指定实例化的次数,该数据与程序中实际的数值应该是一样的。
数据流
在下面的例子中,Task B依赖于Task A,Task C依赖于Task B,如图4.7所示。

而且可以分析出,该结构不适合之前所讲的pipeline和merge方式进行处理,在可以使用dataflow的方式。
从图中可以看出,在使用DataFlow后,Loop B无需等待A执行完成后才开始执行,而且各个Loop之间也村在间隔。且延迟和资源都明显减少。
DataFlow使用的限制:
1.一个输出在多个Loop模块中使用
2.被Bypass的模块
3.带反馈的模块
4.带条件的模块
5.可变循环边界的模块
6.多个退出条件的模块
下面分别对上面的限制条件进行说明。
1.din在Loop1中输出的temp1同时赋给Loop2和Loop3使用,这时是不能使用dataflow的,如图4.10所示。
通过对代码进行适当的修改,将其结构进行变形,增加一个Loop_copy模块,将其输出一个送个Loop2,另一个输出送给Loop3,但其实这两个输出的结果是相同的。就可以使用DataFlow来完成该函数。
且使用了DateFlow后,工程所占用的资源和延迟都相应减少。
- 被Bypass的模块
如下图4.12所示的例子中,temp1在Loop2中使用,但temp2没有经过Loop2,直接在Loop3中使用,这种情况下也是不能使用DataFlow的。
同样的,可以对代码进行优化以达到可以使用DataFlow的目的,如下图4.13所示。在Loop2中,增加一个输出端口,使其输出给Loop3,这样就可以使用DataFlow了。
在DataFlow的循环之间的存储模块,对于scalar、pointer和reference或者函数的返回值,HLS会综合为FIFO;对于数组,结果可能是乒乓RAM或者FIFO:如果HLS可以判断数据是流模式,就会综合为FIFO,且深度为1,若不能判断,就会综合为乒乓RAM。我们也可以指定为FIFO或者乒乓RAM,但在指定为FIFO时,如果指定的深度不合适,综合时就会出现错误。
嵌套for循环
三种嵌套循环:
对于Perfect Loop,对外边的Loop做流水比对内循环做流水更加节省时间。
对于Imperfect Loop,我们总希望可以转换为Perfect Loop或者Semi-Perfect Loop。如下的Imperfect Loop,如果对内层Product做流水,综合结果如右侧的图所示。
如果对第二层即col的Loop做流水,则会提示信息,col下的循环会被展开。
从图中的warning可以看出,a被综合为一个双端口的RAM,但第14行和第20行对a的操作有一个重叠的区域,意味着吞吐率受限。
如果对最外部的循环做流水,会把下面所有的循环都展开,延迟会减少,但资源会增加。
如果对整个函数做流水,那么函数下面的所有循环都会展开,能获得最好的Latency,但资源也是最多的。
我们可以对代码就行优化,具体代码具体优化。
Rewind
我们在使用了pipeline后,循环之间仍然会有间隔,但使用rewind功能,可以消除该间隔,如下图所示。
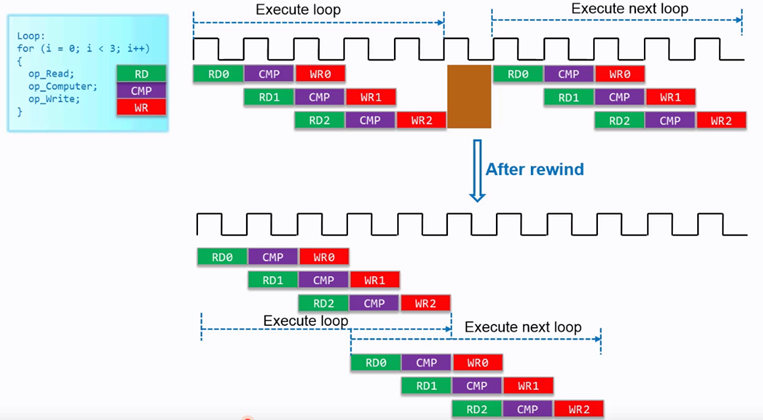
图 4.16 rewind功能
但当函数中有多个循环时,rewind不能使用。
自动添加流水
在config_compile中,可以设置自动添加流水操作,如果循环次数小于我们设定的pipeline loops时,HLS就会自动为for循环添加流水。
在使用config_compile后,如果不想对某些for循环做流水,就可以在pipeline下面的选项中选中disable Loop pipeline。
变量边界的解决方法
当循环边界为变量时,通常可以采用下面的方式进行处理。
- 使用tripcount directive;
- 对于边界变量的定义使用ap_int;
- 在C代码中使用assert宏。
Tripcount directive不会对综合有任何的影响,它只会对报告的显示有影响。
使用ap_int和assert方法后,综合后的资源会有明显的减少。采用assert的方式的资源和延迟是最少的。
inline是针对函数,flatten是针对嵌套的循环。
-
函数
+关注
关注
3文章
4333浏览量
62708 -
HLS
+关注
关注
1文章
129浏览量
24136 -
for循环
+关注
关注
0文章
61浏览量
2509
发布评论请先 登录
相关推荐
探索Vivado HLS设计流,Vivado HLS高层次综合设计
HLS优化设计中pipeline以及unroll指令:细粒度并行优化的完美循环
如何优化HLS仿真脚本运行时间
AMD-Xilinx的Vitis-HLS编译指示小结
优化 FPGA HLS 设计
用vivado HLS优化设计大规模矩阵相乘,求详细具体的优化策略
怎么利用Synphony HLS为ASIC和FPGA架构生成最优化RTL代码?
【正点原子FPGA连载】第一章HLS简介-领航者ZYNQ之HLS 开发指南
Vivado HLS设计流的相关资料分享
FPGA高层次综合HLS之Vitis HLS知识库简析
使用Vitis HLS创建属于自己的IP相关资料分享
HLS:lab3 采用了优化设计解决方案





 工商网监
工商网监
评论