 TinyML,无需重新合成或重新启动FPGA即可更新
TinyML,无需重新合成或重新启动FPGA即可更新
预计到本十年末,FPGA 芯片将主导物联网端点深度神经网络 (DNN)。它们比微控制器更节能、更快,并且比ASIC更容易开发。Infxl与Microchip合作,通过提供两项技术优势来加快其采用速度:
1. 从训练数据到紧凑的 DNN 的简单工具 C 语言和 HLS
2. TinyML FPGA实现,无需重新合成或重启即可更新
其中第一个解决了嵌入式开发人员社区共同关注的问题:ML 和 FPGA 工具需要一定程度的专业知识,而这种专业知识既昂贵又难以找到。
第二个解决了机器学习 (ML) 固有的问题:ML 解决方案在一段时间后会过时,需要定期恢复活力。我们提出了一种 DNN-ON-FPGA 设计,可确保 DNN 无需重新合成、重新实现或重新启动 FPGA 即可更新。
通过使用简单紧凑的ML模型,可以进一步放大FPGA实现的能效和速度优势。Infxl 网络就是这样一种模型(示例代码 [2])。它使用 8/16 位数据路径在简单 C 中实现完全连接的 DNN,而无需使用乘法或任何浮点运算。
Infxl 网络的一个关键特征是它在网络结构/参数和推理引擎之间保持清晰的分离。我们通过在LSRAM中保留参数来利用此功能,同时使用LUT和FF实现引擎。这样,当我们需要更新已部署的 Infxl 网络时,我们不需要重新合成、重新实现甚至重新启动 FPGA。我们只需更新LSRAM中的参数,FPGA几乎立即开始根据更新的网络结构/参数提供改进的结果。
开发过程包括两个主要步骤:
• 将预处理的数据上传到 cloud.infxl.com,并将经过训练的 Infxl 网络下载为即用型 C 代码。此过程不需要任何 ML 背景。
• 使用Microchip易于使用的SmartHLS编译器[3],根据项目的确切要求从C代码生成HLS。SmartHLS是一个基于Eclipse的IDE,它将C / C++代码作为输入,并生成SmartDesign IP组件(Verilog HDL)作为输出。我们可以在Libero SoC设计套件[4]中提供的SmartDesign画布中实例化生成的SmartDesign IP组件,以构建FPGA系统。
Infxl net C 代码包括一个测试平台和一个通用接口。在将其部署到FPGA中之前,需要进行一些简单的修改:
• 定义首选互连,例如,用于传入传感器数据的寄存器或 AXI4 接口。
• 定义用于通信 Infxl 网络预测的类的机制。
• 将 Infxl 网络的存储器类型更改为仅仿真,并定义 C 代码外部但仍在 FPGA 内部的存储器。
• 在 C 代码中创建一个顶级函数以合并 Infxl 网络。这将是之后实例化到整个FPGA系统中的IP。
默认的 Infxl net C 代码通过少量 RAM 将推理引擎连接到输入和输出。这是微控制器的典型方法。对于FPGA实现,与类似FIFO的接口进行交互会更有效。在默认的 Infxl net C 代码中添加了额外的小函数以适应这一点。然而,Infxl网络的推理引擎的代码保持不变。
有关原始 C 代码和修改后的 C 代码的比较,请参见下文。
源语言:
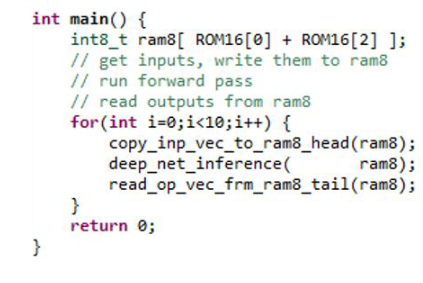
改 性:
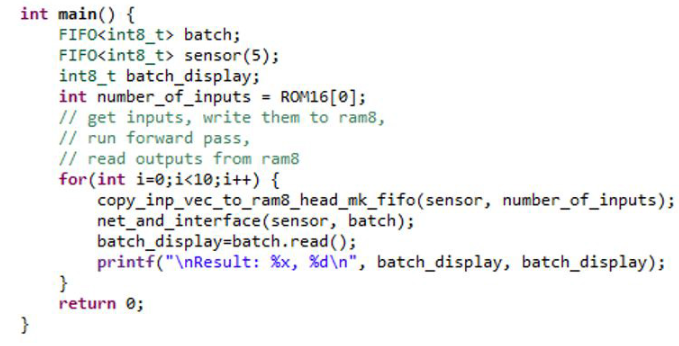
修改或删除了 Infxl 网络的默认测试平台功能(copy_inp_vec_to_ram8_head 和 read_op_vec_frm_ram8_tail),并引入了新的函数net_and_interface。net_and_interface是将使用 SmartHLS 合成的顶级函数。该函数copy_inp_vec_to_ram8_head仍然从测试平台获取数据,但是,它使用 FIFO 数据类型将数据输出到顶级函数中。来自FPGA-IP的数据使用batch.read()命令读取。然后,变量批次为预测类设置位。
下一步,函数内部RAM被提取出来,并将在SmartHLS的代码生成过程中转换为简单的内存接口。这需要对 ROM16 阵列进行简单的修改。ROM16封装了Infxl网络的结构以及所有参数。对于状态监测用例,原始ROM16修改如下:
源语言:

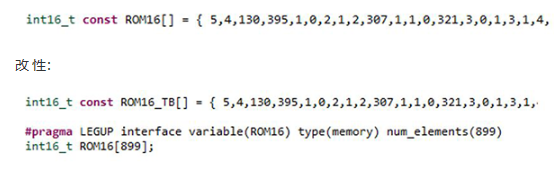
在测试平台中,ROM16 将在运行 Infxl 网络之前填充。在整个FPGA设计中也需要等效负载。此加载机制还支持更新已部署的 Infxl 网络:
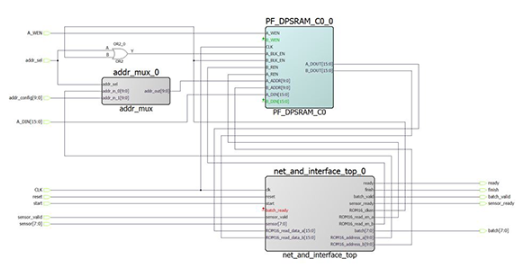
多路复用器 (MUX) 被放入 LSRAM 的一个端口的地址路径中。与这些用户可访问的地址和写入端口一起,LSRAM可以根据需要填充和更新。上图显示了 IP 核,其中 Infxl 网络配置了 FIFO 接口,用于传感器数据和可识别的类类型。但是,根据合成设置,可以更改此设置。
现在让我们看一下硬件。IP 核的确切大小取决于所选接口和任何所需的附加组件。AXI4接口由于其额外的接口功能,将比类似FIFO的接口或连接到AHB总线的寄存器接口需要更多的资源。上面显示的配置大约需要以下资源:
• 763 个 LUT 和 776 FF 用于 IP,包括接口
• 546 个 LUT 和 610 FF,仅用于 Infxl 网络
在此配置中,对单个输入向量的推理大约需要 2800 个时钟周期。以 100 MHz 或 200 MHz 运行,这将分别导致每 28 μs 或 14 μs 进行一次新分类。
当以上面显示的方式实现时,我们可以通过将现有的ROM16替换为更新版本来更新Infxl net的结构和参数。交换 Infxl 网络的内容定义需要 ROM16 中每个项目一个时钟周期。在我们的用例中,ROM16 阵列的长度为 899。这相当于899个时钟周期,其中无法进行识别。但是,可以在新旧ROM16之间进行更快的切换,但需要牺牲一些额外的LSRAM。如果需要连续操作,可以使用两个并联LSRAM。在两者中,只有一个在任何给定时间处于活动状态,另一个处于待机状态。要更新 Infxl 网络,备用 LSRAM 将使用新的 ROM16 进行更新。之后,LSRAM输出数据路径中的多路复用器被切换,从而激活新加载的ROM16并停用前一个ROM《》。这种切换可以在一个时钟周期内完成,从而在没有任何实际延迟的情况下进行更新。
如果对分类率有更高的性能要求,Infxl 网络也可以合成为并行结构,直至完全并行。这将大大加快分类速度。此优化是实现大小和性能之间的权衡。此外,完全并行的实现将Infxl网络的结构和参数整合到IP核本身中。这将删除在不重新合成和重新启动的情况下进行简单更新的功能。我们一直在讨论的用例的完全并行实现大约需要 10900 个 LUT 和 4800 个 FF,但将分类速度加快到大约 600 个时钟周期(包括所有握手)。
从本质上讲,Infxl net与Microsemi的SmartHLS相结合,提供了一种简单且面向未来的方法,可以将ML整合到各种系统中。本文中讨论的用例基于运动传感器的数据。但是,使用 Infxl 网络的应用程序不仅限于该用例。它可用于从预测性维护到环境监测、机器人技术、恶意软件检测、医疗保健可穿戴设备等用例。
审核编辑:郭婷
-
FPGA
+关注
关注
1631文章
21806浏览量
606692 -
机器人
+关注
关注
211文章
28745浏览量
208911 -
机器学习
+关注
关注
66文章
8453浏览量
133166
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论