 一张照片生成3D头像!苹果新模型击败StyleGAN2
一张照片生成3D头像!苹果新模型击败StyleGAN2
随便一张照片,就可生成3D头像。而且光线真实,任意角度可调。

正如其名,FaceLit的特色就是可以将人脸“点亮”。
“自带光环”的FaceLit在易用性上也不输同类,甚至更胜一筹——
进行3D建模时,需要的照片素材无需专门选择角度,数量上也只需一张。
甚至对表情、发型、眼镜等元素进行调节时,也不需要额外素材。
而传统的头像合成工具或者需要多张图片才能工作,或者对照片角度有刁钻的要求。
正是凭借这一创新,FaceLit获得了3.5的FID评分,较同类产品直接高出了25%。
改进式EG3D合成人像,光线信息单独处理
下面就来看一下FaceLit具体是如何实现头像合成的。
总的来说,苹果采用了将人物本体与光线分别处理再进行叠加的策略。
早期的三维人像合成工具在转换过程中可能产生形变。
而爆火的NeRF通过将场景拆分成具体因素,提高了3D图像合成效果,改善了这一问题。
但苹果团队认为,在可控性方面,NeRF仍存有不足之处。
于是,在EG3D框架的基础上,苹果创造了FaceLit的合成模型。
EG3D通过三平面解码器,赋予了二维卷积神经网络生成渲染3D模型所需深度参数的能力。
苹果团队对标准的EG3D训练方式进行了扩展,并将之转化成了FaceLit框架。
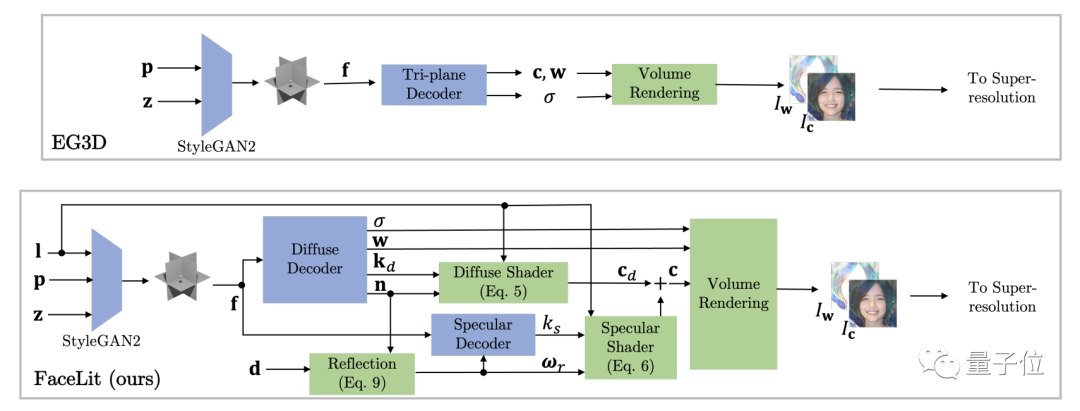
△FaceLit与传统EG3D渲染流程对比图
标准的ED3G使用相机位置p参数作为基本输入参数。
在建立GAN2操作时,苹果在EG3D的基础上加入了光照参数l。
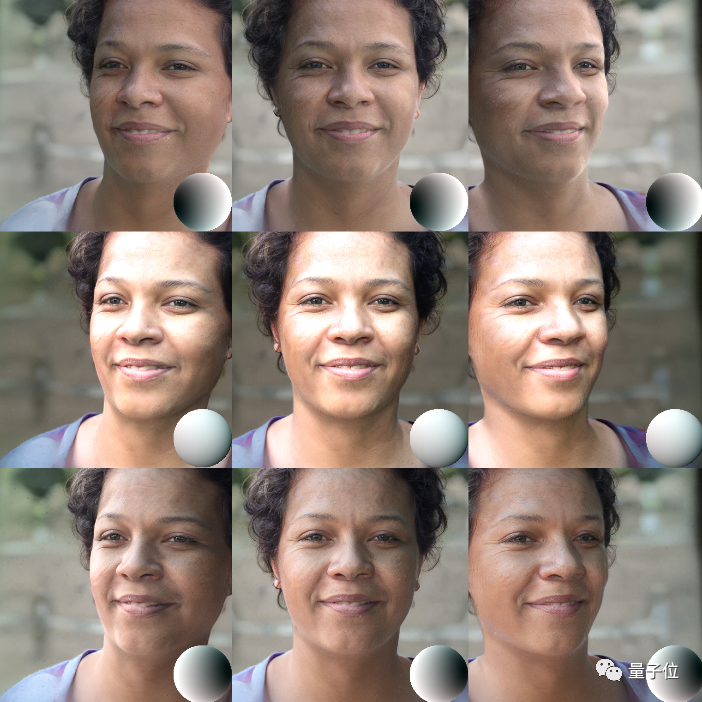
△不同p(左→右)与l(上→下)值下的初始图像
苹果选择了经过球形谐波方式简化后的Phong反射模型作为处理光源的物理基础。
光照参数l就是在这一基础之上独立处理得到的。
在自然界中,反射包括镜面反射和漫反射两种形式。

△不同镜面反射率条件下的效果对比
因此,苹果在ED3G模型中加入了镜面反射解码器和漫反射解码器。
它们替代了可以直接得到颜色c、密度σ数据的三平面解码器。
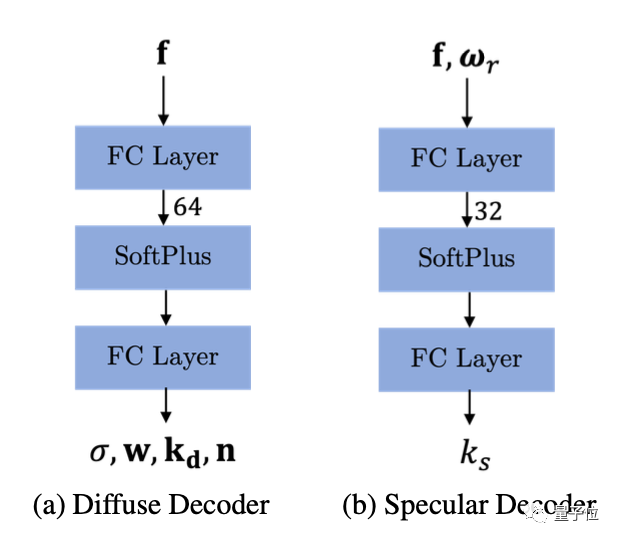
△反射解码器流程示意图
通过对GAN2产生的数据进行再次解码,可以得到镜面反射率ks和漫反射率kd。
然后再通过两种反射着色器得到颜色c,密度σ则由漫反射解码器计算得出。
最终,FaceLit以与三平面解码器相同的参数(c,w,σ)渲染图像,并进行分辨率优化。
有的放矢设计训练策略,数据无需人工标注
生成框架已有,那就来到训练阶段,其特点在于训练过程中无需人工标注。
方法论层面,在训练时,团队使用了FFHQ、MetFaces和CelebA-HQ数据集。
对于不同的数据集,苹果使用了不同的训练方式。
FFHQ包含了7万余条人脸数据,其训练分为两个阶段:先在较低的分辨率下训练,再提高分辨率再次进行。
对于包含2万数据量的CelebA-HQ,训练不需要分阶段进行。
而对于更小的MetFAces,则只需要通过ADA扩容的方式,使用预训练的FFHQ进行优化调整即可。
定性地看,训练结果在机位、光源和反射高光等方面都有出色的表现,图中的细节也有所增强。

△FaceLit生成的头像(左侧四列)唇齿部位的细节进行了明显重构
定量结果同样表明,FaceLit在FID、KID等指标上均优于包括标准EG3D在内的传统生成方式。
在使用FFHQ作为训练集的条件下,各生成方式的表现如下表,不难看出FaceLit拥有最低的FID和KID值。
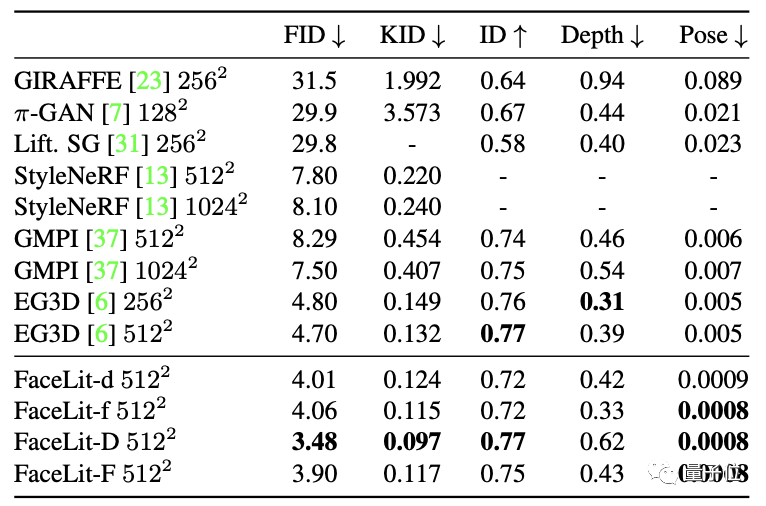
而相比于英伟达的StyleGAN2,FaceLit的表现依旧出色:
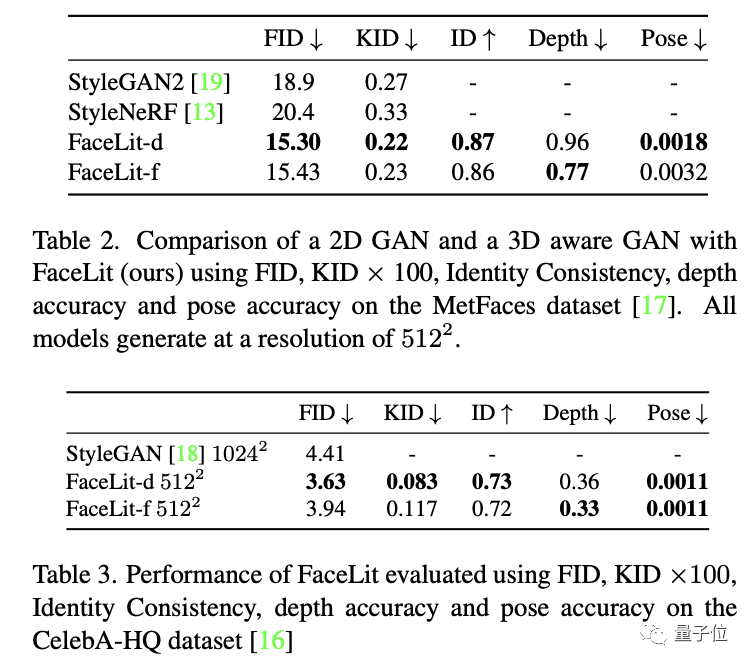
光线准确度方面,FaceLit在使用三种不同训练数据集的情况下,与人工设定的标准值平均均方误差均低于0.01。
网友:人们低估了苹果AI
消息发出后,便有网友认为“这是对更重磅产品的预热”。
更有网友直接推测,FaceLit的出现标示着人工智能将进军AR和VR领域,苹果的混合现实将最终实现商用……
也有网友认为,FaceLit不会商用,否则苹果才不会以论文的形式发表。

针对FaceLit本身,也有网友表示,除了LLM,其他都是浮云,他们(苹果)如果不开发LLM,就没有未来。
但这位网友同时也说,苹果可能已经在做(LLM)了。
相应的,也有网友称人们“低估了苹果在AI领域的深度”。
所以各位网友对苹果在AI领域还有什么样的期待呢?
审核编辑 :李倩
-
解码器
+关注
关注
9文章
1156浏览量
41136 -
模型
+关注
关注
1文章
3406浏览量
49457 -
3D图像
+关注
关注
0文章
38浏览量
10785
原文标题:一张照片生成3D头像!苹果新模型击败StyleGAN2,表情光线都能调,网友:要用于MR?
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
中国传动网:全球首张3D打印唱片发布 歌声也可3D打印
浩辰3D软件入门教程:如何比较3D模型
【PHYTEC开发板试用体验】3 通过开发板拍一张照片
视觉处理,2d照片转3d模型
一张照片就可识别用户身份准确率达99.5%
一张照片进行AI“换脸”之后,可以突破刷脸支付的安全系统吗?
一张照片揭示了即将推出的Realme X9的纤薄外形

3D人体生成模型HumanGaussian实现原理






 工商网监
工商网监
评论