 RA6T2 IIR滤波器加速器应用之配置IIRFA
RA6T2 IIR滤波器加速器应用之配置IIRFA
2. 配置IIRFA(下)
2.2 操作方法
2.2.2 处理方法
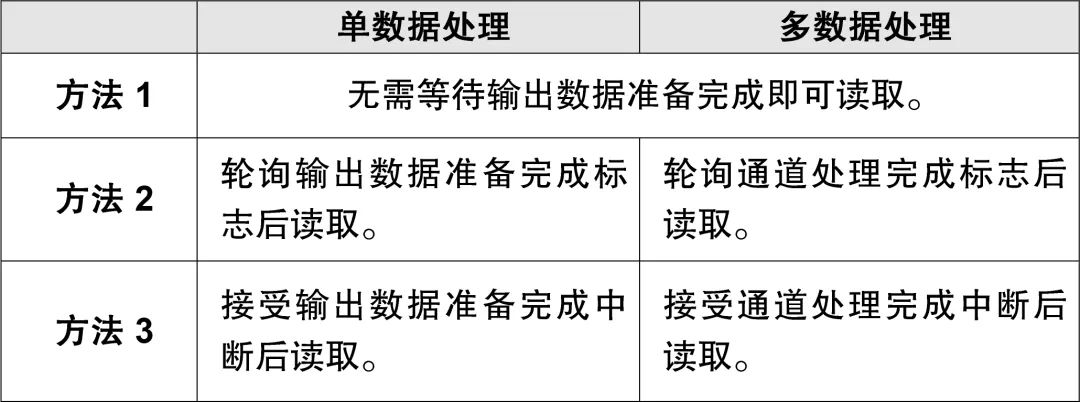
根据IIRFA的配置,有三种执行通道处理的方法。它们在通道处理开始后从IIRCHnOUT寄存器读取输出数据的操作过程不同。从定义上来讲,单数据处理是指对一个输入值执行通道处理,处理完成后不执行其他通道处理。多数据处理则是指对多个输入值连续执行通道处理。
表3列出了每种方法的操作过程:
表3. 数据处理方法
方法1
方法1是不等待输出数据准备完成即可读取输出数据的过程。轮询和中断均禁用。一旦输入值写入IIRCHnINP寄存器,内核执行就会停止,直到在IIRFA处理结束时数据被写入IIRCHnOUT寄存器。此方法在全部三种方法中速度最快,但它可能会在处理期间发生更高的全局中断延迟。如果您的样本处理是优先级最高的任务,则中断延迟可以忽略不计。
图4是采用方法1的通道处理操作过程流程图示例。
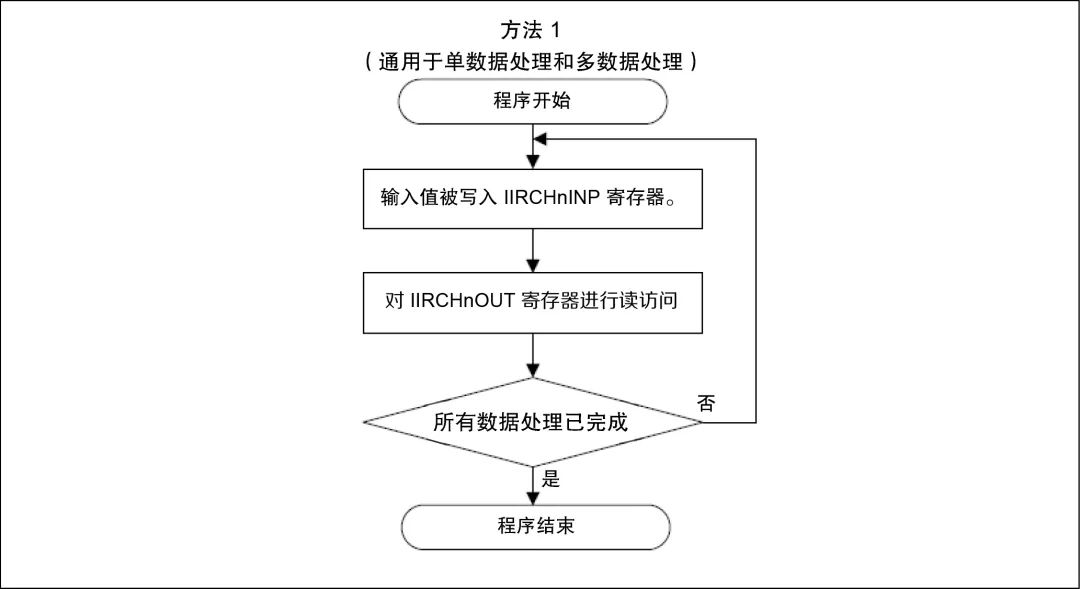
图4. 方法1操作过程流程图
重要说明:
• 不需要进行标志确定处理,因此存储器和时间开销在所有方法中最小。
• 当执行对IIRCHnOUT寄存器的读访问时,CPU将暂停,直到输出数据准备完成,这将使系统和PSBIU总线挂起。
• 注:在等待IIRCHnOUT时,内核不会处理任何中断。对于单样本处理,32级滤波器的最长等待时间可以达到约64个ICLK周期,对于多样本处理,可以达到224个ICLK周期(随着使用的级数而线性递减)。
方法2
方法2是设置数据准备完成标志后读取输出数据的过程。启用轮询并禁止IIR模块上的中断。一旦输入值写入IIRCHnINP寄存器,IIRFA驱动程序将轮询完成标志,这表明IIRCHnOUT寄存器中的数据可用。
下面给出了使用方法2进行通道处理的操作过程流程图示例:
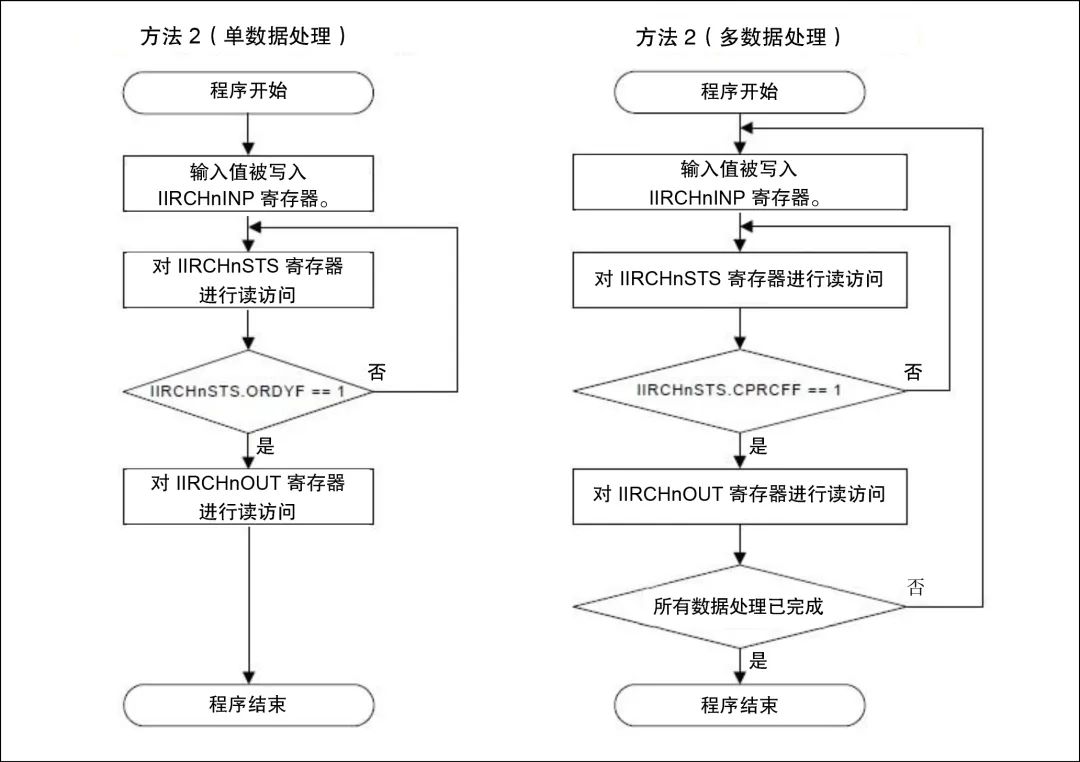
图5. 方法2操作过程流程图
重要说明:
• 需要进行标志确定处理,因此开销很大。
• 执行对IIRCHnOUT寄存器的读访问时,不会强制等待总线访问。其他系统中断可以在等待标志置1的同时进行处理。
方法3
方法3是在发生数据准备完成中断后读取输出数据的过程。禁用轮询并使能中断。一旦输入值写入IIRCHnINP寄存器,内核就可以处理其他指令,直到数据准备完成中断发出IIRCHnOUT寄存器中的数据可用的信号。
图6采用方法3的通道处理的操作过程流程图示例。
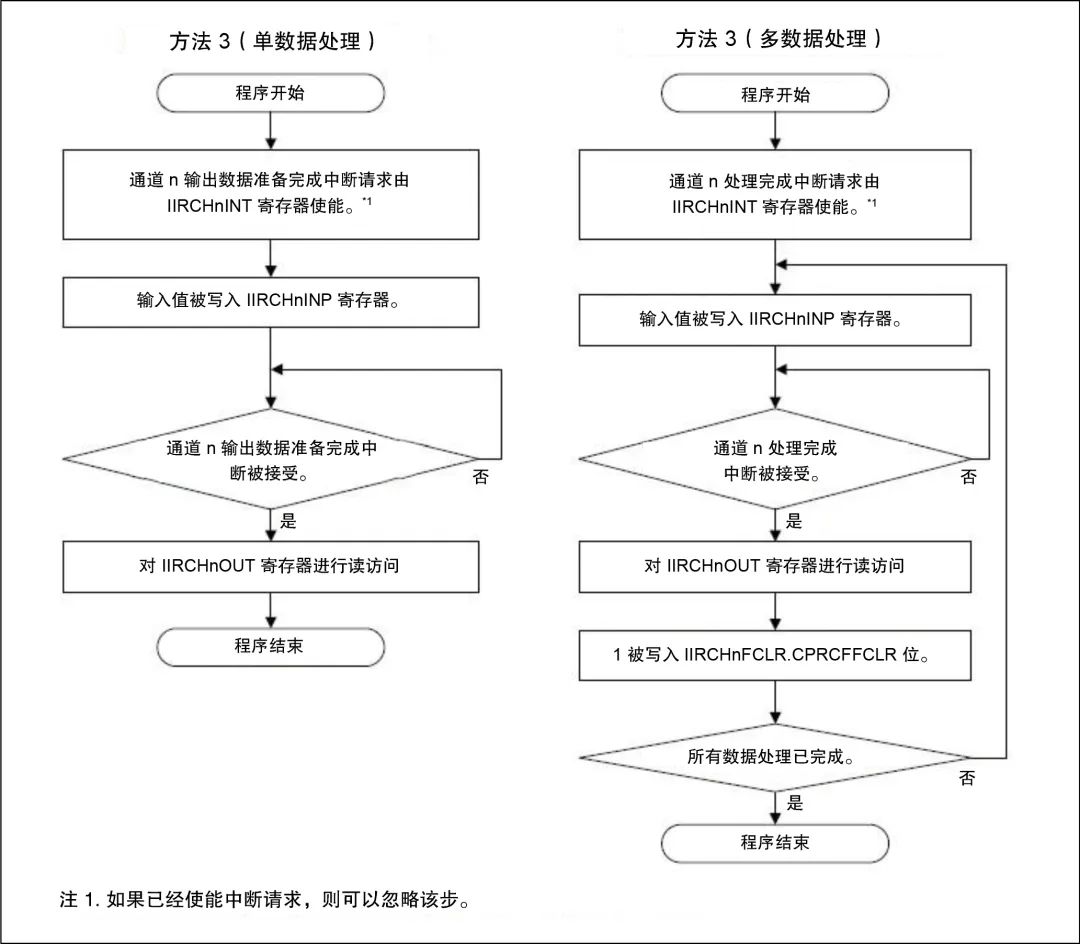
图6. 方法3操作过程流程图
重要说明:
• 由于在接受中断时处理,因此开销很大。
• 执行对IIRCHnOUT寄存器的读访问时,不会强制等待总线访问。
• 通道处理开始后,内核可以执行其他操作,直到发生输出数据准备完成中断或通道处理完成中断。
2.3 注意事项
2.3.1 最大程序提高性能
IIRFA的最佳配置取决于应用程序,因此根据您的系统需求考虑可用设置和操作方法的影响非常重要。
每个滤波器级需要花费2个ICLK周期来处理一个样本,另外需要5个周期来将状态值写回寄存器。因此,单样本操作每个级只需要2个周期,而多样本操作则需要7个周期。加载和存储每个样本需要额外的开销周期。
以下建议可能会提高性能:
• 使用函数R_IIRFA_Filter时,选择较大的数据块大小。对于实时滤波,建议使用R_IIRFA_SingleFilter内联函数执行单样本处理。
注:函数R_IIRFA_SingleFilter没有参数检查,只处理一个样本,并返回滤波后的样本。此函数支持轮询(如果已配置)。
• 如果您的滤波器仅使用1个双二阶级,请启用软件展开循环深度设置并提供大小为展开深度倍数的数据。
• 使用少量级时禁用轮询可显著提高性能;但是,它可能会在处理过程中产生更高的全局中断延迟。
• 在优化IIRFA处理时间时,应避免使用方法3,因为处理中断所需的时间远大于滤波数据所需的时间。对于大型数据集,使用中断几乎可以使总处理时间加倍。
2.3.2 限制
下面汇总列出了设计应用程序时要考虑的主要限制:
• 所有配置的通道共有32个级可用。
• 使用DTC或DMA时无法保证IIRFA正确操作,因此不受支持。
• 禁用轮询时,内核执行在等待数据可用时会停止。当内核执行暂停时,无法处理任何中断。
审核编辑:刘清
-
寄存器
+关注
关注
31文章
5334浏览量
120212 -
加速器
+关注
关注
2文章
796浏览量
37835 -
中断处理
+关注
关注
0文章
94浏览量
10967 -
IIR滤波器
+关注
关注
0文章
31浏览量
11505
原文标题:RA6T2 IIR滤波器加速器应用指南 [4] 配置IIRFA(下)
文章出处:【微信号:瑞萨MCU小百科,微信公众号:瑞萨MCU小百科】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
RA6T2的16位模数转换器操作 [11] 配置RA6T2 ADC模块 (8)
![<b class='flag-5'>RA6T2</b>的16位模数转换<b class='flag-5'>器</b>操作 [11] <b class='flag-5'>配置</b><b class='flag-5'>RA6T2</b> ADC模块 (8)](https://file1.elecfans.com/web2/M00/90/36/wKgaomTV4GWAZXBzAABvfHVzghw594.png)
请问21489的IIR加速器滤波参数设置应该如何对应起来?
21489的IIR加速器滤波参数设置如何对应加速器的滤波参数?
RA6T2 IIR滤波器的IIRFA模块配置方法

RA6T2 IIR滤波器加速器应用指南 [6] 滤波器设计方法(下)
![<b class='flag-5'>RA6T2</b> <b class='flag-5'>IIR</b><b class='flag-5'>滤波器</b><b class='flag-5'>加速器</b>应用指南 [<b class='flag-5'>6</b>] <b class='flag-5'>滤波器</b>设计方法(下)](https://file1.elecfans.com/web2/M00/88/C5/wKgaomRx0duANztRAAADbu4X9Ec328.gif)
瑞萨MCU RA6T2的16位模数转换器操作 [4] 配置RA6T2 ADC模块 (1)
![瑞萨MCU <b class='flag-5'>RA6T2</b>的16位模数转换<b class='flag-5'>器</b>操作 [4] <b class='flag-5'>配置</b><b class='flag-5'>RA6T2</b> ADC模块 (1)](https://file1.elecfans.com/web2/M00/8D/DA/wKgZomTA0P-ATvNiAAAhS9ol-Jc109.jpg)
RA6T2的16位模数转换器操作 [4] 配置RA6T2 ADC模块 (1)
![<b class='flag-5'>RA6T2</b>的16位模数转换<b class='flag-5'>器</b>操作 [4] <b class='flag-5'>配置</b><b class='flag-5'>RA6T2</b> ADC模块 (1)](https://file1.elecfans.com/web2/M00/BB/1B/wKgZomWXtb6ACk_NAAARMuEl9ZA261.png)
RA6T2的16位模数转换器操作 [5] 配置RA6T2 ADC模块 (2)
RA6T2的16位模数转换器操作 [6] 配置RA6T2 ADC模块 (3)
RA6T2的16位模数转换器操作 [7] 配置RA6T2 ADC模块 (4)
RA6T2的16位模数转换器操作 [8] 配置RA6T2 ADC模块 (5)
RA6T2的16位模数转换器操作 [9] 配置RA6T2 ADC模块 (6)
RA6T2的16位模数转换器操作 [10] 配置RA6T2 ADC模块 (7)
RA6T2的16位模数转换器操作 [11] 配置RA6T2 ADC模块 (8)





 工商网监
工商网监
评论