 离网络边缘更近一步
离网络边缘更近一步
机器学习介绍
机器学习是大多数AI应用的核心,负责教计算机学会识别数据中的模式。更具体地来说,其目标就是创建训练有素的模型。这可以通过监督学习来完成,这种学习方式向计算机提供学习实例。另外,这个过程也可以不受监督——计算机只是在数据中寻找其关心的模式。还有涉及连续学习或持续学习的技术,这些技术可以使计算机从错误中吸取教训,但这些不在本文讨论范围之内。
运行您的ML模型
一旦建成了ML模型,便可以将其应用于手头的工作。模型可用于预测未来事件、识别异常,以及进行图像或语音识别。几乎在所有情况下,模型都依赖于大型深层树状结构,并且需要大量的算力才能运行。对于通常基于人工神经网络进行图像和语音识别的模型而言尤其如此。神经网络创建稠密网格,因此需要在高度并行化的硬件(通常基于GPU)上运行。直到最近,也只有AWS或Azure等云服务提供商才有实力提供此类功能。
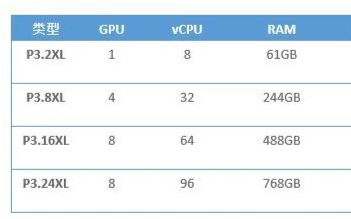
为了让您对所需的算力有个概念,下表列示了AWS P3实例的规格,这是一个针对ML应用进行了优化的处理平台
| 类型 | GPU | vCPU | RAM | GPU RAM | 存储BW | 网络BW |
| P3.2XL | 1 | 8 | 61GB | 16GB | 1.5Gbps | ~10Gbps |
| P3.8XL | 4 | 32 | 244GB | 64GB | 7Gbps | 10Gbps |
| P3.16XL | 8 | 64 | 488GB | 128GB | 14Gbps | 25Gbps |
| P3.24XL | 8 | 96 | 768GB | 256GB | 19Gbps | 100Gbps |
表1:AWS P3实例规格
这些都是顶配机型。它们具备大容量RAM,以及极快的网络和存储访问权限。最重要的是,它们具有强大的CPU和GPU处理能力,正是这一要求使ML模型在网络边缘运行成为了真正的挑战。
集中式AI的缺点
目前为止,由于ML模型难以在网络边缘运行,因此大多数最著名的AI应用都依赖于云。但是,这种对云计算的依赖给AI的使用带来了一些限制。下面列出了集中式AI在运行方面的一些缺陷。
有些应用无法在云端运行
为了在云端运行AI,需要有容量足够的可靠网络连接。如果没有这种条件,则可能由于缺乏基础设施,有些AI应用不得不在本地运行。换言之,只有能够在边缘运行ML模型,这些应用才能正常工作。
以自动驾驶汽车为例。它需要完成许多依赖于机器学习的任务。这些任务中最重要的是探测和规避物体。这要求ML模型要有相当大的算力。但是,即使是联网汽车也只有较低的连接带宽,这些连接还并不一致(尽管5G可能会改善这一点)。
在为采矿和其他重工业创建智能物联网监控系统时,同样存在这种限制。通常在本地会有快速网络,但是互联网连接可能会依赖于卫星上行链路。
延迟是关键
许多ML应用需要实时工作。上面提到的自动驾驶汽车就是此类应用,另外还有实时面部识别等应用。它可以用于门禁系统或安保措施;例如,警察经常使用这项技术监视体育赛事和其他活动中的人群,以找出已知的闹事者。
AI也越来越多地用于打造智能医疗设备。其中一些需要实时工作才能发挥真正的作用,但是连接到数据中心的平均往返时间约在10到100毫秒之间。因此,如果不将ML模型转移到网络边缘,就很难实现实时应用。
安全性可能会成为问题
许多ML应用会处理安全数据或敏感数据。显然,这类数据可以通过网络发送,并被安全存储到云端。但是,当地政策通常禁止这样做。健康数据尤其敏感,许多国家对发送到云服务器这一做法有着严格的法规要求。总之,确保仅连接到本地网络的设备的安全性永远更加容易。
成本
订购ML优化的云实例可能会非常昂贵 - 表1中所示的最低规格实例每小时花费约3美元。许多云提供商会收取额外的费用,例如用于存储和网络访问的费用,这笔费用也要考虑在内。实际上,运行一个AI应用每月可能要花费高达3,000美元。
结论
实现成功的机器学习通常需要具有强大算力的基于云或服务器的资源。但是,随着应用的发展和新用例的出现,将机器学习转移到网络边缘变得更加引人注目,尤其是在需要优先考虑延迟、安全性和实现成本等因素的情况下。
审核编辑:郭婷
-
服务器
+关注
关注
12文章
9129浏览量
85344 -
机器学习
+关注
关注
66文章
8408浏览量
132573 -
自动驾驶
+关注
关注
784文章
13787浏览量
166406
发布评论请先 登录
相关推荐
详解一步一步设计开关电源
构建一种低功耗小基站和适变型边缘计算MEC网络平台
一步一步基于ADS进行设计开发
欧洲发射四颗欧洲伽利略全球导航卫星 距全球定位系统更近一步
人类距离拓扑量子计算更近了一步
边缘计算技术怎么实现
华为推出新功能,鸿蒙系统将更进一步
台积电计划在美国亚利桑那州设立子公司,离建5nm厂更近一步
将机器学习转移到网络边缘变得引人注目

XVF3510 下一代语音处理器,离声控一切更近一步






 工商网监
工商网监
评论