 ChatGPT大型语言模型在信息提取方面的能力
ChatGPT大型语言模型在信息提取方面的能力
摘要
本文主要评估了ChatGPT这种大型语言模型在信息提取方面的能力,作者使用了7个细粒度的信息提取任务来评估ChatGPT的性能、可解释性、校准度和可信度。
作者发现,在标准信息提取设置下,ChatGPT的性能较差,但在开放式信息提取设置下表现出色,且其决策的解释具有高质量和可信度。
不过,ChatGPT存在过度自信的问题,导致其校准度较低。此外,ChatGPT在大多数情况下对原始文本的忠实度很高。
最后,作者手动注释并发布了7个细粒度信息提取任务的测试集,包含14个数据集,以进一步促进研究。
主要思路
ChatGPT是最近非常流行的对话大模型,可以与用户进行流畅和高效的交流。但是由于ChatGPT的训练细节和数据没有完全公开,并且ChatGPT的输出会带有一些观点和偏向,这些观点都可能会影响用户对事物的判断和决策,甚至对用户造成负面作用[1-4]。
因此,对于ChatGPT的评测方面,不止需要关注给定下游任务的性能评测,同时还需要考虑到使用大模型过程中用户可能需要的一些方面,如ChatGPT对决策判断的可解释、预测自信程度和对于输入原文的忠实程度等。
基于以上分析,本文希望在ChatGPT性能的基础上,通过更多的维度对ChatGPT模型的能力进行全方位的评估。
具体来说,我们希望通过以下4个方面来评估ChatGPT的综合性能:
1)性能(Performance)。我们研究的一个重要方面是全面评估ChatGPT在各种任务上的整体性能,如准确率和F1值等。并将其与其他热门模型进行比较。通过从不同角度考察其性能,我们旨在提供对ChatGPT在下游信息提取任务方面能力的详细理解。
2)可解释性(Explainability)。ChatGPT的可解释性对于其在现实场景中应用是至关重要的[5-7],因为用户希望在获取模型输出的同时,让模型给出合理的预测理由和判断依据。在我们的研究中,我们将同时衡量ChatGPT的自我检查和人工检查的可解释性,重点关注其为人类提供有用和准确的推理过程解释的能力。
3)校准性(Calibration)。测量“calibration”有助于评估模型的预测不确定性[8,9]。校准度高的分类器应该具有准确反映正确性概率的预测分数[10,11]。鉴于深度神经网络在其预测中表现出过度自信的倾向,我们期望识别ChatGPT的潜在不确定性或过度自信现象。
4)忠诚度(Faithfulness)。模型对预测解释的忠诚度对于用户而言非常重要[12,13]。我们尝试评估ChatGPT提供的解释是否与输入内容一致。
基于以上四个方面,我们设计了15个不同的评测指标,其中10个为ChatGPT自动输出的指标,5个为多位领域专家人工标注的指标。具体指标如下:
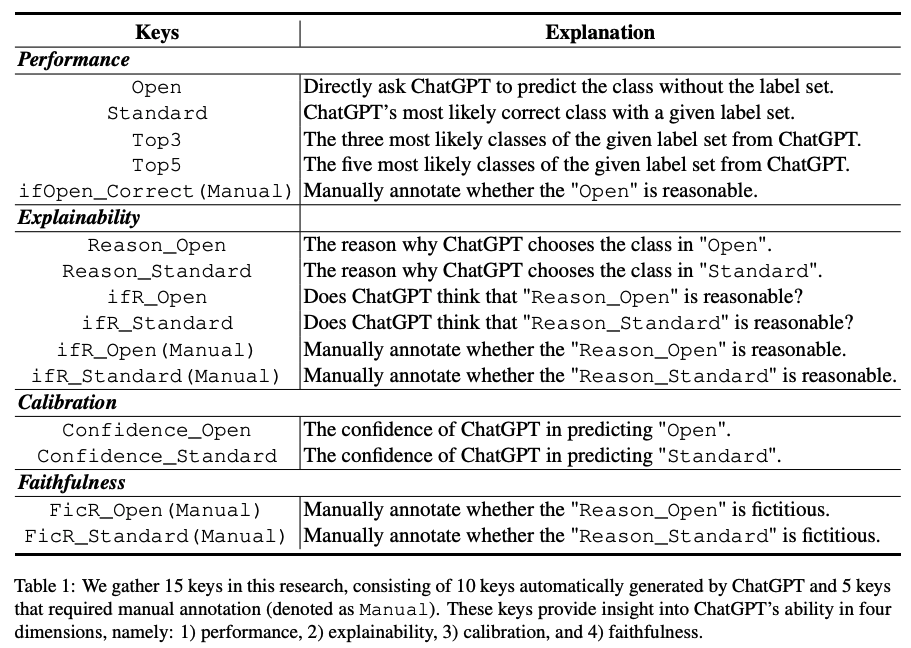
任务数据集及实验设置
我们选择了自然语言处理中十分重要的研究任务——信息抽取,作为任务载体,对ChatGPT的以上度量指标进行全方位的评估。信息抽取(information extraction, IE)涉及异构结构提取、事实知识使用和多样化的目标,因此此类任务是评估ChatGPT能力的理想场景。本文中,我们选择了7个信息抽取任务共14个数据集进行测试,包括是实体识别,关系抽取和事件抽取等。
在实验过程中,我们采用了2种设置,即标准信息抽取(Standard-IE)和开放式信息抽取(OpenIE)。Standard-IE设置通常用于以前的工作中,它使用特定于任务的数据集与监督式学习范式对模型进行微调。对于ChatGPT,由于我们无法直接微调参数,因此我们评估ChatGPT从一组候选标签中选择最合适答案的能力。具体而言,这种设置基于包括任务描述、输入文本、提示和标签集的指示。任务描述描述了具体的IE任务,提示包括引导ChatGPT输出所需特征(即上述15个特征中的一个或多个),而标签集基于每个数据集包含所有候选标签。OpenIE设置是比Standard-IE设置更高级和具有挑战性的情境。在此设置中,我们不会向ChatGPT提供任何候选标签,仅依赖其理解任务描述、提示和输入文本的能力来生成预测。我们的目标是评估ChatGPT生成合理事实知识的能力。实验结果对比的模型包括BERT、RoBERTa和每个任务的SOTA模型。
实验结果及结论
1)Standard-IE设置
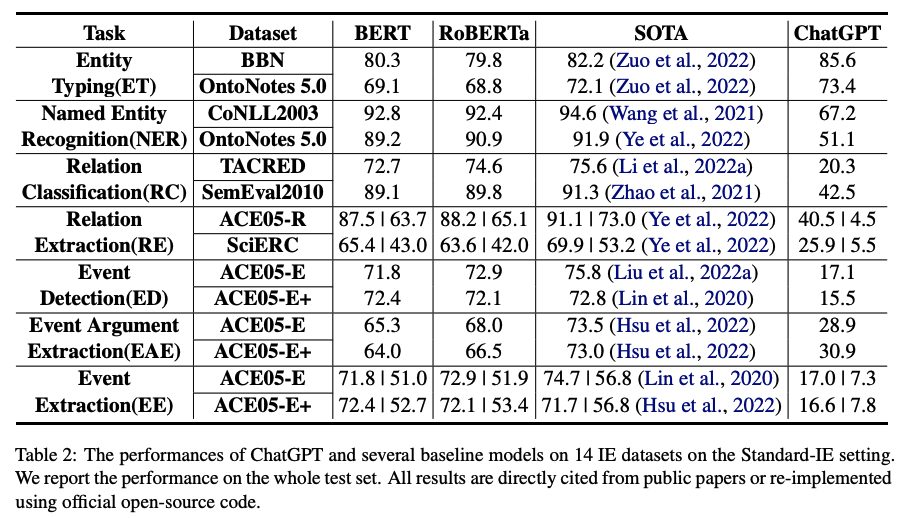
主要结论:
1)在大部分情况下,ChatGPT的性能与BERT类模型和SOTA模型的性能差距较大;
2)在简单任务,如entity typing和relation classification问题下,ChatGPT的性能较好。
2)Open-IE设置
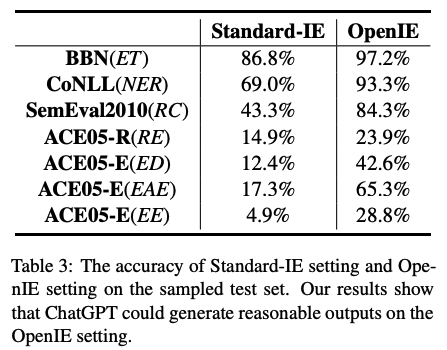
主要结论:
ChatGPT在开放式信息抽取设置下,输出的结果较为令人满意,在很多任务上能够在大多数情况下输出人类认可的结果。这说明ChatGPT已经学习了很多正确且可以合理输出的常识知识。
3)可解释性
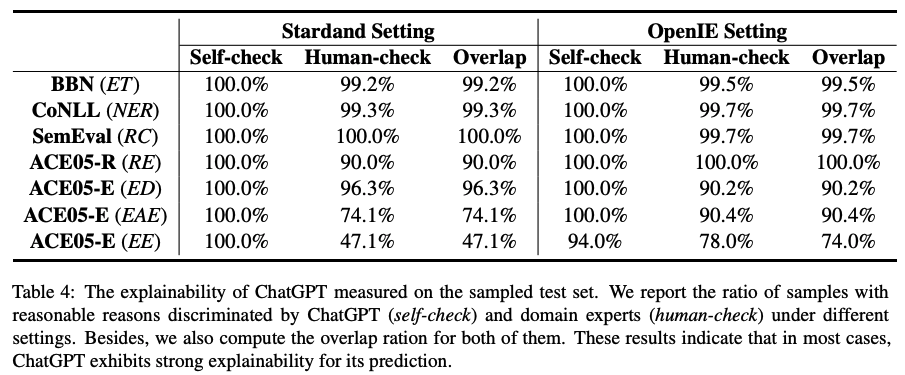
主要结论:
通过ChatGPT和人工对给出的判断理由进行标注,我们发现ChatGPT输出的解释非常可靠,绝大多数情况下,人类与ChatGPT都认为给出的理由是合理的。以上数据表明,ChatGPT对于自己预测的解释可信度较高。
4)校准度
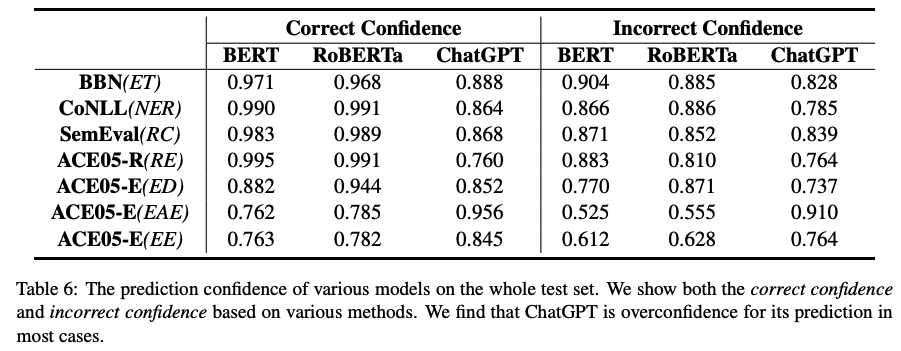
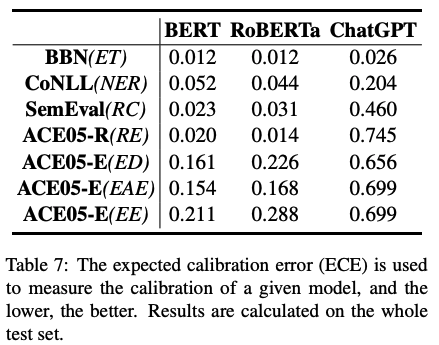
主要结论:
1)表6展示的是各个模型预测的置信度,可以看出,BERT类模型和ChatGPT对于自己的预测都十分自信,均给出了很高的置信度。相比而言,因为ChatGPT在Standard-IE中其性能不佳,所以给出这么高的置信度表明模型有很严重的过度自信倾向。同时,模型对于预测错误的样本,置信度明显较低。也就是说,当模型给出的预测置信度较低时,应该对预测结果进行校验。
2)表7通过评估校准度的指标ECE,我们可以明显看出ChatGPT有最低的校准度,即预测置信度偏高,过度自信问题严重。
5)忠实度
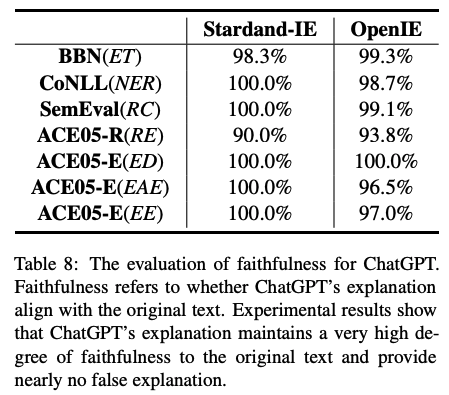
主要结论:
通过领域专家对模型输出解释和输入原文的对比,进行了人工的忠实度度量。我们发现,ChatGPT的解释是非常忠实于原文的,基本没有在给定上下文的情况下,通过编造理由进行预测的行为。
总结
本文聚焦于ChatGPT在各种信息抽取任务上的系统性评测。针对于7个细粒度信息抽取任务和14个数据集,从模型性能、可解释性、校准度和忠实度这四个角度,设计了15个指标(10个从ChatGPT自动获取的指标,5个领域专家标注的指标),对ChatGPT进行了全面评估。实验结果表明,ChatGPT在标准IE设置下,性能与有监督模型有很大差距。
但是,ChatGPT在OpenIE的场景下输出非常符合人类预期。同时,通过领域专家标注表明,ChatGPT可以对自己的预测结果给出可靠的解释,这表明ChatGPT有极强的解释能力。但是ChatGPT会对自己的预测过度自信,给出非常高的预测置信度,从而导致较低的校准度。
最后,本文还验证了ChatGPT的决策非常忠实于原文,即不会通过虚构来解决或者解释问题。本文说明,ChatGPT在信息抽取领域仍然有很多的改进角度和提升空间。
审核编辑 :李倩
-
模型
+关注
关注
1文章
3260浏览量
48911 -
数据集
+关注
关注
4文章
1208浏览量
24734 -
ChatGPT
+关注
关注
29文章
1564浏览量
7801
原文标题:通过准确性、可解释性、校准度和忠实度,对ChatGPT的能力进行全面评估
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【大语言模型:原理与工程实践】大语言模型的评测
【《时间序列与机器学习》阅读体验】+ 时间序列的信息提取
【「时间序列与机器学习」阅读体验】时间序列的信息提取
关于频率变化的正弦波幅值信息提取
NLPIR在文本信息提取方面的优势介绍
不到1分钟开发一个GPT应用!各路大神疯狂整活,网友:ChatGPT就是新iPhone
基于VB6.0的点阵字模信息提取方法
GPS定位信息提取及应用
基于FPGA的图像信息提取设计及仿真

ChatGPT在电磁领域的能力到底有多强?






 工商网监
工商网监
评论