 CVPR 2023:基于可恢复性度量的少样本剪枝方法
CVPR 2023:基于可恢复性度量的少样本剪枝方法
2. 引言
近年来,卷积神经网络(CNNs)取得了显著的成功,但较高的计算成本阻碍了其实际应用部署。为了实现神经网络加速,许多模型压缩方法被提出,如模型剪枝、知识蒸馏和模型量化。然而,大多数早期方法依赖于原始训练集(即所有训练数据)来恢复模型的准确性。然而,在数据隐私保护或实现快速部署等场景中,可能只有稀缺的训练数据可用于模型压缩。
例如,客户通常要求算法提供商加速其CNN模型,但由于隐私问题,无法提供全部训练数据。只能向算法提供商提供未压缩的原始模型和少量训练样本。在一些极端情况下,甚至不提供任何数据。算法工程师需要自行合成图像或收集一些域外的训练图像。因此,仅使用极少样本甚至零样本情况下的模型剪枝正成为亟待解决的关键问题。
在这种少样本压缩场景中,大多数先前的工作采用了滤波器级剪枝。然而,这种方法在实际计算设备(如GPU)上无法实现高加速比。在没有整个训练数据集的情况下,过往方法也很难恢复压缩模型的准确性。为解决上述问题,本文提出了三大改进:
关注延迟-准确性的权衡而非FLOPs-准确性
在少样本压缩场景中,块级(block-level)剪枝在本质上优于滤波器级(filter-level)。在相同的延迟下,块级剪枝可以保留更多原始模型的容量,其准确性更容易通过微小的训练集恢复。如图 1 所示,丢弃块在延迟-准确性权衡方面明显优于以前的压缩方案。
提出“可恢复性”度量指标,代替过往“低损害性”度量指标[1]。具体来讲,过往很多剪枝方法优先剪去对最终 loss 影响最小的模块,而本文优先剪去最易通过微调恢复性能的模块。
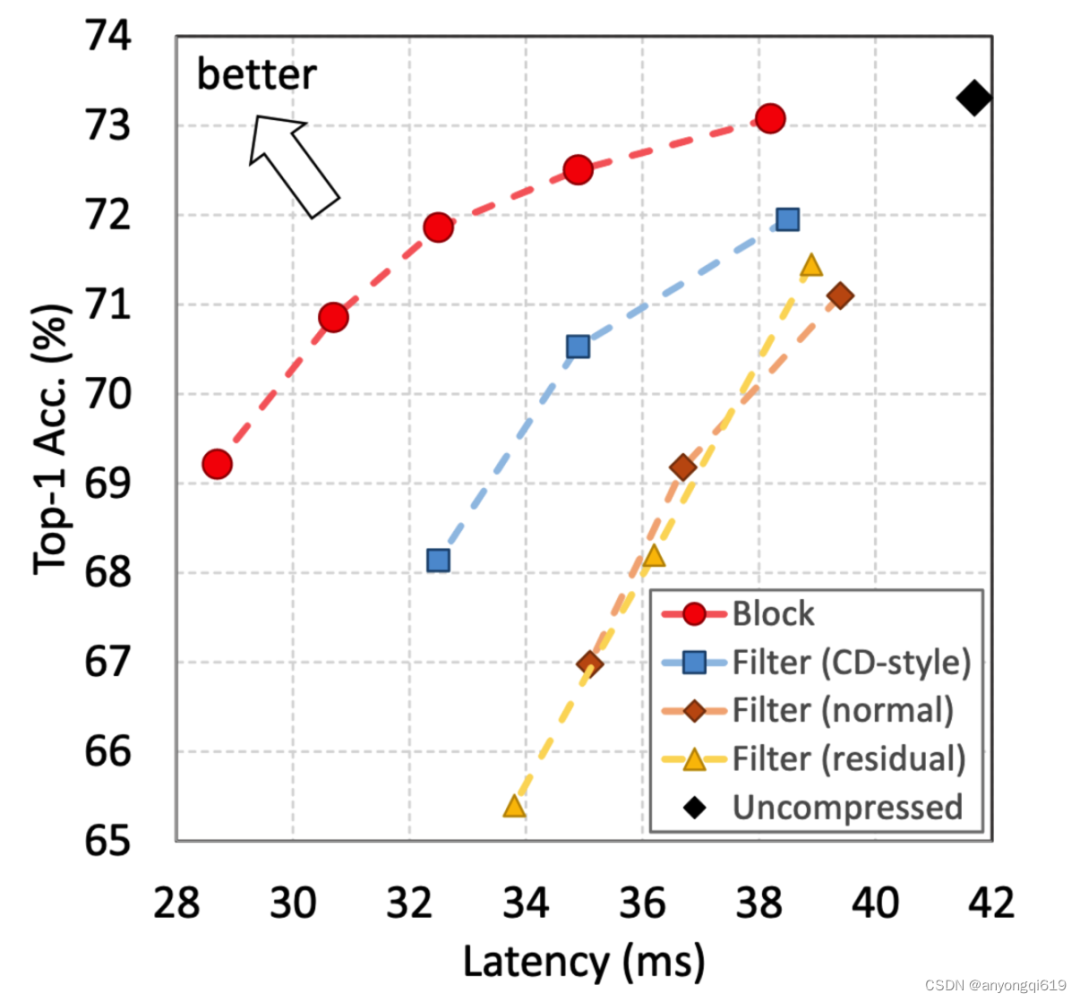
图 1. 仅使用 500 个训练图像的不同压缩方案比较,Block-level 优于 filter-level。
图 1. 仅使用 500 个训练图像的不同压缩方案比较,Block-level 优于 filter-level。
本文提出了PRACTISE(Practical networkacceleration withtinysets of images),以有效地使用少量数据加速网络。PRACTISE 明显优于先前的少样本剪枝方法。对于22.1%的延迟减少,PRACTISE 在 ImageNet-1k 上的 Top-1 准确性平均超过先前最先进方法 7.0%(百分点,非相对改进)。它还具有很强的鲁棒性和泛化能力,可以应用于合成/领域外图像。
3. 方法

图 2. PRACTISE 算法伪代码
图 2. PRACTISE 算法伪代码
本文所提出的方法思想非常朴素——即依次模拟每个块去掉后的恢复效果,按照推理延迟的提速需求,去掉最易恢复的块,最后再在少样本数据集上微调。该方法有三个细节值得讲一讲:可恢复性度量指标、评估可恢复性的过程和少样本微调过程。
3.1 可恢复性度量指标
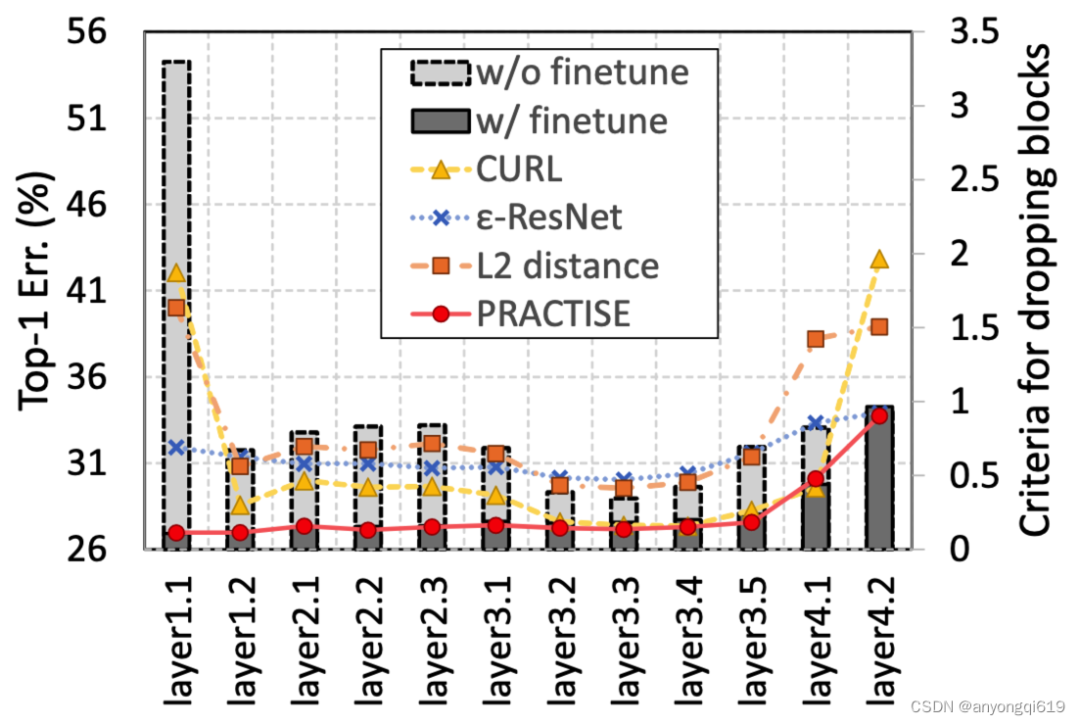
图 3. 不同层微调前后的误差及不同度量指标的数值对比
图 3. 不同层微调前后的误差及不同度量指标的数值对比
为了进一步改进块剪枝,本文研究了选择要丢弃哪些块的策略,特别是在仅有少量训练样本的情况下。作者注意到尽管丢弃某些块会显著改变特征图,但它们很容易通过端到端微调(甚至使用极少的训练集)恢复。因此,简单地测量剪枝/原始网络之间的差异是不合理的。为了解决这些问题,本文提出了一种新的概念,即可恢复性,以更好地指示要丢弃的块。该指标用于衡量修剪后的模型恢复精度的能力,相较于过去的低损害性指标,该指标更能反映“哪些模块更应该被剪去“。图 3 表明可恢复性指标几乎完美预测了微调后网络的误差。可恢复性计算公式可定义为:
其中, 是原始模型, 是丢弃 块后的模型, 是模型参数, 表示排除 的参数, 为适配器参数,适配器用于模拟恢复过程,只包括线性算子。
另一个影响因素是不同块的延迟差异,在具有相同可恢复性的情况下,较高延迟的块应该被优先丢弃,因此可定义加速比为:
最终的剪枝重要性得分为:
3.2 评估可恢复性的过程
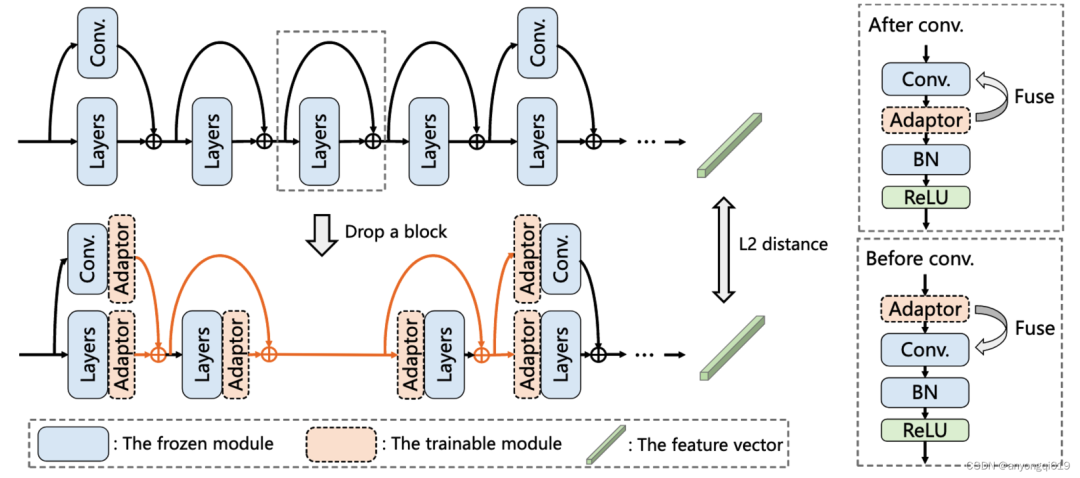
图 4. 块丢弃及评估过程的模型结构图
图 4. 块丢弃及评估过程的模型结构图
在评估阶段,PRACTISE 算法将依次去掉每一个块,在去掉 块后将在它之前的层后插入适配器,在之后的层前插入适配器,适配器均为 的卷积层。由于卷积操作是线性的,所有适配器都可以和相邻的卷积层融合(如图 4 右侧所示),同时保持输出不变。在评估阶段,算法将冻结模型参数,在少样本数据集上更新适配器参数,对比不同块去掉后在相同训练轮次下的恢复损失,作为其可恢复性度量。
3.3 少样本微调过程
最简单的微调方法就是利用交叉熵损失。然而,正如先前的工作指出的那样,修剪后的模型很容易受到过拟合的影响[2]。因此本文采用知识蒸馏中的特征蒸馏来缓解过拟合问题,同时这样的微调方法也可以在合成数据和域外数据上实现少样本微调。具体微调损失函数为:
4. 实验
少样本剪枝性能对比:如表 1 所示,PRACTISE 以显著优势超过其余所有方法,最多提升了 7%的 Top-1 准确率。该表也说明,对于少样本数据集来说,丢弃块的延迟-准确率权衡性价比优于滤波器级剪枝。

表 1. ResNet-34 在 ImageNet-1k 上的 Top-1/Top-5 准确率对比(Baseline 为 73.31%/91.42%)
表 1. ResNet-34 在 ImageNet-1k 上的 Top-1/Top-5 准确率对比(Baseline 为 73.31%/91.42%)
Data-free 剪枝方法对比:表 2 显示,在合成数据上,PRACTISE 也取得了最优的延迟-准确率权衡(更低延迟下更高性能)。
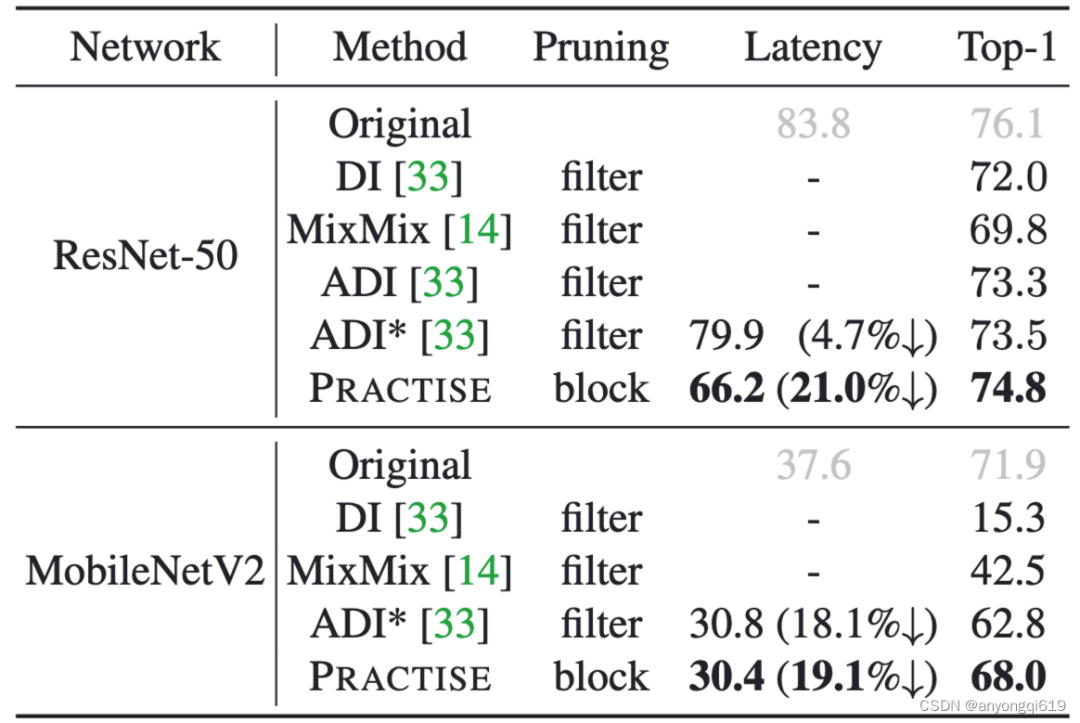
表 2. data-free 剪枝方法在 ImageNet-1k 上的性能对比
表 2. data-free 剪枝方法在 ImageNet-1k 上的性能对比
域外数据剪枝结果:如表 3 所示,PRACTISE 在域外数据上也有很强的鲁棒性和泛化性。
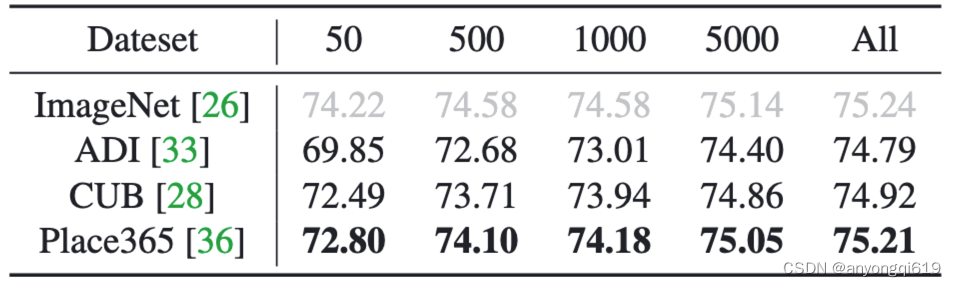
表 3. 域外训练数据下 ImageNet-1k 的剪枝性能展示
表 3. 域外训练数据下 ImageNet-1k 的剪枝性能展示
审核编辑 :李倩
-
滤波器
+关注
关注
161文章
7805浏览量
178064 -
算法
+关注
关注
23文章
4610浏览量
92859 -
卷积神经网络
+关注
关注
4文章
367浏览量
11863
原文标题:CVPR 2023:基于可恢复性度量的少样本剪枝方法
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论