 从分层架构到微服务架构介绍(五)
从分层架构到微服务架构介绍(五)
本文要介绍的是 服务化架构 (Service-Based Architecture, SBA )。
SBA 可以看成是单体架构和微服务架构之间的一个折中方案,它也是按照业务领域进行服务划分,但服务划分的粒度相比微服务要更粗。SBA 与微服务架构一大不同是, 它允许各个服务间共享同一个数据库实例 ,这也使得 SBA 在架构上既有单体架构的特点,也有分布式架构的特点,显得更加的灵活。因此, 从单体架构演进到 SBA,会比直接演进到微服务架构更加容易 。
架构视图
基础视图
SBA 的基础架构视图分成 3 部分:
- User Interface ,作为系统的接入口,接收客户端的请求,并转发到业务服务。。
- Domain Services ,业务服务按照领域进行划分,分开部署、业务独立。
- Database ,服务间共享的数据库实例,因为数据库实例只有一个,所以可以支持 ACID 事务。
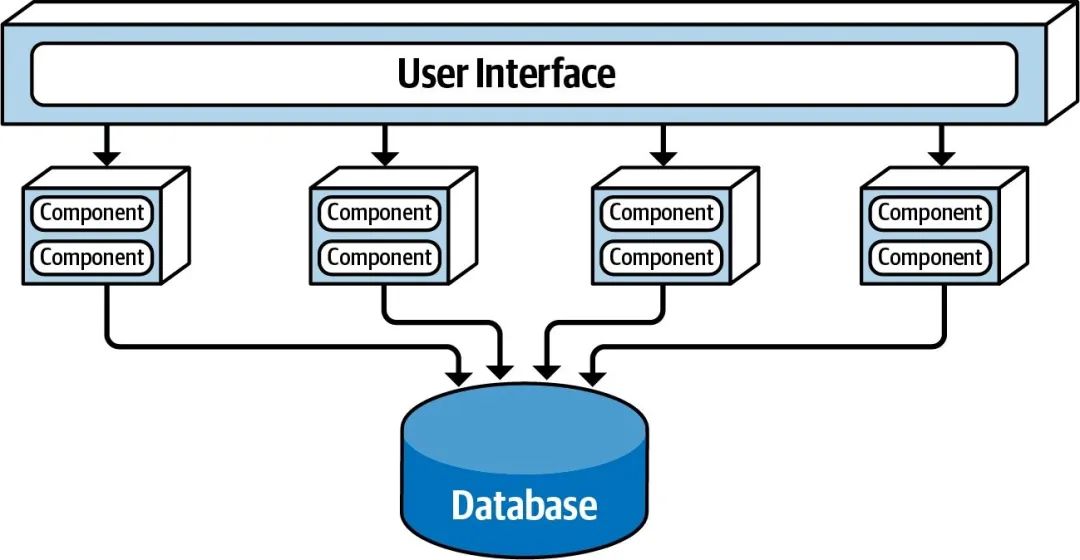
使用 SBA 的系统通常只会划分 4 ~ 12 个服务,避免产生过多的数据库连接。服务数量不多,也决定了 SBA 中的服务相比微服务架构中的服务有着更粗的粒度。User Interface 与服务间通过远程通信协议来完成业务往来,常见的通信方式有REST、RPC、消息队列等。需要注意的是, SBA 是不允许服务间通信的 ,这与微服务架构有着本质的区别。
大多数情况下, SBA 中的服务只有一个或者少量实例 ,与微服务动辄成百上千个实例有着很大的区别。主要是因为 SBA 服务粒度更粗,无法做到像微服务那样精准的按需扩容,扩容太多反而会导致资源的浪费。
SBA 的另一大特点是允许所有服务共享同一数据库实例 ,使得它能够直接将传统单体架构的那一套 SQL 查询逻辑、ACID 事务搬过来,让架构的演进更加的平滑。不过,共享数据也会带来一些问题,比如数据模型变更的影响范围更大,后面会在“ 数据拆分” 一节详细讲述。
拆分 User Interface
在大型系统中,单一的 User Interface 可能导致代码耦合、性能瓶颈等问题,这时候我们可以进一步对它进行拆分。拆分的方法可以是 基于业务领域的拆分 ,业务相关的几个服务使用同一个 User Interface;或者 基于服务的拆分 ,为每个服务都配备一个 User Interface。
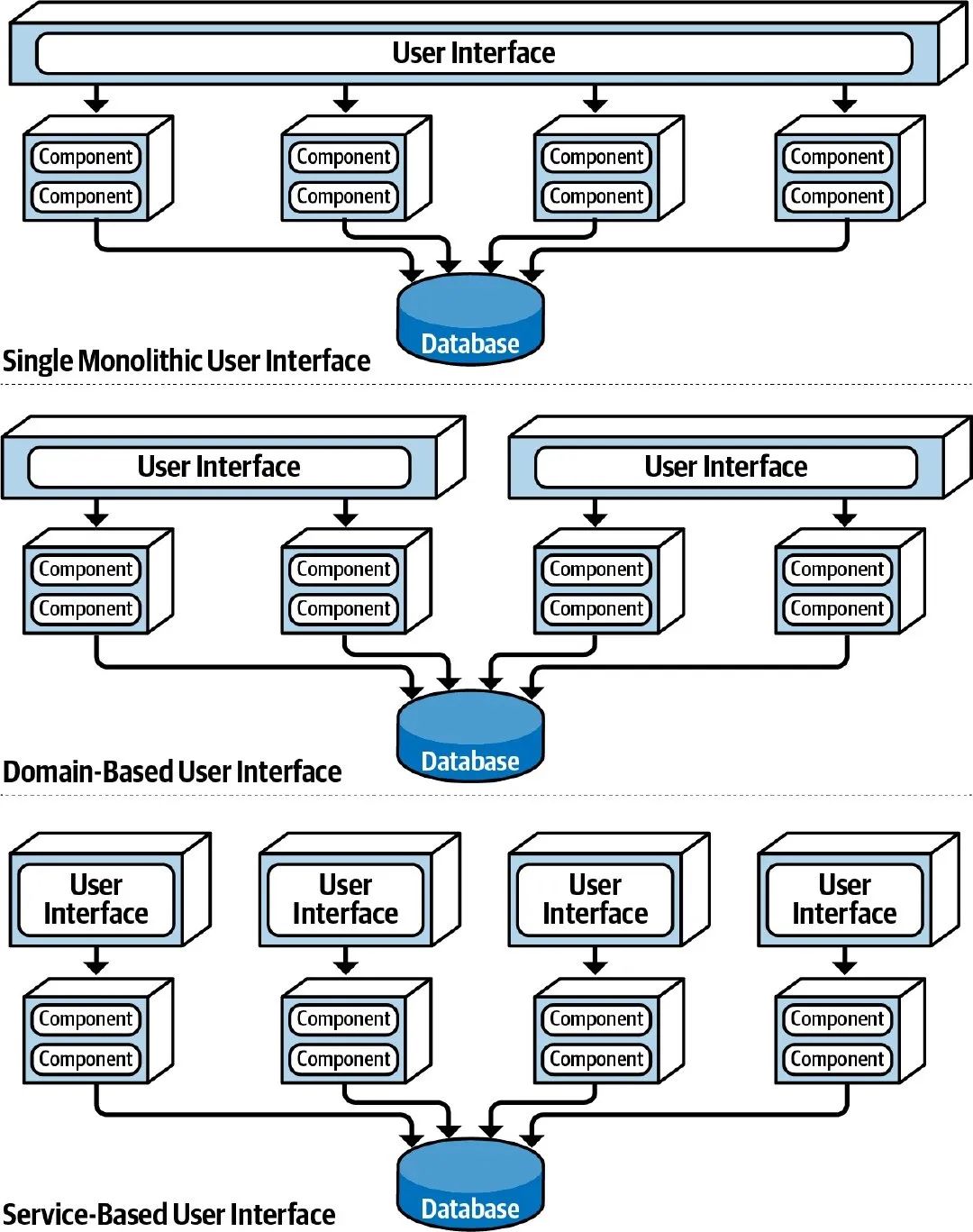
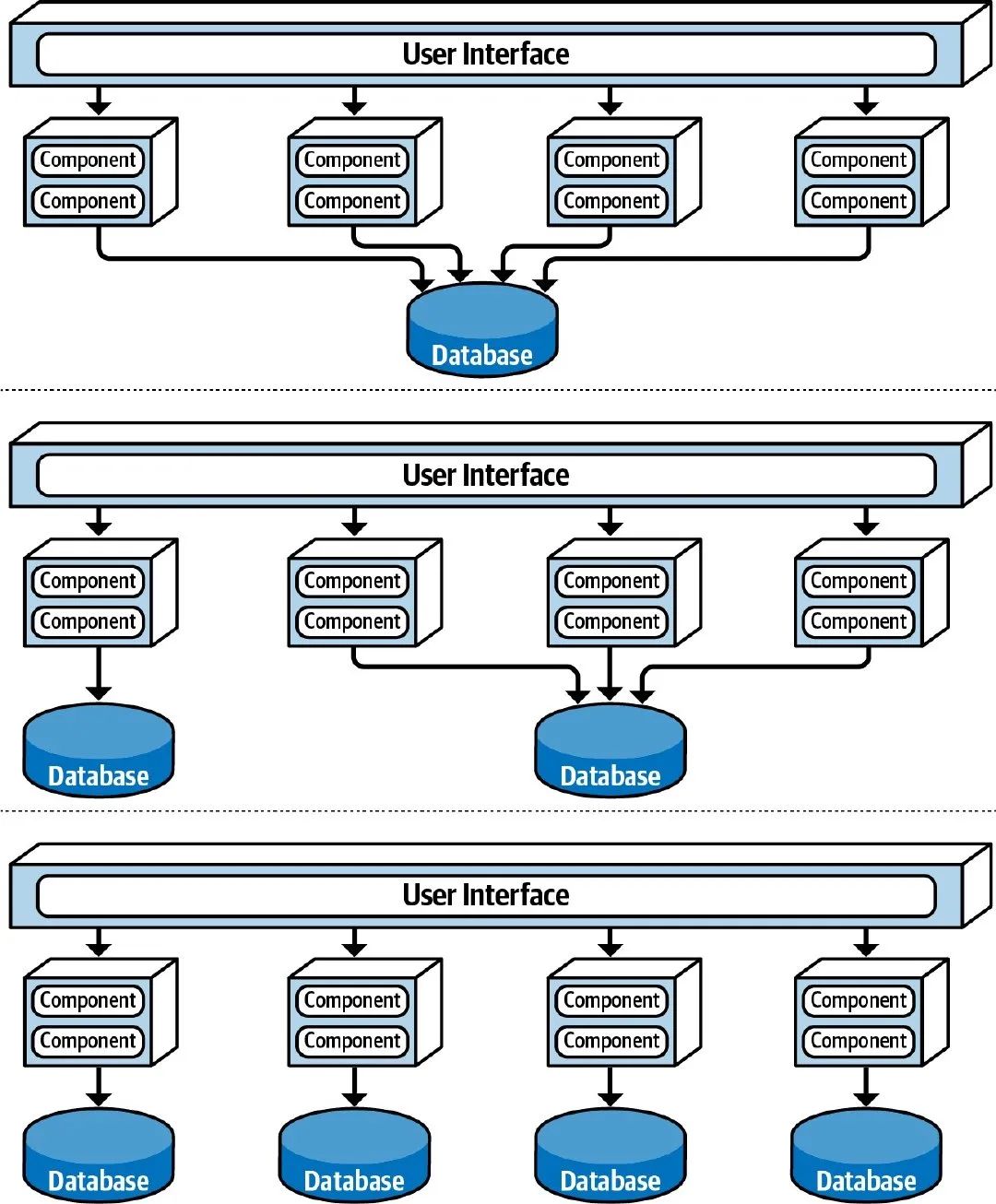
拆分 Database
类似地,我们也可以对数据库进行拆分,可以拆分成几个服务共享一个实例;也可以像微服务架构中那样,每个服务独享一个实例。数据库拆分的原则就是: 确保数据是解耦的,不会被其他服务所依赖 ,避免出现跨库查询或服务间通信。
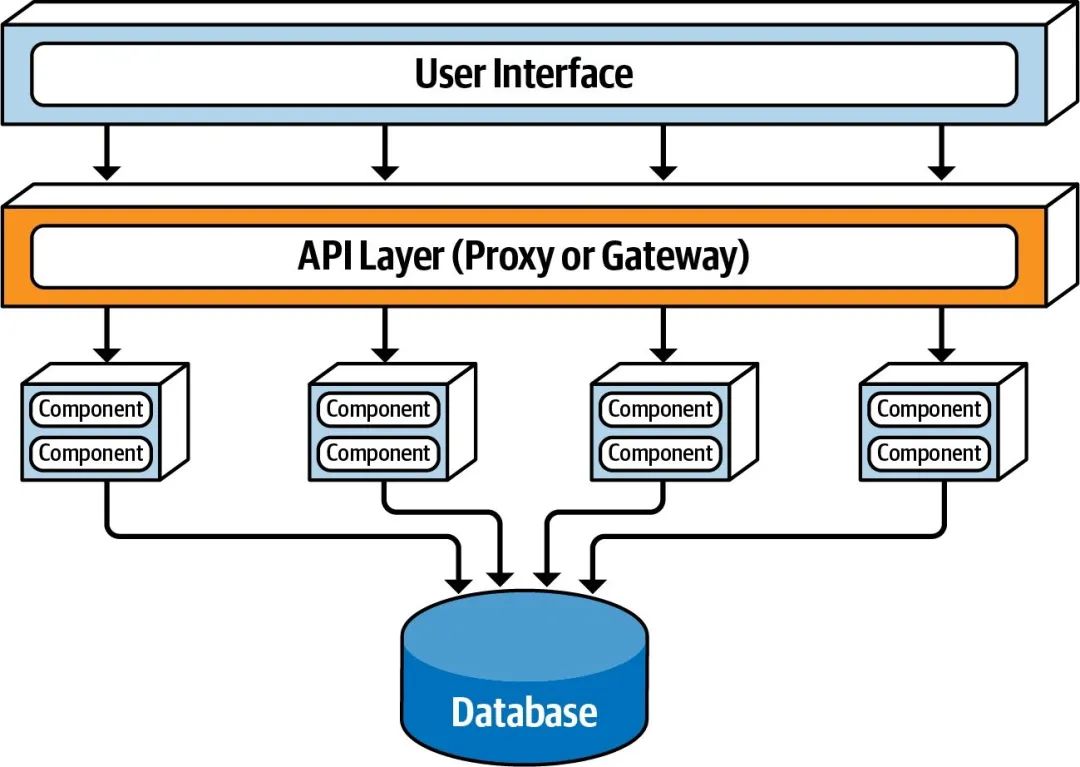
增加 API 网关
我们也可以在 User Interface 和 Domain Services 之间增加一个 API 网关层,提供流控、鉴权、指标统计、服务发现等公共能力,进一步提升系统架构的安全性、可靠性、可维护性。
业务服务的设计
SBA 中的服务具有较粗的粒度,因此在业务服务的架构设计上通常也会用到一些单体架构模式,常见的有分层架构和基于领域的 组件化架构 。
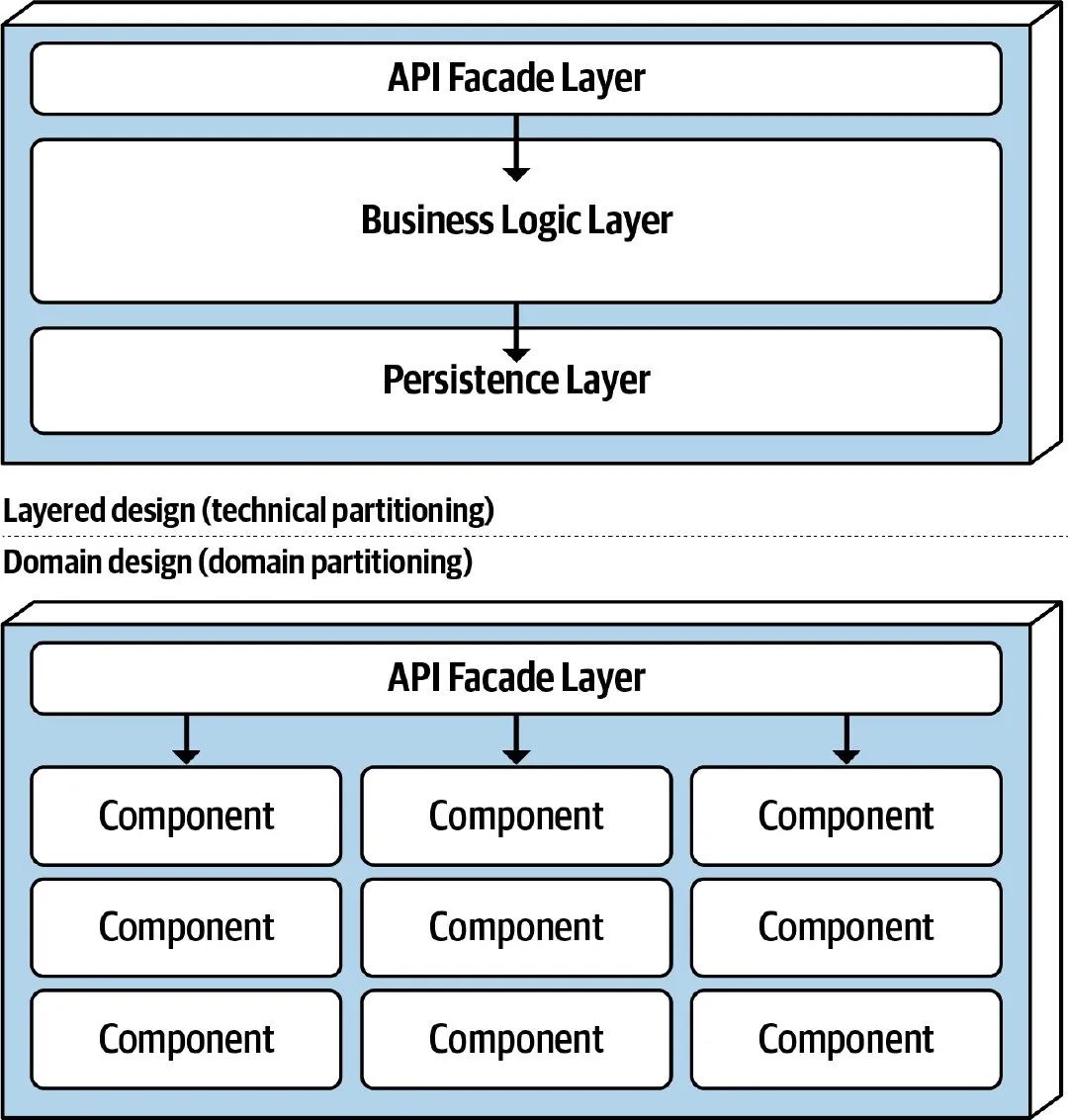
不管是分层架构还是组件化架构,通常都需要增加一个 API 层,负责编排和转发来自 User Interface 的业务请求。下面以订单创建流程作为示例。
假设现在有一个订单服务 OrderService,当它的 API 层接收到来自 User Interface 的订单创建请求时,API 层协调会各个组件依次完成如下的几个业务流程 :
- 调用订单组件,完成订单ID、订单内容的生成。
- 调用支付组件,完成用户的扣款。
- 调用库存组件,更新商品的库存数量。
因为这些业务流程都是在同一个服务内完成,当其中的某个流程异常后,我们很容易通过数据库的 ACID 事务来完成回滚,从而能够确保 数据的强一致性 。
相比在微服务架构之下,订单创建请求往往需要订单微服务、支付微服务、库存微服务之间协作来完成,这就涉及到分布式事务,也即 BASE(Basic Availability, Soft state, Eventual consistency) 事务。BASE 事务更加的复杂,而且无法保证数据的强一致性。
当然,更粗的服务粒度也会带来 服务可用性问题 ,比如在订单服务例子中,你会因为订单ID生成逻辑的变更而升级整个服务,也会因为库存组件中的一个BUG导致整个服务的故障。
所以,服务粒度的粗与细,实际上也是数据一致性和服务可用性的一次 trade-off 。
数据拆分
服务间共享数据库使得系统具有更强的数据完整性和一致性,但简单的单库单表数据模型会带来耦合的问题。
在单库单表的模型下,我们大概率会这么实现,将与数据库操作相关的实体对象、SQL 逻辑全部封装在一个共享的 shared lib 库上,供所有业务服务复用:
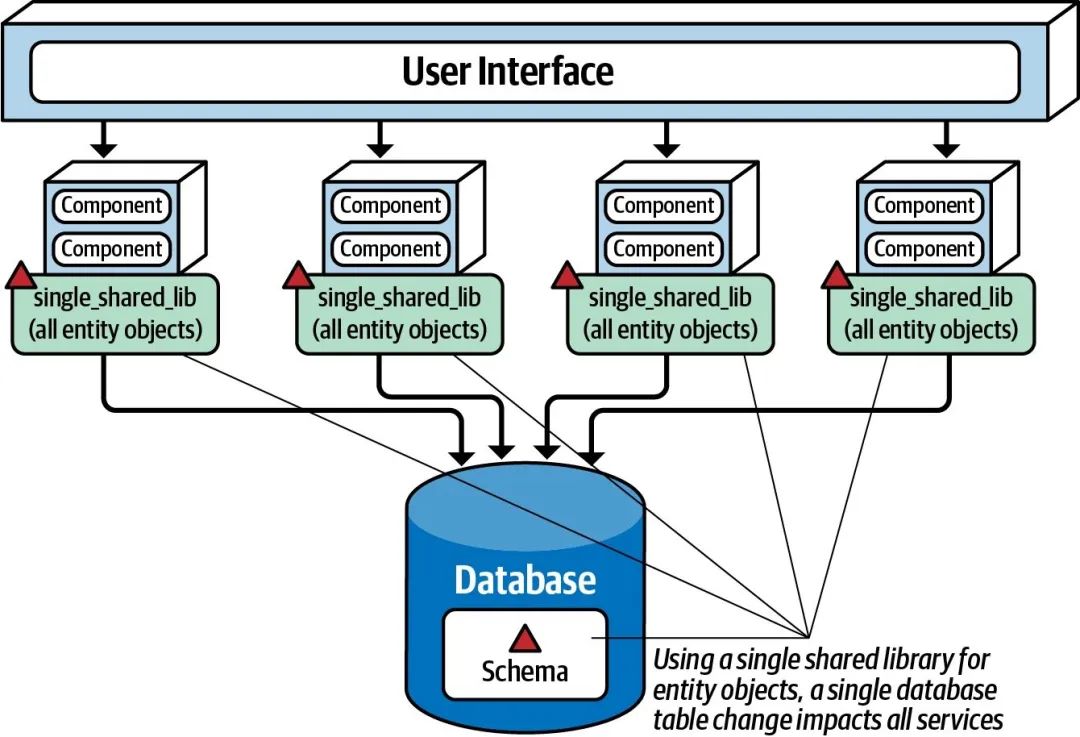
这样的实现方式虽然简单,但是会带来“ 牵一发而动全身 ”的问题。假设某个服务所用到的某个字段类型需要变化,势必会修改表结构和 shared lib 库,而这两者是所有服务共用的,因此也就会导致所有服务都需要升级重新上线。这样的耦合会给 SRE 带来极大的困扰,一点也不 敏捷 。
更好的方法是 根据业务对数据进行拆分 ,将相对独立的数据拆分成多个表,每个表都有一个独立的 lib 库,对于公共表,则有一个 common lib 库,各服务按需依赖。对于 common lib 库的变更,我们还可以通过版本控制来尽量降低影响范围,但必须在 common lib 进行版本升级时 保持向后兼容 。
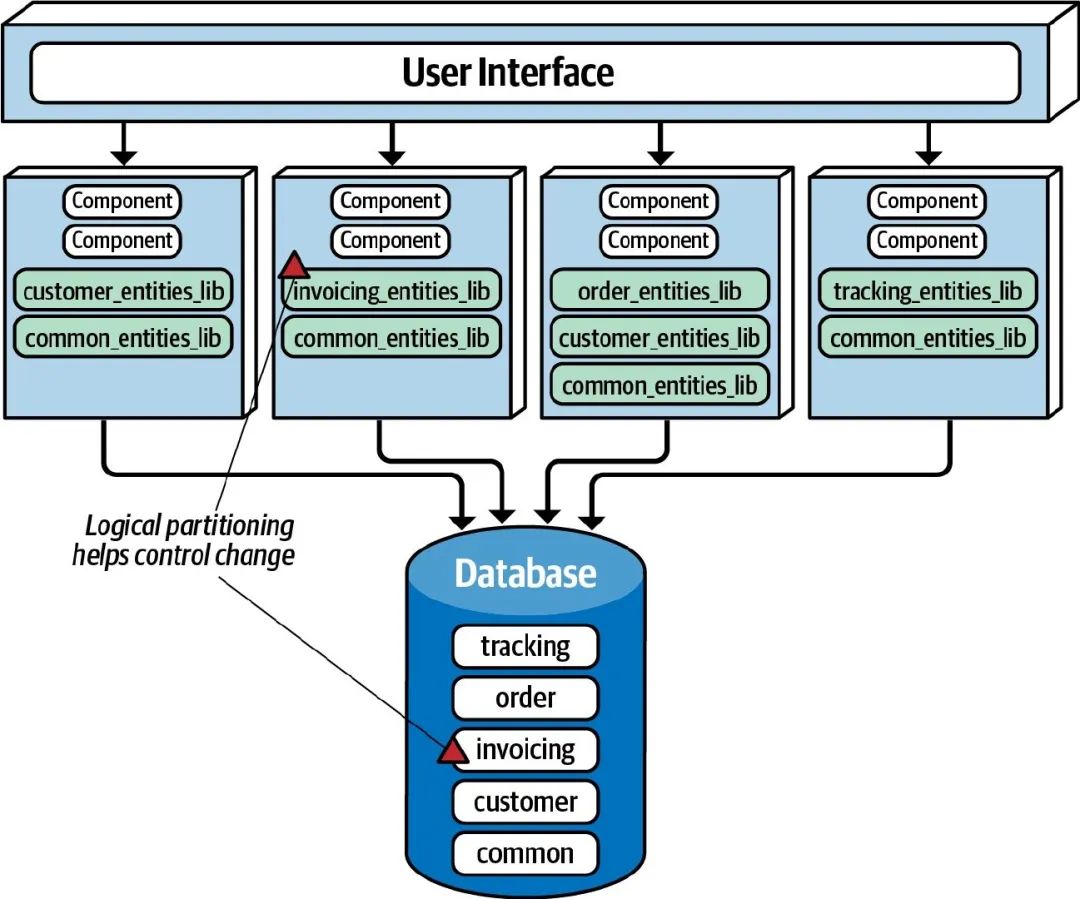
SBA 虽然是分布式架构,但是也保留了单体架构下的一些特点,在架构上具有较高的灵活性,也使得它在各方面的评分都比较高,没有明显的缺点。
SBA 是一个 domain-partitioned 的架构,因此适合使用领域驱动设计来进行领域限界上下文的划分,进而规划出业务独立的服务。服务间业务独立,而且不会相互间通信,也就意味着具有更好的 Testability 。
前文有提到过,SBA 虽然支持服务实例扩容,但是更粗的服务粒度会导致扩容的性价比并不高,因此 Scalability 和 Elasticity 得分不高。
Scalability 和 Elasticity的差异:
- Scalability 通常指软件系统在不中断业务的前提下,通过 scale-up 或 scale-out 等手段来应对更高业务负载,强调的是软件系统应对高负载的能力。
- Elasticity 通常指硬件系统能够根据实际的业务负载情况,适时增加或减少硬件资源,强调的是硬件资源的高效利用。
总结
如果你打算从单体架构演进到分布式架构,SBA 会是一个不错的选择 :
- 相比单体架构,SBA 按照业务进行服务拆分,在业务解耦、开发流程敏捷等方面有着明显的优势。
- 相比其他分布式架构,SBA 有着更粗的服务粒度,因此也得以减少了服务间的远程调用、网络带宽消耗,受网络故障的影响更小。
- 服务间共享数据库使得 SBA 支持 ACID 事务,在数据一致性方面具有良好的表现,但我们还是应该尽量按照业务进行分表,避免出现严重的数据耦合。
- 在架构评分上,SBA 各方面评分都不错,没有明显的缺点,是典型的“ 六边形战士 ”。
-
架构
+关注
关注
1文章
524浏览量
25751 -
微服务架构
+关注
关注
0文章
26浏览量
3031
发布评论请先 登录
相关推荐
微服务架构和CQRS架构基本概念介绍
什么是微服务架构_微服务架构的优缺点及应用
SOA架构和微服务架构的主要区别
微服务架构有哪些_微服务架构设计模式
微服务软件架构应用研究综述
什么是微服务架构?
从分层架构到微服务架构介绍(一)
从分层架构到微服务架构介绍(二)
从分层架构到微服务架构介绍(三)
从分层架构到微服务架构介绍(四)
springcloud微服务架构
设计微服务架构的原则

架构与设计 常见微服务分层架构的区别和落地实践





 工商网监
工商网监
评论