 ImageBind:跨模态之王,将6种模态全部绑定!
ImageBind:跨模态之王,将6种模态全部绑定!
Meta 新的开源模型 ImageBind 将多个数据流连接在一起,适用于文本、视频和音频等 6 种模态。
在人类的感官中,一张图片可以将很多体验融合到一起,比如一张海滩图片可以让我们想起海浪的声音、沙子的质地、拂面而来的微风,甚至可以激发创作一首诗的灵感。图像的这种「绑定」(binding)属性通过与自身相关的任何感官体验对齐,为学习视觉特征提供了大量监督来源。
理想情况下,对于单个联合嵌入空间,视觉特征应该通过对齐所有感官来学习。然而这需要通过同一组图像来获取所有感官类型和组合的配对数据,显然不可行。
最近,很多方法学习与文本、音频等对齐的图像特征。这些方法使用单对模态或者最多几种视觉模态。最终嵌入仅限于用于训练的模态对。因此,视频 - 音频嵌入无法直接用于图像 - 文本任务,反之亦然。学习真正的联合嵌入面临的一个主要障碍是缺乏所有模态融合在一起的大量多模态数据。
今日,Meta AI 提出了 ImageBind,它通过利用多种类型的图像配对数据来学习单个共享表示空间。该研究不需要所有模态相互同时出现的数据集,相反利用到了图像的绑定属性,只要将每个模态的嵌入与图像嵌入对齐,就会实现所有模态的迅速对齐。Meta AI 还公布了相应代码。

主页:https://imagebind.metademolab.com/
论文地址:https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
GitHub 地址:https://github.com/facebookresearch/ImageBind
具体而言,ImageBind 利用网络规模(图像、文本)匹配数据,并将其与自然存在的配对数据(视频、音频、图像、深度)相结合,以学习单个联合嵌入空间。这样做使得 ImageBind 隐式地将文本嵌入与其他模态(如音频、深度等)对齐,从而在没有显式语义或文本配对的情况下,能在这些模态上实现零样本识别功能。
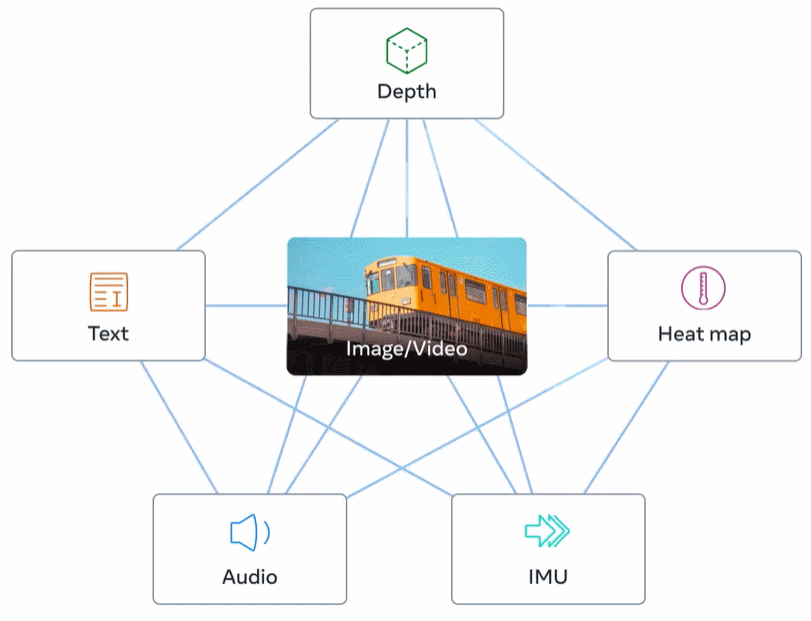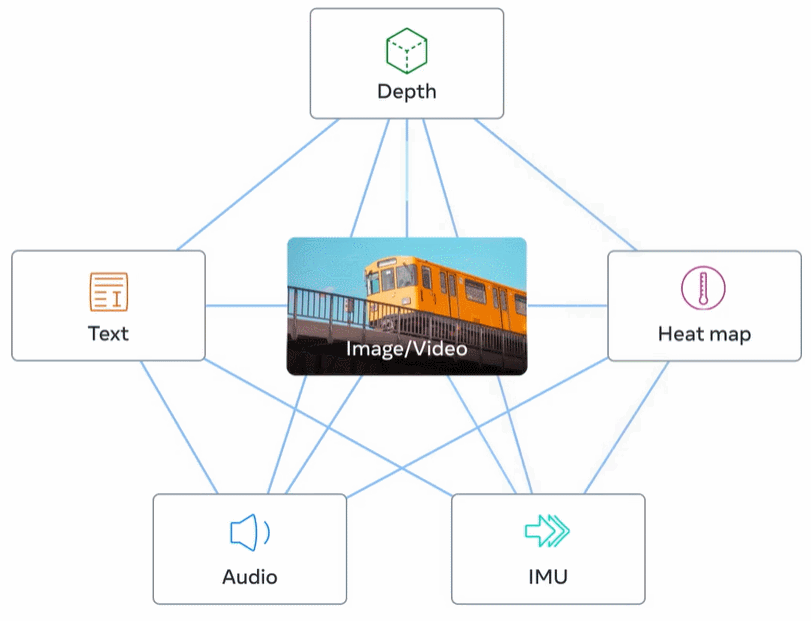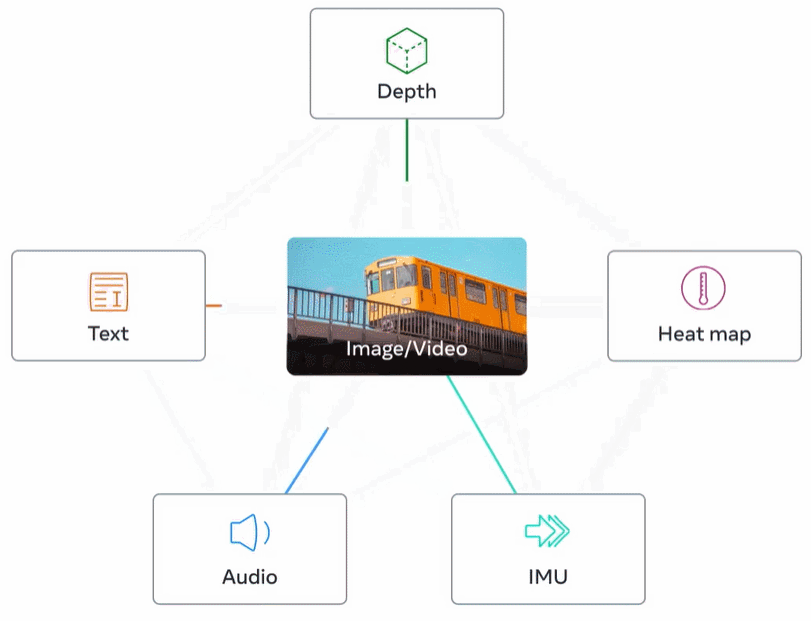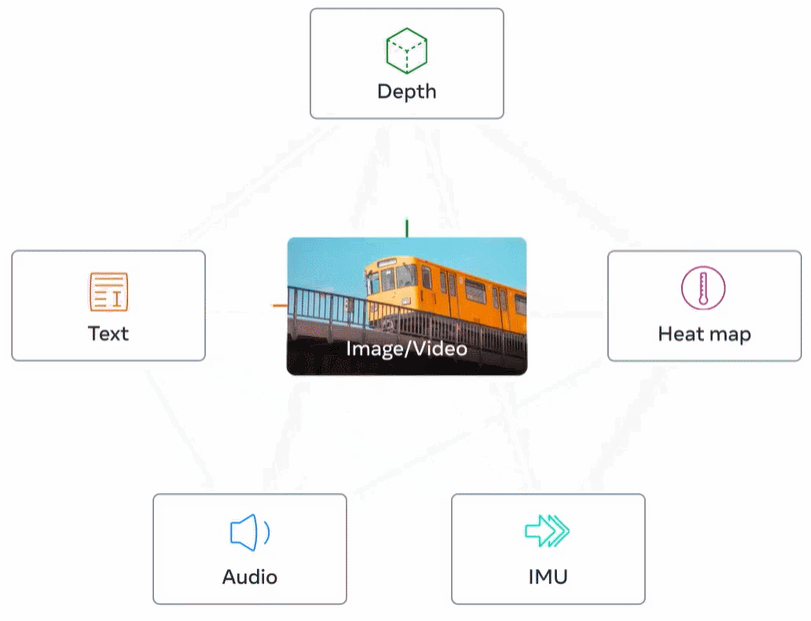
下图 2 为 ImageBind 的整体概览。

与此同时,研究者表示 ImageBind 可以使用大规模视觉语言模型(如 CLIP)进行初始化,从而利用这些模型的丰富图像和文本表示。因此,ImageBind 只需要很少的训练就可以应用于各种不同的模态和任务。
ImageBind 是 Meta 致力于创建多模态 AI 系统的一部分,从而实现从所有相关类型数据中学习。随着模态数量的增加,ImageBind 为研究人员打开了尝试开发全新整体性系统的闸门,例如结合 3D 和 IMU 传感器来设计或体验身临其境的虚拟世界。此外它还可以提供一种探索记忆的丰富方式,即组合使用文本、视频和图像来搜索图像、视频、音频文件或文本信息。
绑定内容和图像,学习单个嵌入空间
人类有能力通过很少的样本学习新概念,比如如阅读对动物的描述之后,就可以在实际生活中认出它们;通过一张不熟悉的汽车模型照片,就可以预测其引擎可能发出的声音。这在一定程度上是因为单张图像可以将整体感官体验「捆绑」在一起。然而在人工智能领域,虽然模态数量一直在增加,但多感官数据的缺乏会限制标准的需要配对数据的多模态学习。
理想情况下,一个有着不同种类数据的联合嵌入空间能让模型在学习视觉特征的同时学习其他的模态。此前,往往需要收集所有可能的配对数据组合,才能让所有模态学习联合嵌入空间。
ImageBind 规避了这个难题,它利用最近的大型视觉语言模型它将最近的大规模视觉语言模型的零样本能力扩展到新的模态,它们与图像的自然配对,如视频 - 音频和图像 - 深度数据,来学习一个联合嵌入空间。针对其他四种模式(音频、深度、热成像和 IMU 读数),研究者使用自然配对的自监督数据。
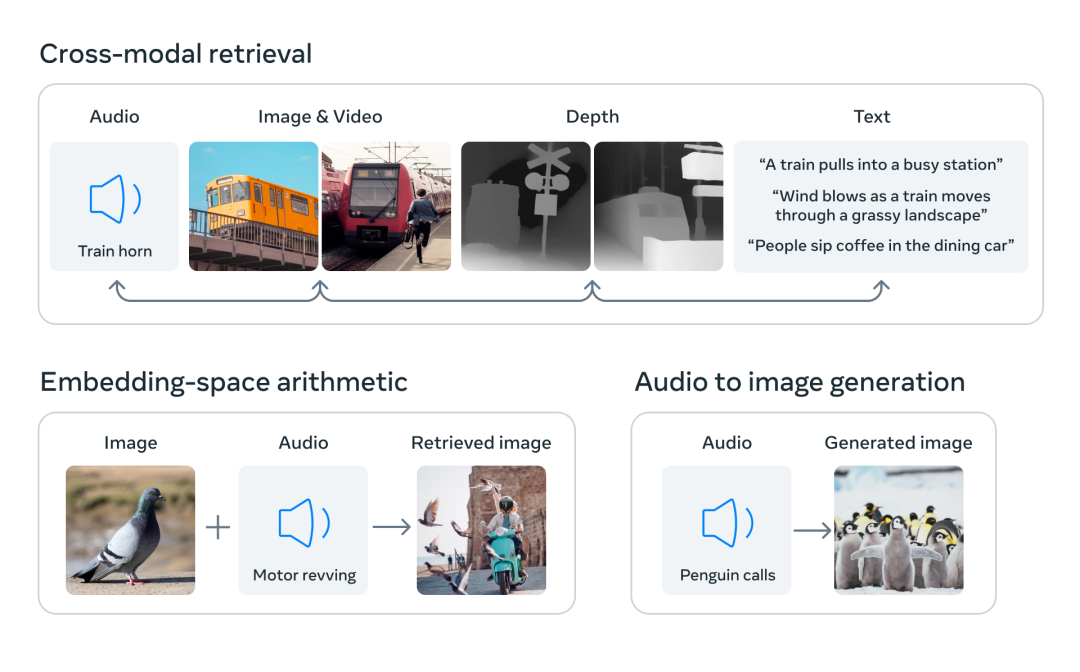
通过将六种模态的嵌入对齐到一个公共空间,ImageBind 可以跨模态检索未同时观察到的不同类型的内容,添加不同模态的嵌入以自然地对它们的语义进行组合,以及结合使用 Meta AI 的音频嵌入与预训练 DALLE-2 解码器(设计用于与 CLIP 文本嵌入)来实现音频到图像生成。
互联网上存在大量连同文本一起出现的图像,因此训练图像 - 文本模型已经得到了广泛的研究。ImageBind 利用了图像能与各种模态相连接的绑定属性,比如利用网络数据将文本与图像连接起来,或者利用在有 IMU 传感器的可穿戴相机中捕捉到的视频数据将运动与视频连接起来。
从大规模网络数据中学习到的视觉表征可以用作学习不同模态特征的目标。这使得 ImageBind 将图像与同时出现的任何模态对齐,自然地使这些模态彼此对齐。热图和深度图等与图像具有强相关性的模态更容易对齐。音频和 IMU(惯性测量单元)等非视觉的模态则具有较弱的相关性,比如婴儿哭声等特定声音可以搭配各种视觉背景。
ImageBind 表明,图像配对数据足以将这六种模态绑定在一起。该模型可以更全面地解释内容,使不同的模态可以相互「对话」,并在没有同时观察它们的情况下找到它们之间的联系。例如,ImageBind 可以在没有一起观察音频和文本的情况下将二者联系起来。这使得其他模型能够「理解」新的模态,而不需要任何资源密集型的训练。
ImageBind 强大的 scaling 表现使该模型能够替代或增强许多人工智能模型,使它们能够使用其他模态。例如虽然 Make-A-Scene 可以通过使用文本 prompt 生成图像,但 ImageBind 可以将其升级为使用音频生成图像,如笑声或雨声。
ImageBind 的卓越性能
Meta 的分析表明,ImageBind 的 scaling 行为随着图像编码器的强度而提高。换句话说,ImageBind 对齐模态的能力随着视觉模型的能力和大小而提升。这表明,更大的视觉模型对非视觉任务有利,如音频分类,而且训练这种模型的好处超出了计算机视觉任务的范畴。
在实验中,Meta 使用了 ImageBind 的音频和深度编码器,并将其与之前在 zero-shot 检索以及音频和深度分类任务中的工作进行了比较。
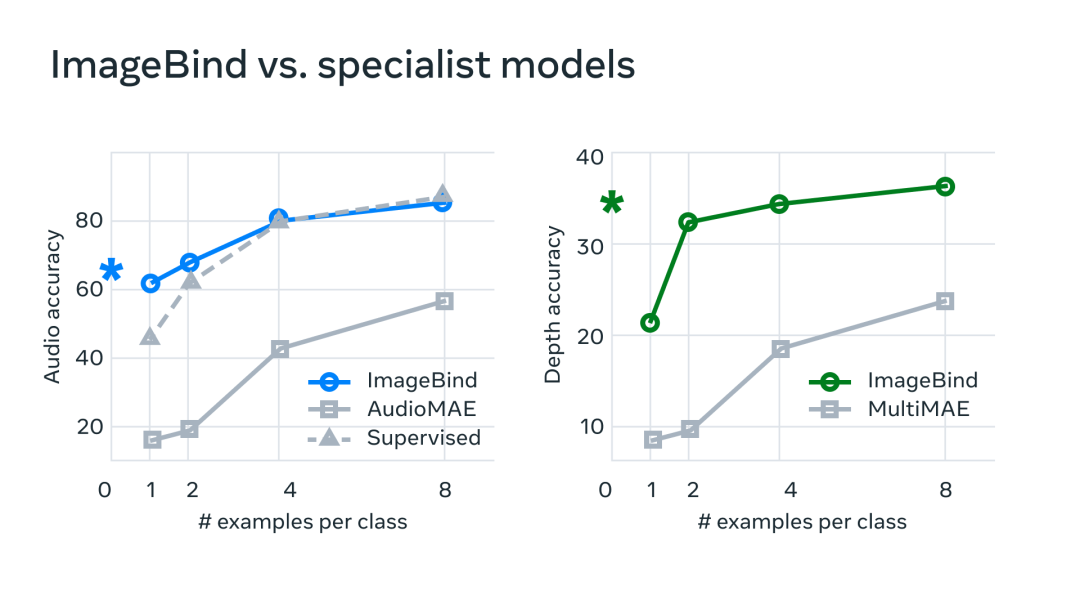
在基准测试上,mageBind 在音频和深度方面优于专家模型。
Meta 发现 ImageBind 可以用于少样本音频和深度分类任务,并且优于之前定制的方法。例如,ImageBind 明显优于 Meta 在 Audioset 上训练的自监督 AudioMAE 模型,以及在音频分类上微调的监督 AudioMAE 模型。
此外,ImageBind 还在跨模态的零样本识别任务上取得了新的 SOTA 性能,甚至优于经过训练以识别该模态概念的最新模型。
审核编辑 :李倩
-
编码器
+关注
关注
45文章
3692浏览量
135506 -
语言模型
+关注
关注
0文章
547浏览量
10372 -
数据集
+关注
关注
4文章
1212浏览量
24913
原文标题:爆火!ImageBind:跨模态之王,将6种模态全部绑定!
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OpenHarmony实战开发-如何实现模态转场
模态窗口的设置问题
labview 模态分析
LMS Virtual Lab 流固模态分析
百度研制知识增强的跨模态深度问答技术等在内的的应用系统

基于语义耦合相关的判别式跨模态哈希特征表示学习算法

可提高跨模态行人重识别算法精度的特征学习框架
模态分析定义以及模态假设理论
大模型+多模态的3种实现方法

鸿蒙ArkTS声明式开发:跨平台支持列表【全屏模态转场】模态转场设置

鸿蒙ArkTS声明式开发:跨平台支持列表【半模态转场】模态转场设置






 工商网监
工商网监
评论