 一颗Jericho3-AI芯片,用来替代InfiniBand?
一颗Jericho3-AI芯片,用来替代InfiniBand?
多样性不仅是生活的调味品,也是推动创新和降低风险的方式。这就是为什么我们看到交换机架构不断发展以驱动特定类型的 AI 工作负载,就像我们在过去两年半的时间里看到的 HPC 模拟和建模工作负载一样。
Hyperion Research:SC22 HPC Market Update(2022.11)
Hyperion Research:ISC22 Market Update(2022.5)
Intersect360全球HPC-AI市场报告(2022—2026)
在横向扩展人工智能训练的早期——也就是从 2010 年到现在——InfiniBand 是 HPC 模拟和建模的首选低延迟网络之一,它崛起成为主要的网络互连,将挤满了 GPU 的节点粘合在一起。但许多 AI 初创公司,如 Cerebras Systems、SambaNova Systems、GraphCore 和英特尔的 Gaudi 都有自己的互连,谷歌也是如此,其光开关是其 TPUv4 矩阵数学巨头的核心。如果你想大方一点,你可以说 Cray(现在是惠普企业的一部分)创建的以太网的 Slingshot 变体也是一种自定义互连,可以(并且将会)以百亿亿次级运行 AI 工作负载。
在推动人工智能革命的超大规模和云构建巨头中,博通在交换和路由半导体领域占据主导市场份额,它希望在人工智能网络行动中分得一杯羹。因此,该公司采用“Jericho”系列交换机和路由 ASIC 及其深度数据包缓冲区,并专门重新设计它们以承担 AI 工作负载,最初的 Jericho3-AI 交换机芯片是该设计的第一个实例。通过这种设计,Broadcom 已经将 InfiniBand 牢牢地放在了自己的视线之内,而且绝对是在争取它。
这意味着,除其他外,Broadcom 将让 Arista Networks 和云构建者和超大规模应用者使用的白盒交换机制造商集体在其主场 AI 领域与 Nvidia 竞争,其中包括强大的 AI 软件堆栈、GPU 以及即将推出的 CPU 和 GPU内存互连以及Nvidia 从三年前完成的 69 亿美元收购中获得的InfiniBand 网络硬件和软件。
借助 Jericho3-AI 芯片,Broadcom 正在重新设计深度缓冲 Jericho 芯片系列,这些芯片通常被超大规模用户和云构建者用来执行路由和交换功能,并为它们提供通常用于集体操作的性能。AI 和 HPC 使它们在 AI 工作负载方面与 InfiniBand 具有绝对竞争力,并赋予它们标准以太网 ASIC 所不具备的功能,包括在各种规模的数据中心中常用的“Trident”和“Tomahawk”系列中的功能。
Jericho3-AI 芯片使用相同的“Peregrine”系列 SerDes 信号电路,该电路在2022 年 8 月发布的“Tomahawk5”叶/主干以太网交换机 ASIC中首次亮相。Broadcom Trident 和 Tomahawk 交换机产品线的产品线经理 Peter Del Vecchio 向我们介绍了 Jericho3-AI,他说 Tomahawk5 ASIC 于今年 3 月开始批量出货,这意味着我们应该很快就会看到它出现在交换机中。
Tomahawk5 在某些方面是比 Jericho3-AI 更强大的设备,但它具有更适度的缓冲区,并且专为在这些超大规模和云构建者的 Clos 网络中完成的架顶和叶交换而设计。Tomahawk5 采用台湾半导体制造公司的 5 纳米工艺实现,其中 512 个 Peregrine SerDes 以 100 Gb/秒的速度运行(通过信号的 PAM-4 调制启用)包裹在数据包处理引擎和适度的缓冲区周围以创建一个设备总带宽为 51.2 Tb/秒。Jericho3-AI 芯片也采用 TSMC 的 5 纳米工艺蚀刻,具有 304 个相同的 SerDes,其中 144 个分配给下行链路,其中 160 个延伸到网络中更高层的 Ramon 3 结构元素,充当leaf 和spine开关。像这样:
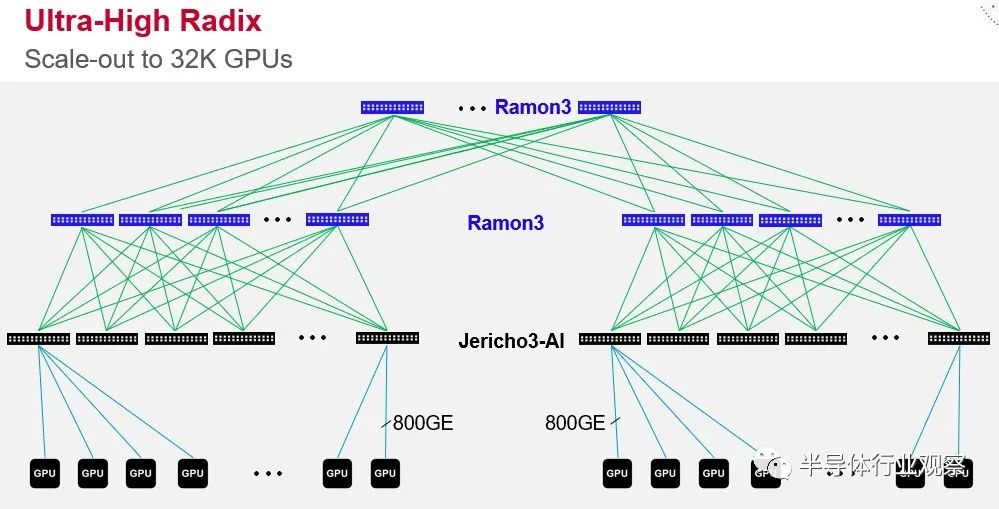
您会注意到图中的交换机端口直接链接到 GPU,这不是错误。越来越多的架构将这样做。为什么要通过服务器总线来链接 GPU?重要的是,Ramon 3 结构元素(本质上是spine互连)和 Jericho3-AI leaf或架顶式交换机的规模允许超过 32,000 个 GPU 在 Clos 拓扑中链接到一个庞大的 AI 训练系统中,以 800 Gb/秒的速度运行的端口。不可否认,今天没有服务器的端口运行速度超过 200 Gb/秒或 400 Gb/秒,因为适配卡还没有以这些本机速度运行。在 2025 年时间框架内 PCI-Express 6.0 插槽在服务器中可用之前,这可能不会发生。
现在,当微软为自己和它在 AI 框架中的合作伙伴 OpenAI 运行 GPT 训练时,它使用标准的 HGX GPU 系统板绑定到服务器主机节点,并通过一个 400 Gb/秒的 ConnectX CX7 网络接口相互链接,用于八 GPU 系统中的每个 GPU。微软 Azure 在 InfiniBand 网络上使用胖树(fat tree)拓扑,就像许多 HPC 商店所做的那样,并且还使用消息传递接口 (MPI) 协议来调度数据和计算,跨 4,000 个 GPU 链接到一个集群,以运行 GPT 和其他框架。作为单例。微软将根据需要增加它,如果 Jericho3-AI 芯片为人工智能工作负载提供更好的性能和经济性,那么微软架构中的任何内容都不会阻止它迁移到基于 Broadcom Dune StrataDNX 系列的结构,其中 Jericho3 -AI和Ramon 3是一部分。
同上所有其他云和超大规模。
这是关于 Tomahawk5 和 Jericho3-A1 的巧妙之处,因为它们使用了 Peregrine SerDes。按照这些 SerDes 的设计方式,它们可以使用所谓的线性驱动光学器件直接驱动光学器件,这意味着 SerDes 可以直接与光学器件中的跨阻放大器对话,而无需在其前面安装数字信号处理器。此外,Peregrine SerDes 可以将信号向下推送到 4 米直连铜 (DAC) 电缆——是 IEEE 规范电缆长度的两倍——无需重定时器或中继器。尽管此选项尚未商业化,但如果 Broadcom 的客户希望进一步降低热量、每比特成本和延迟,则可以使用 Peregrine SerDes 来驱动共同封装的光学器件。

从技术上讲,Jericho3-AI 芯片的额定速度为 14.4 Tb/秒,因为只有 144 个 SerDes 驱动下行链路,其余 160 个 SerDes,即 16 Tb/秒,不计入设备的官方吞吐量。芯片上可能有更多的物理SerDes,这是一个单片器件,不是由chiplet组成的,目的是在5纳米器件上的反良率被屏蔽后,增加有效SerDes的数量。(这在当今所有复杂的半导体设备设计和制造中都很常见。)如果我们有 Jericho3-AI 的die照片,我们肯定会知道。。 . 。
Jericho3-AI 芯片专门设计用于在分布式模型中的每个计算步骤结束时执行集体操作(尤其是 all-to-all 或 all reduce 操作)时帮助处理网络上的复杂流。这些功能在大型语言模型和推荐系统中至关重要,它们具有非常不同的特征并且需要稍微不同的硬件(这就是为什么“Hopper”GPU 需要紧密耦合的“Grace”CPU 用于未来专注于推荐系统的 Nvidia 系统) 。
Meta Platforms 基础设施副总裁 Alexis Bjorlin在去年 10 月的开放计算项目峰会上的主题演讲中谈到了其“Grand Teton”AI 系统和配套“Grand Canyon”存储阵列的设计,而我们并不知道她分享了下图涉及四种不同的机器学习模型,这些模型是Meta Platforms 使用的深度学习推荐模型 (DLRM) 推荐系统的一部分,该系统于 2019 年 7 月开源:
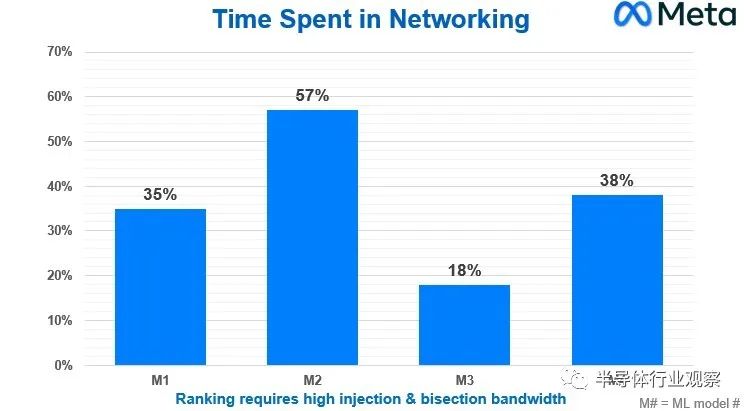
此图表显示的是在下一个计算步骤开始之前等待集体操作在网络上运行所浪费的 CPU 时间百分比。它是挂钟时间减去计算时间除以挂钟时间,得到网络时间。
现在,这些庞大的 AI 集群中的单个节点成本可能为 400,000 到 500,000 美元,根据模型的不同,有 18%、35%、38% 或 57% 的时间都在那里,这确实是一个非常昂贵的提议。 通过针对 AI 工作负载优化的网络,集体操作的网络效率的任何变化都意味着 CPU-GPU 硬件投资不会按比例浪费。
为了解 Jericho3-AI 如何与 InfiniBand 竞争,Broadcom 与其中一家超大规模厂商合作,更换了连接 GPU 加速计算节点的 200 Gb/秒 InfiniBand 交换机,并将该 InfiniBand 交换机替换为以太网交换机。这两款交换机都运行 Nvidia 集体通信库 (NCCL),这是一种由 Nvidia 创建的集体操作网络软件驱动程序,旨在为密集的 GPU 分组提供比在 CPU 内核或插槽上运行普通 MPI 更好的集体操作性能。NCCL 是拓扑感知的,这意味着它知道计算节点内的快速和fat NVLink 管道与跨节点的 InfiniBand 或以太网管道之间的区别。这些不是非此即彼的命题,NCCL 和 MPI 经常一起使用。
以下是在支持 InfiniBand 或以太网协议的 ConnectX-6 SmartNIC 上具有多达 16 个 200 Gb/秒端口的服务器与基于 Nvidia 的 Quantum 2 ASIC 或 Broadcom 的 Jericho3-AI ASIC 的交换机之间的性能差异:
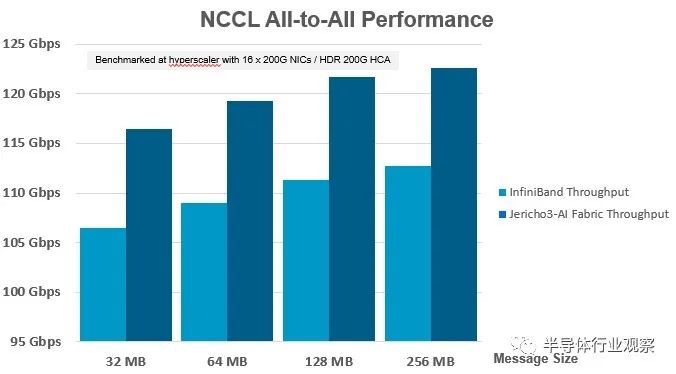
您必须仔细观察 Y 轴,因为两个交换机的整体集体操作性能不是从 0 Gb/秒到 125 Gb/秒,而是从 95 Gb/秒到 125 Gb/秒,这意味着此图表中的性能增量在视觉上比实际大。结果是,几乎无论消息大小如何,Jericho3-AI 芯片提供的吞吐量比运行相同 AI 训练工作负载的 InfiniBand 交换机高出约 10%。
现在,如果您查看 Meta Platforms 提供的图表,10% 是一个大问题。任何能提高网络有效加速的东西都会缩短集体操作的挂钟时间。Del Vecchio 告诉The Next Platform,Jericho3-AI switch 的性能提速对于所有 reduce 集体操作也有大约 10%(但我们没有这方面的图表)。这意味着完成 AI 训练运行的时间也将缩短,如果时间就是金钱——通常是在涉及 AI 和 HPC 工作负载时——那么可以同时训练更多模型。再加上节能和更长的 DAC,Broadcom 将在 AI 培训方面拥有令人信服的价值主张,以与 InfiniBand 竞争。
Broadcom 如何为 InfiniBand 带来热度?Jericho3-AI 芯片有一些功能名称看起来非常奇特,但归根结底是更好的负载平衡和拥塞控制,可以减少网络争用并改善网络延迟,坦率地说,这比降低延迟更重要在交换机内部端口到端口的跳跃上,与基于 ASIC(如 Tridents 和 Tomahawks)的传统数据中心级以太网交换机及其来自 Cisco Systems 的竞争产品相比,InfiniBand 具有巨大的优势——大约 3 到 4 倍或更多(那是我们说的,不是 Broadcom。但这是真的。)
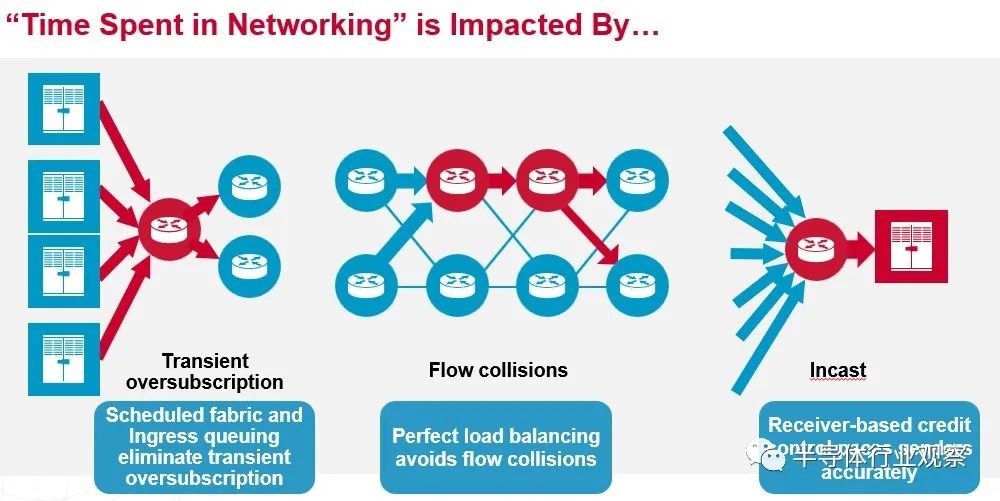
Jericho3-AI 芯片的两个重要特性就是 Broadcom 夸张地称之为完美的负载平衡和无拥塞操作。这是一张从概念上显示它们如何协同工作的图片:
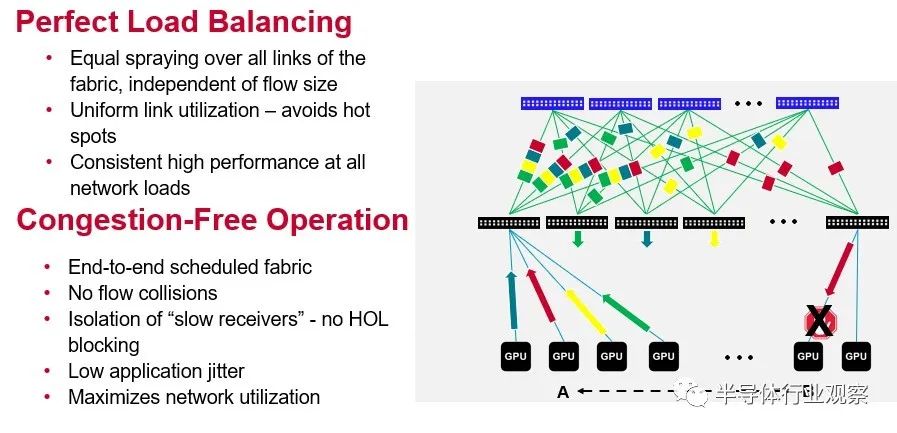
我们高度怀疑任何负载平衡是否“完美”或网络操作是否可以“无拥塞”,但显然,根据 Broadcom 展示的结果,Jericho3-AI 在 AI 训练工作负载方面将比 Tomahawk 做得更好或 Trident ASIC 可以并且基于这组有限的性能数据,应该让 InfiniBand 与 AI 训练资金竞争。
我们的问题是:Jericho3-AI 芯片是否会像 InfiniBand 那样帮助处理传统的 HPC 模拟和建模工作负载?
“这取决于 HPC 的类型,”Del Vecchio 说。“但如果吞吐量对应用程序很重要,那当然是肯定的。HPC 应用程序也将获得这些好处,您最终将获得无拥塞操作、非常好的负载平衡以及更有效地利用链接。与 HPC 相比,AI 更倾向于关注整个网络的原始吞吐量,后者才是最重要的端到端延迟。HPC 有很多非常短的消息,因此消息速率非常关键。所以有一些不同。但关键是要确保负载平衡,如果没有拥塞——这些将同样适用于 AI 和 HPC。”
Jericho3-AI 开关芯片现在正在出样,预计会像 Tomahawk5 那样有相对较快的提升。
审核编辑 :李倩
-
芯片
+关注
关注
459文章
51891浏览量
433212 -
gpu
+关注
关注
28文章
4880浏览量
130343 -
网络硬件
+关注
关注
0文章
10浏览量
6262
原文标题:一颗Jericho3-AI芯片,用来替代InfiniBand?
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
寒武纪思元370芯片参数特性详解
如何用一颗SOP8芯片实现色温+亮度精准控制?

用一颗TXB0104可以进行串口电压转换吗?

用一颗5G的204B接口DA芯片,DA芯片的输入时钟大小和输入数据的速率是怎么样的关系?
一颗射频开关的独白
请问AIC3254能不能替代C5502+AIC32B?
两颗TAS5711,一颗作2.0输出,一颗作PBTL输出,共用一个I2S_DATA时发现失真增大,为什么?
InfiniBand网络内计算的关键技术和应用
OPA197如果使用多阶,用一颗跟随器提供基准电压是否可行?
钰泰ETA300X主动均衡芯片,一颗可以劫富济贫的芯片
HT7017 是一颗带 UART 通讯接口的高精度单相多功能计量芯片

推荐一颗简单易用、高性能的专门用于433/315Mhz的射频ICXL4456
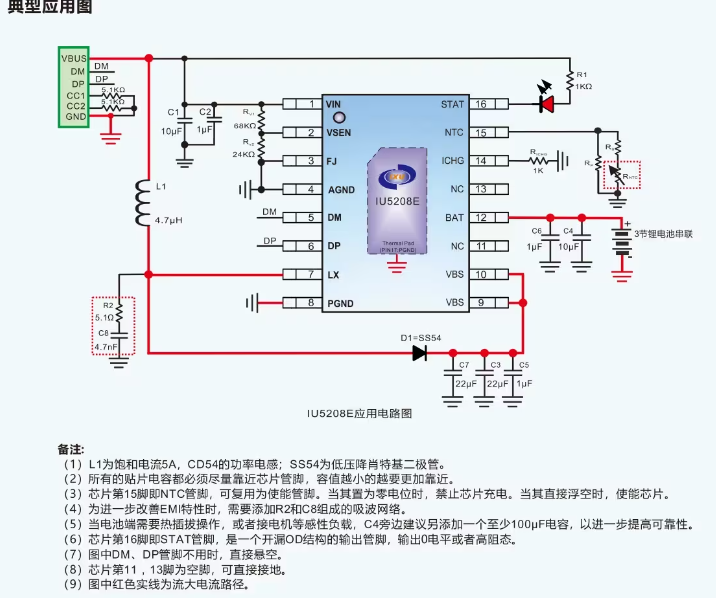
IU5208介绍一颗带诱骗的升压充电3节锂电池1.3A的充电电流充18W





 工商网监
工商网监
评论