 volatile的实现原理分析
volatile的实现原理分析
volatile的作用是什么?
volatile是一个轻量级的synchronized,一般作用于 变量 ,在多处理器开发的过程中保证了内存的可见性。相比于synchronized关键字,volatile关键字的执行成本更低,效率更高。
volatile的特性有哪些?
并发编程的三大特性为可见性、有序性和原子性。通常来讲
volatile可以保证可见性和有序性。
- 可见性:
volatile可以保证不同线程对共享变量进行操作时的可见性。即当一个线程修改了共享变量时,另一个线程可以读取到共享变量被修改后的值。 - 有序性:
volatile会通过禁止指令重排序进而保证有序性。 - 原子性:对于单个的
volatile修饰的变量的读写是可以保证原子性的,但对于i++这种复合操作并不能保证原子性。这句话的意思基本上就是说volatile不具备原子性了。
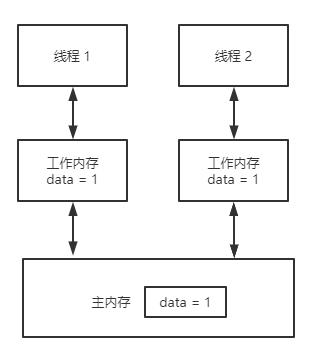
Java内存的可见性问题
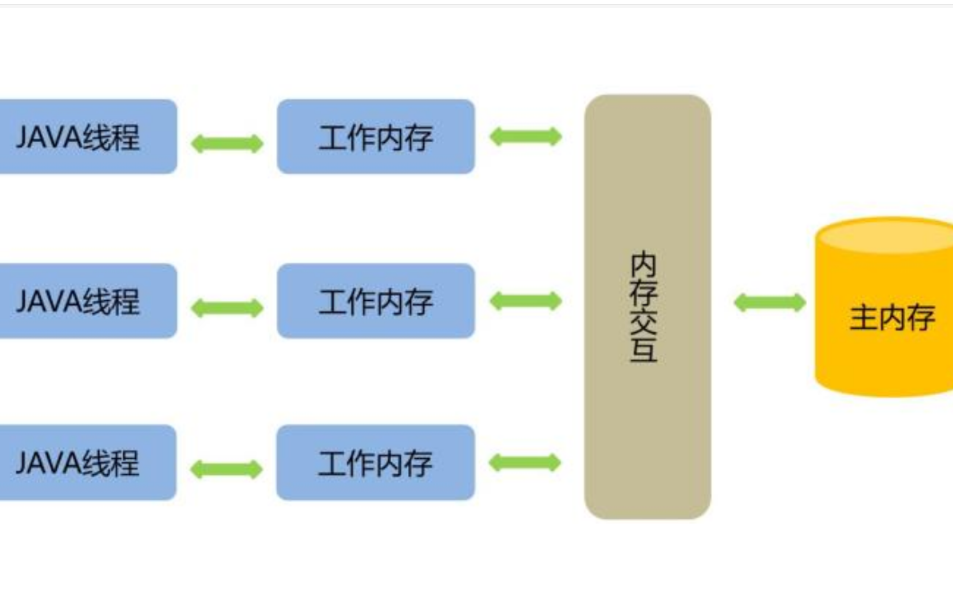
Java的内存模型如下图所示。
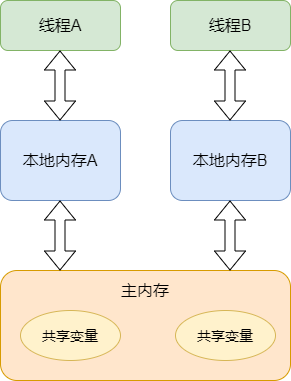
这里的本地内存并不是真实存在的,只是Java内存模型的一个抽象概念,它包含了控制器、运算器、缓存等。同时Java内存模型规定,线程对共享变量的操作必须在自己的本地内存中进行,不能直接在主内存中操作共享变量。这种内存模型会出现什么问题呢?,
- 线程A获取到共享变量X的值,此时本地内存A中没有X的值,所以加载主内存中的X值并缓存到本地内存A中,线程A修改X的值为1,并将X的值刷新到主内存中,这时主内存及本地内存A中的X的值都为1。
- 线程B需要获取共享变量X的值,此时本地内存B中没有X的值,加载主内存中的X值并缓存到本地内存B中,此时X的值为1。线程B修改X的值为2,并刷新到主内存中,此时主内存及本地内存B中的X值为2,本地内存A中的X值为1。
- 线程A再次获取共享变量X的值,此时本地内存中存在X的值,所以直接从本地内存中A获取到了X为1的值,但此时主内存中X的值为2,到此出现了所谓内存不可见的问题。
该问题Java内存模型是通过synchronized关键字和volatile关键字就可以解决。
为什么代码会重排序?
计算机在执行程序的过程中,编译器和处理器通常会对指令进行重排序,这样做的目的是为了提高性能。具体可以看下面这个例子。
int a = 1;
int b = 2;
int a1 = a;
int b1 = b;
int a2 = a + a;
int b2 = b + b;
......
像这段代码,不断地交替读取a和b,会导致寄存器频繁交替存储a和b,使得代码性能下降,可对其进入如下重排序。
int a = 1;
int b = 2;
int a1 = a;
int a2 = a + a;
int b1 = b;
int b2 = b + b;
......
按照这样的顺序执行代码便可以避免交替读取a和b,这就是重排序的意义。
指令重排序一般分为编译器优化重排、指令并行重排和内存系统重排三种。
- 编译器优化重排:编译器在不改变单线程程序语义的情况下,可以对语句的执行顺序进行重新排序。
- 指令并行重排:现代处理器多采用指令级并行技术来将多条指令重叠执行。对于不存在数据依赖的程序,处理器可以对机器指令的执行顺序进行重新排列。
- 内存系统重排:因为处理器使用缓存和读/写缓冲区,使得加载(load)和存储(store)看上去像是在乱序执行。
注:简单解释下数据依赖性:如果两个操作访问了同一个变量,并且这两个操作有一个是写操作,这两个操作之间就会存在数据依赖性,例如:
a = 1;
b = a;
如果对这两个操作的执行顺序进行重排序的话,那么结果就会出现问题。
其实,这三种指令重排说明了一个问题,就是指令重排在单线程下可以提高代码的性能,但在多线程下可以会出现一些问题。
重排序会引发什么问题?
前面已经说过了,在单线程程序中,重排序并不会影响程序的运行结果,而在多线程场景下就不一定了。可以看下面这个经典的例子,该示例出自《Java并发编程的艺术》。
class ReorderExample{
int a = 0;
boolean flag = false;
public void writer(){
a = 1; // 操作1
flag = true; // 操作2
}
public void reader(){
if(flag){ // 操作3
int i = a + a; // 操作4
}
}
}
假设线程1先执行writer()方法,随后线程2执行reader()方法,最后程序一定会得到正确的结果吗?
答案是不一定的,如果代码按照下图的执行顺序执行代码则会出现问题。
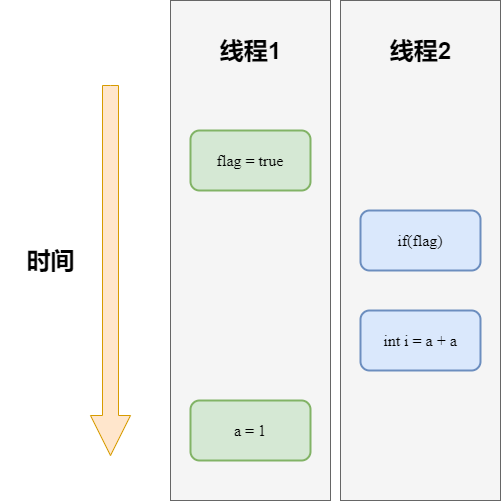
操作1和操作2进行了重排序,线程1先执行flag=true,然后线程2执行操作3和操作4,线程2执行操作4时不能正确读取到a的值,导致最终程序运行结果出问题。这也说明了在多线程代码中,重排序会破坏多线程程序的语义。
as-if-serial规则和happens-before规则的区别?
区别:
- as-if-serial定义:无论编译器和处理器如何进行重排序,单线程程序的执行结果不会改变。
- happens-before定义:一个操作happens-before另一个操作,表示第一个的操作结果对第二个操作可见,并且第一个操作的执行顺序也在第二个操作之前。但这并不意味着Java虚拟机必须按照这个顺序来执行程序。如果重排序的后的执行结果与按happens-before关系执行的结果一致,Java虚拟机也会允许重排序的发生。
- happens-before关系保证了同步的多线程程序的执行结果不被改变,as-if-serial保证了单线程内程序的执行结果不被改变。
相同点:happens-before和as-if-serial的作用都是在不改变程序执行结果的前提下,提高程序执行的并行度。
voliatile的实现原理?
前面已经讲述
volatile具备可见性和有序性两大特性,所以volatile的实现原理也是围绕如何实现可见性和有序性展开的。
volatile实现内存可见性原理
导致内存不可见的主要原因就是Java内存模型中的本地内存和主内存之间的值不一致所导致,例如上面所说线程A访问自己本地内存A的X值时,但此时主内存的X值已经被线程B所修改,所以线程A所访问到的值是一个脏数据。那如何解决这种问题呢?
volatile可以保证内存可见性的关键是volatile的读/写实现了缓存一致性,缓存一致性的主要内容为:
- 每个处理器会通过嗅探总线上的数据来查看自己的数据是否过期,一旦处理器发现自己缓存对应的内存地址被修改,就会将当前处理器的缓存设为无效状态。此时,如果处理器需要获取这个数据需重新从主内存将其读取到本地内存。
- 当处理器写数据时,如果发现操作的是共享变量,会通知其他处理器将该变量的缓存设为无效状态。
那缓存一致性是如何实现的呢?可以发现通过volatile修饰的变量,生成汇编指令时会比普通的变量多出一个Lock指令,这个Lock指令就是volatile关键字可以保证内存可见性的关键,它主要有两个作用:
- 将当前处理器缓存的数据刷新到主内存。
- 刷新到主内存时会使得其他处理器缓存的该内存地址的数据无效。
volatile实现有序性原理
前面提到重排序可以提高代码的执行效率,但在多线程程序中可以导致程序的运行结果不正确,那
volatile是如何解决这一问题的呢?
为了实现volatile的内存语义,编译器在生成字节码时会通过插入内存屏障来禁止指令重排序。
内存屏障:内存屏障是一种CPU指令,它的作用是对该指令前和指令后的一些操作产生一定的约束,保证一些操作按顺序执行。
Java虚拟机插入内存屏障的策略
Java内存模型把内存屏障分为4类,如下表所示:
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 保证Load1数据的读取先于Load2及后续所有读取指令的执行 |
| StoreStore Barriers | Store1;StoreStore;Store2 | 保证Store1数据刷新到主内存先于Store2及后续所有存储指令 |
| LoadStore Barriers | Load1;LoadStore;Store2 | 保证Load1数据的读取先于Store2及后续的所有存储指令刷新到主内存 |
| StoreLoad Barriers | Store1;StoreLoad;Load2 | 保证Store1数据刷新到主内存先于Load2及后续所有读取指令的执行 |
注:StoreLoad Barriers同时具备其他三个屏障的作用,它会使得该屏障之前的所有内存访问指令完成之后,才会执行该屏障之后的内存访问命令。
Java内存模型对编译器指定的volatile重排序规则为:
- 当第一个操作是
volatile读时,无论第二个操作是什么都不能进行重排序。 - 当第二个操作是
volatile写时,无论第一个操作是什么都不能进行重排序。 - 当第一个操作是
volatile写,第二个操作为volatile读时,不能进行重排序。
根据volatile重排序规则,Java内存模型采取的是保守的屏障插入策略,volatile写是在前面和后面分别插入内存屏障,volatile读是在后面插入两个内存屏障,具体如下:
volatile读:在每个volatile读后面分别插入LoadLoad屏障及LoadStore屏障(根据volatile重排序规则第一条),如下图所示
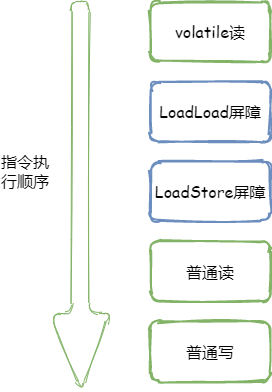
LoadLoad屏障的作用:禁止上面的所有普通读操作和上面的volatile读操作进行重排序。
LoadStore屏障的作用:禁止下面的普通写和上面的volatile读进行重排序。
volatile写:在每个volatile写前面插入一个StoreStore屏障(为满足volatile重排序规则第二条),在每个volatile写后面插入一个StoreLoad屏障(为满足voaltile重排序规则第三条),如下图所示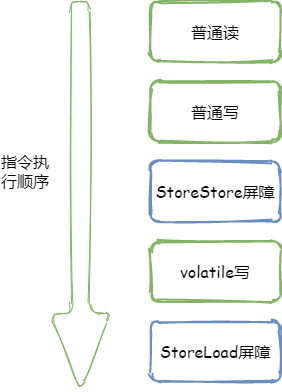
StoreStore屏障的作用:禁止上面的普通写和下面的volatile写重排序
StoreLoad屏障的作用:防止上面的volatile写与下面可能出现的volatile读/写重排序。
编译器对内存屏障插入策略的优化
因为Java内存模型所采用的屏障插入策略比较保守,所以在实际的执行过程中,只要不改变
volatile读/写的内存语义,编译器通常会省略一些不必要的内存屏障。
代码如下:
public class VolatileBarrierDemo{
int a;
volatile int b = 1;
volatile int c = 2;
public void test(){
int i = b; //volatile读
int j = c; //volatile读
a = i + j; //普通写
}
}
指令序列示意图如下:
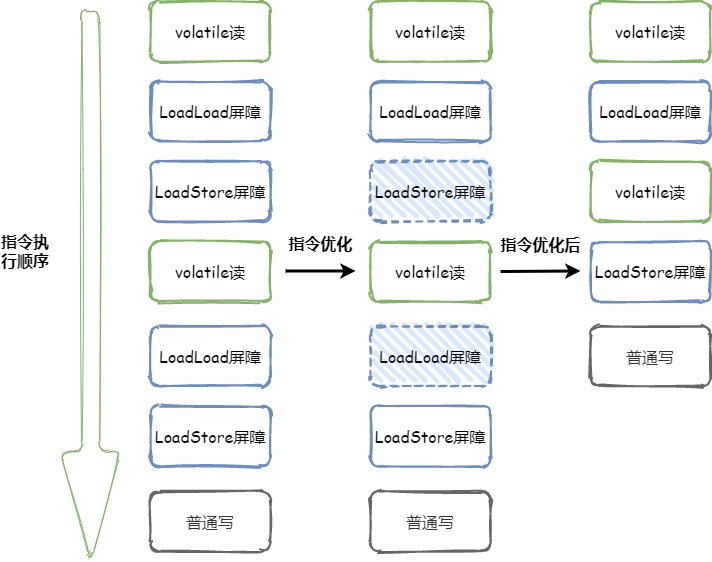
从上图可以看出,通过指令优化一共省略了两个内存屏障(虚线表示),省略第一个内存屏障LoadStore的原因是最后的普通写不可能越过第二个volatile读,省略第二个内存屏障LoadLoad的原因是下面没有涉及到普通读的操作。
volatile能使一个非原子操作变成一个原子操作吗?
volatile只能保证可见性和有序性,但可以保证64位的long型和double型变量的原子性。
对于32位的虚拟机来说,每次原子读写都是32位的,会将long和double型变量拆分成两个32位的操作来执行,这样long和double型变量的读写就不能保证原子性了,而通过volatile修饰的long和double型变量则可以保证其原子性。
volatile、synchronized的区别?
volatile主要是保证内存的可见性,即变量在寄存器中的内存是不确定的,需要从主存中读取。synchronized主要是解决多个线程访问资源的同步性。volatile作用于变量,synchronized作用于代码块或者方法。volatile仅可以保证数据的可见性,不能保证数据的原子性。synchronized可以保证数据的可见性和原子性。volatile不会造成线程的阻塞,synchronized会造成线程的阻塞。
-
处理器
+关注
关注
68文章
19349浏览量
230310 -
开发
+关注
关注
0文章
370浏览量
40872 -
volatile
+关注
关注
0文章
45浏览量
13039
发布评论请先 登录
相关推荐
Volatile变量的使用
什么是volatile
c语言volatile的作用
Volatile与多线程的认识与理解
volatile修饰的变量的认识和理解

Java中volatile的作用以及用法
volatile变量定义的意义和该用在哪里

C语言类型修饰符Volatile的使用说明
如何使用C++语法中的volatile
C++基础语法之volatile、assert()和sizeof()
【嵌入式】C语言中volatile关键字

Volatile关键字在嵌入式开发中的应用
volatile的原理





 工商网监
工商网监
评论