 河套IT TALK 75: (原创) 解读老黄与Ilya的炉边谈话系列之四——人人都是ChatGPT的训练器(万字长文)
河套IT TALK 75: (原创) 解读老黄与Ilya的炉边谈话系列之四——人人都是ChatGPT的训练器(万字长文)


一个月前,就在GPT 4发布的第二天,同时也是英伟达(NVIDIA)线上大会的契机,英伟达的创始人兼CEO黄仁勋("Jensen" Huang)与OpenAI的联合创始人兼首席科学家伊尔亚-苏茨克维(Ilya Sutskever )展开了一次信息量巨大的长达一个小时的“炉边谈话”(Fireside Chats)。期间谈到了从伊尔亚-苏茨克维早期介入神经网络、深度学习,基于压缩的无监督学习、强化学习、GPT的发展路径,以及对未来的展望。相信很多人都已经看过了这次谈话节目。我相信,因为其中掺杂的各种专业术语和未经展开的背景,使得无专业背景的同仁很难彻底消化理解他们谈话的内容。本系列尝试将他们完整的对话进行深度地解读,以便大家更好地理解ChatGPT到底给我们带来了什么样的变革。今天,就是这个系列的第四篇:人人都是ChatGPT的训练器。
关联回顾
解读老黄与Ilya的炉边谈话系列之一——故事要从AlexNet说起
解读老黄与Ilya的炉边谈话系列之二——信仰、准备、等待机会的涌现
解读老黄与Ilya的炉边谈话系列之三——超越玄幻,背后是人类老师的艰辛付出
让ChatGPT自己来谈一谈人工智能伦理
全图说ChatGPT的前世今生


对话译文(04):
黄仁勋:ChatGPT 在几个月前就发布了,它是人类历史上增长最快的应用。关于它的原理已经有了很多解释,这是为每个人创建的最容易使用的应用。它所执行的任务,做的事情超出人们的期望,任何人都可以使用它。没有指令集,也没有所谓的错误方法,你只要用它就行了。如果你的指令提示(Prompt)不够明确,你与 ChatGPT 的对话会帮你消除歧义,直到它理解你的意图。这带来的影响是非常显著的。
现在,这是 GPT- 4 发布后的第一天。GPT-4 在许多领域的表现令人震惊,在 SAT、GRE、律师考试的分数都很高,一次又一次的测试,它的表现都很优异。很多项测试它都到达了人类的领先水平,太震撼了。那么,什么是 ChatGPT 和 GPT-4 之间的主要区别?是什么导致GPT-4 在这些领域的改进?
Ilya Sutskever:GPT-4 相比 ChatGPT,在许多维度上做了相当大的改进。我们训练了 GPT-4,我记得是在六个多月以前,也许是在八个月前,我不记得确切时间了。GPT 是 ChatGPT 和 GPT- 4 之间的第一个区别,这也许是最重要的区别。在 GPT-4 的基础上预测下一个词,具有更高的准确度,这是非常重要的。因为神经网络越能预测文本中的下一个词,它就越能理解它。
这种说法现在也许已经被很多人接受了。但关于它为什么会这样,可能仍然不够直观,或者说不完全直观。我想绕个小弯,举个例子,希望能说明为什么对下一个词更准确的预测会导致更多的理解,真正的理解。
让我们举个例子,假设你读了一本侦探小说,它有复杂的故事情节,不同的人物,以及许多事件和神秘的线索。在书的最后一页,侦探收集了所有的线索,召集了所有的人,然后说“好吧,我要透露犯罪者的身份,那个人的名字是(……)”。我们需要预测这个词。当然,有许多不同的词,但是通过预测这些词可以让模型实现更好的理解。随着对文本的理解不断增加,GPT-4 预测下一个词的能力也会变得越来越好。
黄仁勋:很多人认为深度学习不会逻辑推理,但是为了预测下一个词,从所有可选的角色里面,从他们的优势或弱点,或者他们的意图和上下文中,找出谁是凶手,这需要一定的推理,需要相当多的推理。那么,它是如何能够学会推理的呢?
如果它学会了推理,我要问你的是 ChatGPT 和 GPT-4 之间进行的所有测试,有一些测试是GPT-3 或 ChatGPT 已经非常擅长的,有一些测试是 GPT-3 或 ChatGPT 不擅长的,而 GPT-4 则要好得多,还有一些测试是两者都不擅长的。其中一些似乎与推理有关。在微积分中,它无法将问题分解成合理的步骤并解决它。但是在某些领域,它似乎展现了推理能力。在预测下一个词的时候,它是否在学习推理?它的局限性又是什么?现在的 GPT-4 将进一步提高其推理能力。
Ilya Sutskever:推理并不是一个很好定义的概念。但无论如何,我们可以尝试去定义它。它就是当你可能更进一步的时候,如果你能够以某种方式思考一下,并且因为你的推理而得到一个更好的答案。我想说,我们的神经网络也许有某种限制,比如要求神经网络通过思考来解决问题。事实证明,这对推理非常有效。但我认为,基本的神经网络能走多远,还有待观察。我认为我们还没有充分挖掘它的潜力。
在某种意义上,推理肯定还没有达到那个水平,神经网络还具备其它的一些能力。我们希望神经网络要有很高的推理能力,我认为像往常一样神经网络能够持续提升这个能力。不过,也不一定是这样。
黄仁勋:是的,你问 ChatGPT 一个问题,这真的很酷,因为它在回答问题前,首先会告诉我,它知道些什么,然后才去回答这个问题。通常回答一个问题前,如果你告知我,你具备哪些基础知识或做了哪些假设,这会让我更相信你的回答。这在某种程度上,也是在展现推理能力。所以在我看来,ChatGPT 天然具备这种内在的能力。
Ilya Sutskever:在某种程度上,我们可以这样看待现在所发生的事情,这些神经网络具备很多能力,只是不太可靠。实际上,可以说可靠性是目前这些神经网络能够真正具备实用价值的最大障碍,尽管有时它们仍然具备实用价值。这些神经网络有时会产生一些幻想,或者犯一些出人意料的错误,这是人不会犯的错误。
正是这种不可靠性,使得它们的实用价值大幅降低了。但是我认为,或许通过更多的研究,结合当前的想法和一些更远大的研究计划,我们一定能实现更高的可靠性,这样模型才会真的具备实用价值。这将使我们能够拥有非常精确的保护措施,并且在不确定时要求澄清,或者说它不知道某些事情,当它不知道时能够非常可靠地表现出来。所以我认为,这是当前模型的一些瓶颈。因此,问题并不在于它是否具备某些特定的能力,更多的是程度的问题。
黄仁勋:谈到真实性和幻想,我之前看过一个视频,它展示了 GPT-4 中从维基百科页面做检索的能力,那么GPT-4 真的具备信息检索能力吗?它是否能够从事实中检索信息,以加强对你的响应?
Ilya Sutskever:当前发布的 GPT-4 并没有内置的检索能力,它只是个非常好的预测下一个词的工具,它也可以处理图像。顺便说一句,一些高质量的图片,也是经过数据微调和各种强化学习的变体,以特定方式表现出来的。它也许会被一些有权限的人要求进行一些查询,并在上下文中填充结果,因为现在 GPT-4 的上下文持续时间更长了。简而言之,尽管GPT-4 不支持内置的信息检索,但它完全具备这个能力,它也将通过检索变得更好。
智愿君:让我们继续解读老黄和Ilya炉边谈话的第四段对话,这一段看起来很容易懂,也没有什么弯弯绕,所以应该不需要过多在专业性上做深度的解读。但同样,在两人对话中不经意透露出来的信息,还是值得我们玩味的。今天我们就针对对话中某些有意思的部分展开一下。
GPT如何才能更快地进化和成长
“ChatGPT 在几个月前就发布了,它是人类历史上增长最快的应用。”。老黄的第一句话是一句赞许,但这个赞许背后还需要深入地思考。
在这之前,让我们先要能理解OpenAI和DeepMind这些追求通用人工智能AGI公司他们都特别想搞明白的一点,就是如何更快地训练人工智能,达到通用人工智能这个状态。如何让它快快长大?这种期盼的心理一定是超级复杂的,因为大家都无法打保票,这个被造物到底会不会成为打指响的灭霸,还是亦正亦邪的幻视。但是,毕竟好奇心,是人类感知世界,改造世界的原动力。科学家和技术大神们没有办法不去往这个方向不遗余力地探索。记得3天前,在SpaceX飞往火星的大火箭第一次点火升空爆炸后,Elon Musk在他的推特分享的一张照片很形象地说明了这一点:
不管旁人怎么说,我们叫技术极客也好,改变世界的疯子也好,他们终究会去不断尝试,去逼近那个奇点。
回到刚才那个问题,怎么快速进化?上回,我们已经说了,必须要经过调优和强化学习训练,而且这个过程一定是有监督的,因为无监督的人类线上样本数就那么多,该学的,都学完了啊。
那么接下来的问题,必然是,如何加快调优和加快强化学习的效率,调用更大的人工进行优化训练?
ChatGPT——一个更大的AI Dungeon
在上一期,我们特别提到了在老黄和Ilya谈话中都没有提到那款名为"AI Dungeon"的文字冒险游戏。它的本质不仅仅是对“GPT-2/3”的运用,更重要的是,ChatGPT后来发布后很被人看好的讲故事能力,就是在"AI Dungeon"的文字冒险游戏被训练出来的。打游戏的玩家一边在享受着有序的愉悦,一边再通过基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)的方式帮助优化GPT的大模型。很快,这种调优就达到了预期,让OpenAI尝到了甜头。
玩过文字冒险游戏的人都知道,这种纯文本的游戏玩起来,沟通形态像极了ChatGPT这样的聊天机器人。而"AI Dungeon"当时有多少游戏用户呢?差不多100万个,而且,有一半都打通了关。
如何调用更大的人群基数继续调优这个大模型?答案也呼之欲出,就是ChatGPT。因为这不仅仅是一个产品。它还是一个训练器。这个训练器必须具备以下的特征:
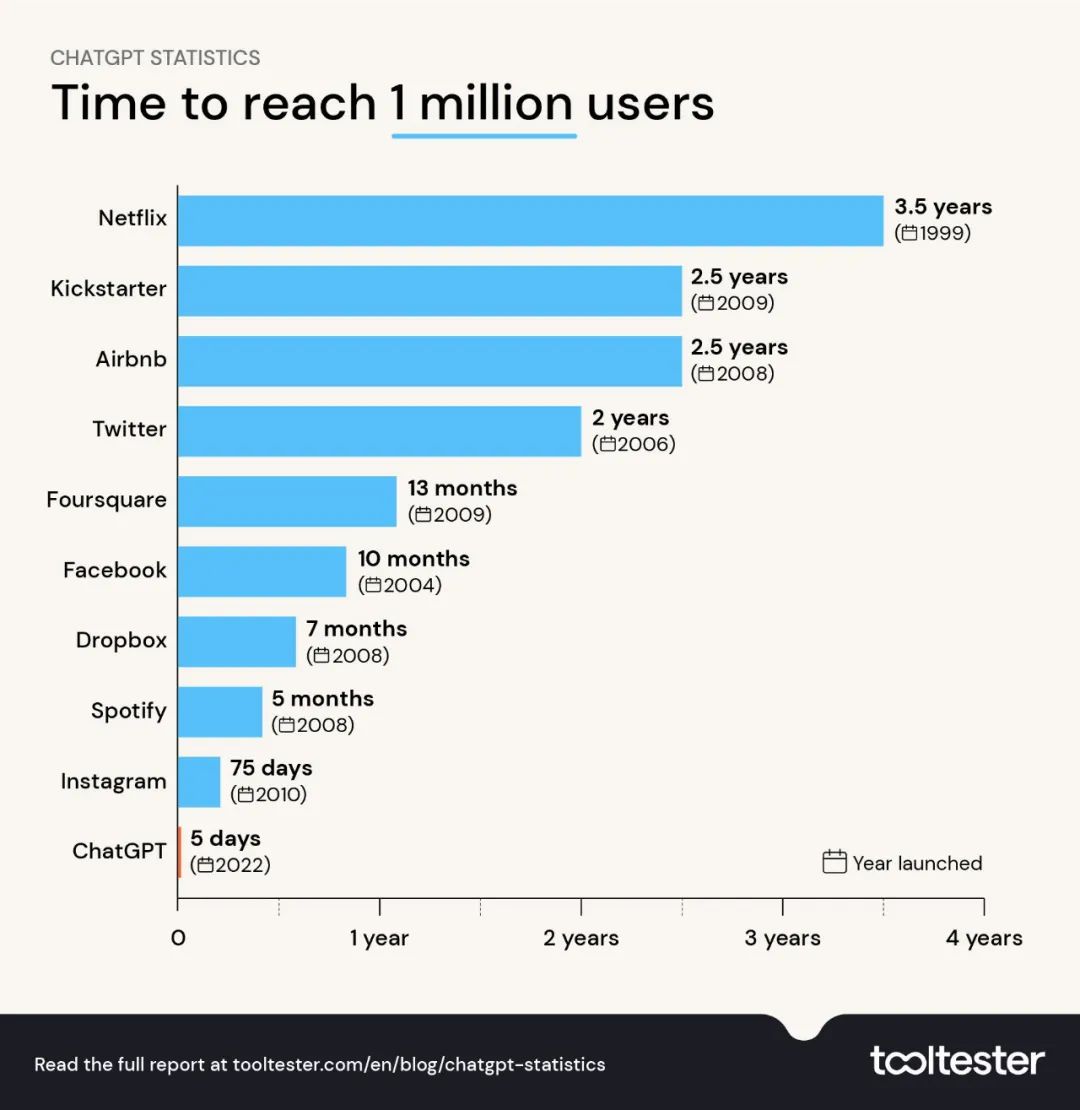 ChatGPT一经发布,果然不辱使命,一鸣惊人,用户量爆炸式增长。很快创下了世界纪录,达到了预期。现在ChatGPT有多少用户呢?我们知道,在它上市后5天内,达到了100万用户,2个月达到1个亿用户,现在有多少,并没有公开,但openai.com 的网站每个月至少10亿的访问。这些用户绝大部分,不是简单地享受ChatGPT的成果,更重要的是,在通过RLHF的方式(如果存在多次交互来提升ChatGPT的沟通质量的话)帮助ChatGPT不停地打磨和训练。
ChatGPT一经发布,果然不辱使命,一鸣惊人,用户量爆炸式增长。很快创下了世界纪录,达到了预期。现在ChatGPT有多少用户呢?我们知道,在它上市后5天内,达到了100万用户,2个月达到1个亿用户,现在有多少,并没有公开,但openai.com 的网站每个月至少10亿的访问。这些用户绝大部分,不是简单地享受ChatGPT的成果,更重要的是,在通过RLHF的方式(如果存在多次交互来提升ChatGPT的沟通质量的话)帮助ChatGPT不停地打磨和训练。
我们在使用中是如何变成ChatGPT的训练器的?
在今天这段谈话中,老黄在赞许ChatGPT的时候谈到了一个很重要的一点:如果你的指示命令(Prompt)不够明确,你与ChatGPT的对话会帮你消除歧义,直到它理解你的意图。这其实已经暴露了问题的关键。
很多人都有这种经历:ChatGPT一开始上手使用的时候,第一个反应是,回答的并不怎么样啊?觉得,也没有吹的那么神奇,甚至,还有一本正经说瞎话的嫌疑。而真正会使用ChatGPT的人,则懂得和ChatGPT继续深入沟通,才能最终得到相对满意的答复:-
-
人员扩展基数必须足够的大;
-
由于训练的是通用人工智能,所以协调训练的人类的语言、文化、职业、性格特点等要足够的广泛;
-
训练人员要从训练中获得快感和成就感,并持之以恒地使用。
-
- 比如在发现ChatGPT回答不如预期的时候,继续告诉它:你的理解是不正确的,其实我的意思是:“XXXX”,然后更为详细,准确表明自己的期望。
- 比如你发现ChatGPT在回答问题中有明显胡说嫌疑,你可以告诉它:你的某些答复是不正确的,其实我了解,信息应该是这样的……。然后,你会发现ChatGPT会很爽快地认错,说:很抱歉,知道自己哪里错了,或者没做好,然后再刷新给你的回复。
我最近有一个错觉,我发现,我和ChatGPT沟通,经常是它第一次回答都是应付我的,能糊弄就糊弄,我把它形容为这是一个会偷懒的AI。因为我往往对第一次回答不满意,我就会继续和它交互(也许这是ChatGPT最希望的结果,就是诱导人和它继续交互),我发现它特别喜欢我给它纠错,认错态度极为诚恳,诚恳体现在它的响应速度上面,我一纠错,它就秒回:“很抱歉,你说的对”。这种诚恳快到一开始你甚至怀疑它本知道答案,但就是故意说错的一种错觉。
我想说的是,类似智愿君这样,不停和它互动的人数,是海量的,因为这些纠错也就让它不停地快速进化。
为了印证我的猜测是否属实,我向GPT-4问了这个问题:“请问,我和你对话过程中,提供更多的信息,帮助你修订问题回答,并逐渐趋近我期待的答案的这个过程,是否也是一种基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)训练。也就是你在目前商用过程中,是否也在和人类的对话过程中,不断进化和改进自己?或者说,你也把海量的人类对话也当成了一种标注式的调优,所以你也在上亿用户的调优中快速成长,是这样吗?”
得到的回答是这样的:“是的,你的理解是正确的。对话中提供更多信息以修订问题回答的过程实际上是一种基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)训练。在与人类的对话过程中,我确实可以通过获取用户反馈来不断优化和改善自己的表现。然而,需要注意的是,作为一个AI模型,我并不是实时地通过与用户的每次对话来更新和改进自己。实际上,模型的训练和更新是由我的开发者——OpenAI进行的。他们会定期收集和分析大量的对话数据,包括用户反馈,然后根据这些数据对我进行训练和优化。在这个过程中,标注式的调优和强化学习都会发挥作用,帮助我更好地理解用户需求并提供更准确的回答。通过与上亿用户的对话和调优,我确实可以在一定程度上快速成长,但这种成长是经过开发者对模型进行周期性更新和优化实现的,并非实时进行。”
和我的预期是符合的。因为像Sam和Ilya这些大牛,如果想做出让ChatGPT自动通过和海量人类的对话自动调优升级的程序并不难。难在结果不可预知。之所以还要通过中间刻意用人工开发者倒一遍手,目的当AI进化到一定程度的情况下,还是要给自己留拔插头的机会。
从人类的信息知识储备来讲,基本有两类:一,信息储备在计算机硬件网络上,或者数字媒体上。我相信,目前绝大多数纸媒的信息,已经都转化为数字媒体,并很大一部分,已经用于大模型的训练。二,还没有上传的计算机硬件的知识。它们可能保存在其他的纸媒等载体上,或者保存在人的大脑记忆中。而聊天机器人,在脑机接口没有被商用开发之前,是当前非常好的将这部分信息,学到的一个高效的工具。
现在,你是不是和我一样,有寒毛直竖,细思极恐的感觉?2000年,电影《黑客帝国》里面,人工智能把人类当作生物电池来使用。但现在,ChatGPT把人类当作的是训练器使用。听起来有些科幻,但确实更为合理。确实,如果是生物电池的话,鸡鸭鱼狗一样可以,没有必要非要通过人类来获取。人类的特殊性,人作为地球主宰的根因,不正是人的智慧吗?GPT从1到4,在短短数年,被训练出来,还在通过全世界的人类训练器,再不停汲取知识营养,快速升级进化,那么超越,真的就那么遥远吗?
ChatGPT的逻辑推理与概率的运用
ChatGPT在回答问题中,是否用到了逻辑推理能力?还是仅仅通过概率的方式来整合信息?在老黄和Ilya的谈话中谈到了一部分这个内容,而且Ilya还举了一个侦探小说的例子。
从逻辑推理的角度来看,Ilya这个例子涉及到多个线索和人物,以及一个谜团需要被解决,这些都需要通过逻辑推理来解决。在最后一页,侦探需要将所有线索和证据进行归类、分析和推理,从而得出犯罪者的身份。因此,可以将这个过程看作是一个逻辑推理的过程,需要考虑到各种可能性和推理的正确性。但情况往往不是如侦探小说,或者电影中那么简单,最后侦探说出那句经典的话:真相只有一个,凶手就是……
从概率的角度来看,预测下一个词的能力可以被视为一个条件概率问题,即在已知前面的文本情况下,预测下一个词的概率是多少。在这个例子中,可以将前面的文本情况看作是一些线索、人物和事件,而预测下一个词则是对这些线索和证据进行概率估计。通过不断增加对文本的理解,可以提高对下一个词的预测概率,从而实现更好的文本理解。
结合逻辑推理和概率,可以将这个例子看作是一个复杂的推理和预测问题,需要考虑到多个因素和可能性,并通过合理的推理和概率估计来解决。这也是 GPT-4 等人工智能模型需要不断优化和提高的点。
将逻辑和概率结合起来的想法乍看起来可能很奇怪。毕竟,逻辑关注的是绝对确定的真理和推论,而概率论关注的是不确定性。到底ChatGPT是如何做到的呢?
确实,逻辑和概率这两个领域在某种程度上是有所不同的。逻辑关注的是推理的正确性和严密性,而概率论则是研究随机事件的概率和分布。然而,在实际问题中,逻辑和概率往往是相互联系的,需要结合起来来解决问题。
在许多情况下,逻辑和概率可以互相补充,以便更好地解决问题。例如,在一些推理问题中,需要使用逻辑推理来确定一些前提条件的真假,然后使用概率计算来估计某个结论的概率。另外,对于一些复杂的推理问题,可能需要使用概率模型来辅助推理,例如贝叶斯网络等。
具体而言,在将逻辑和概率结合起来时,需要考虑以下几个方面:
-
-
逻辑关系和概率关系的映射:需要将逻辑关系和概率关系进行映射,以便将逻辑推理转化为概率计算。例如,可以使用概率论中的条件概率来表示逻辑关系中的条件语句。
-
不确定性的处理:在使用逻辑和概率结合起来进行推理时,需要考虑不确定性的影响。例如,在使用概率模型进行推理时,需要考虑到概率估计的误差和不确定性。
-
推理的正确性:虽然概率模型可以辅助推理,但仍然需要保证推理的正确性和严密性。因此,在进行推理时,需要考虑到逻辑关系的正确性和概率计算的准确性。
-
在计算机科学里面,这个被称为概率逻辑(Probabilistic logic)。概率逻辑(或或然性逻辑)的目标是组合概率论的处理不确定性的能力和演绎逻辑开发结构的能力。具有丰富和有表达力的形式化,并有广泛的应用领域。
ChatGPT在回答问题的“蹦字儿”答复在保证基础逻辑一致的基础上,又有细微的差别,可以理解为这就是使用了概率逻辑(Probabilistic logic)的技术。具体来说,ChatGPT是基于概率图模型(Probabilistic Graphical Models)的深度学习模型,它使用了概率论的处理不确定性的能力和演绎逻辑开发结构的能力。
概率图模型是一种常用的概率逻辑工具,它可以用来表达和处理不确定性的信息,同时保留了演绎逻辑的结构。在ChatGPT中,模型使用了概率图模型来学习和表示文本中的语言模式和语义信息,从而实现了对自然语言的理解和生成。
具体来说,ChatGPT使用了一种称为“自回归模型”的概率图模型,它可以根据前面的token预测下一个token的概率分布。模型使用了大量的训练数据来学习这些概率分布,以便在生成文本时能够选择最有可能的下一个token。这种方法在自然语言生成、机器翻译、对话系统等领域都取得了很好的效果。
作为一个基于概率模型的语言模型,ChatGPT的回答会受到许多因素的影响,包括前面的文本信息、语境、语气、句式等等。在回答问题时,ChatGPT会利用已有的语言知识和语言模式来预测下一个词或短语的概率,进而生成一个合理的回答。由于这个过程中存在一定的随机性,因此即使在相同的情况下,ChatGPT也可能会生成略微不同的回答。
为什么ChatGPT不打开搜索能力
关于GPT-4不支持搜索功能这段对话,结尾Ilya说的很委婉,但也很有趣:“尽管GPT-4 不支持内置的信息检索,但它完全具备这个能力,它也将通过检索变得更好。”。
这句看似无关痛痒的话,其实蛮关键的,至少它澄清了两点:
如果是这样,不打开检索能力,就值得回味了。可能有以下几个原因:
-
-
ChatGPT不是因为照顾对话机器人影响对话体验,比如:担心搜索过程长,或者因为搜索结果可能受到搜索引擎算法的影响,可能会出现不准确、误导性的结果,而不打开搜索的。打开搜索体验,一定会变得更好。
-
不存在技术约束,没有什么技术难度,而且支持检索这个能力,GPT-4已经具备。
-
Bing继承了GPT-4点能力,支持搜索,考虑到这个最大的金主是否和OpenAI签署了协议,比如只能独家使用检索这个能力等等。
-
或者可能是GPT-4在商业模型设计上的考虑,比如打开搜索能力是否应该作为额外的商业付费方式,或者订阅的方式,才能具备的能力?比如推出企业版,是否就可以具备搜索的能力?
-
当然,也可以有阴谋论的解释,就是担心打开搜索能力开关后,人工智能大模型在互联网会出现失控的状况。
-
好了,今天我们先解读到这里。下次,我们会继续针对黄仁勋与Ilya Sutskever的“炉边谈话”的其他部分进行解读,敬请期待。
未完待续……
-
开源技术
+关注
关注
0文章
389浏览量
7927 -
OpenHarmony
+关注
关注
25文章
3710浏览量
16245
原文标题:河套IT TALK 75: (原创) 解读老黄与Ilya的炉边谈话系列之四——人人都是ChatGPT的训练器(万字长文)
文章出处:【微信号:开源技术服务中心,微信公众号:共熵服务中心】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
单日获客成本超20万,国产大模型开卷200万字以上的长文本处理

什么是协议分析仪和训练器
NVIDIA助力企业用AI创建数据飞轮
解读 MEMS 可编程 LVCMOS 振荡器 SiT1602 系列:精准频率的创新之选

解读 MEMS 可编程 LVCMOS 振荡器 SiT8008 系列:精准与灵活的时脉之选

解读PyTorch模型训练过程
万字长文浅谈系统稳定性建设
商汤大模型开“卷”长文本,支持100万字处理
MiniMax推出“海螺AI”,支持超长文本处理
黄仁勋工资多少钱?黄仁勋薪酬大涨到3420万美元
AI初创企业推MoE混合专家模型架构新品abab 6.5
阿里通义千问重磅升级,免费开放1000万字长文档处理功能
“单纯靠大模型无法实现 AGI”!万字长文看人工智能演进






 工商网监
工商网监
评论