 深度剖析Linux中进程控制(上)
深度剖析Linux中进程控制(上)
一、进程创建
fork函数初识
在Linux中,fork函数是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
返回值:
在子进程中返回0,父进程中返回子进程的PID,子进程创建失败返回-1。
进程调用fork,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给子进程。
- 将父进程部分数据结构内容拷贝至子进程。
- 添加子进程到系统进程列表当中。
- fork返回,开始调度器调度。
fork之后,父子进程代码共享。例如:
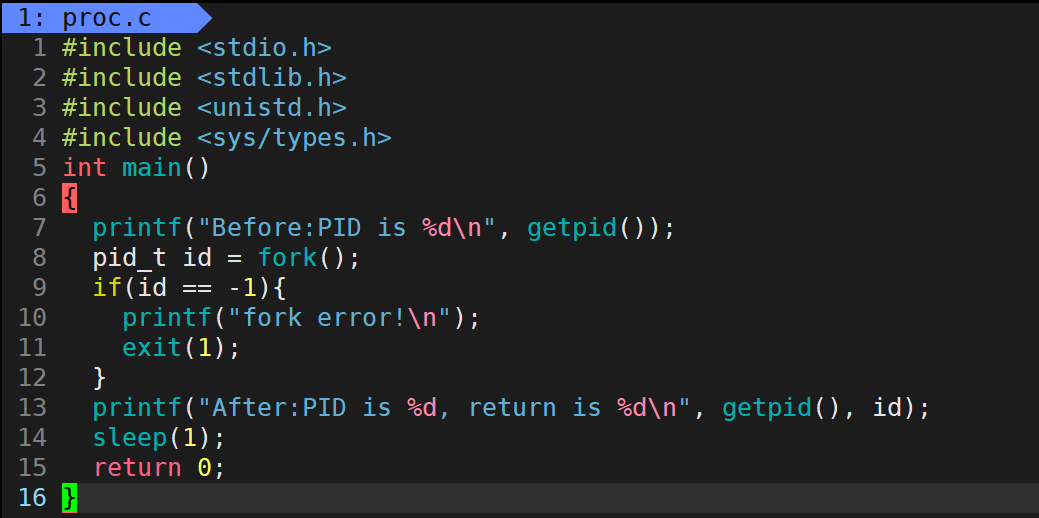
运行结果如下:
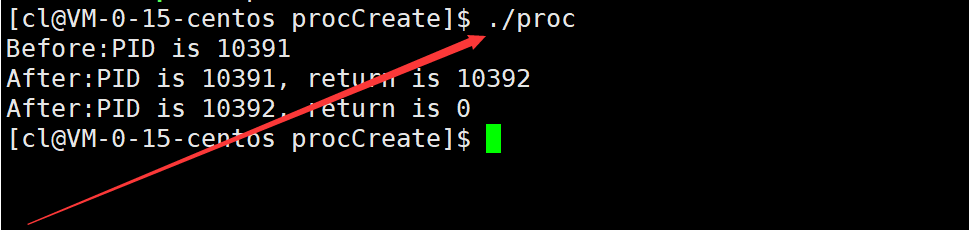
这里可以看到,Before只输出了一次,而After输出了两次。其中,Before是由父进程打印的,而调用fork函数之后打印的两个After,则分别由父进程和子进程两个进程执行。也就是说,fork之前父进程独立执行,而fork之后父子两个执行流分别执行。
注意: fork之后,父进程和子进程谁先执行完全由调度器决定。
fork函数返回值
fork函数为什么要给子进程返回0,给父进程返回子进程的PID?
一个父进程可以创建多个子进程,而一个子进程只能有一个父进程。因此,对于子进程来说,父进程是不需要被标识的;而对于父进程来说,子进程是需要被标识的,因为父进程创建子进程的目的是让其执行任务的,父进程只有知道了子进程的PID才能很好的对该子进程指派任务。
为什么fork函数有两个返回值?
父进程调用fork函数后,为了创建子进程,fork函数内部将会进行一系列操作,包括创建子进程的进程控制块、创建子进程的进程地址空间、创建子进程对应的页表等等。子进程创建完毕后,操作系统还需要将子进程的进程控制块添加到系统进程列表当中,此时子进程便创建完毕了。

也就是说,在fork函数内部执行return语句之前,子进程就已经创建完毕了,那么之后的return语句不仅父进程需要执行,子进程也同样需要执行,这就是fork函数有两个返回值的原因。
写时拷贝
当子进程刚刚被创建时,子进程和父进程的数据和代码是共享的,即父子进程的代码和数据通过页表映射到物理内存的同一块空间。只有当父进程或子进程需要修改数据时,才将父进程的数据在内存当中拷贝一份,然后再进行修改。
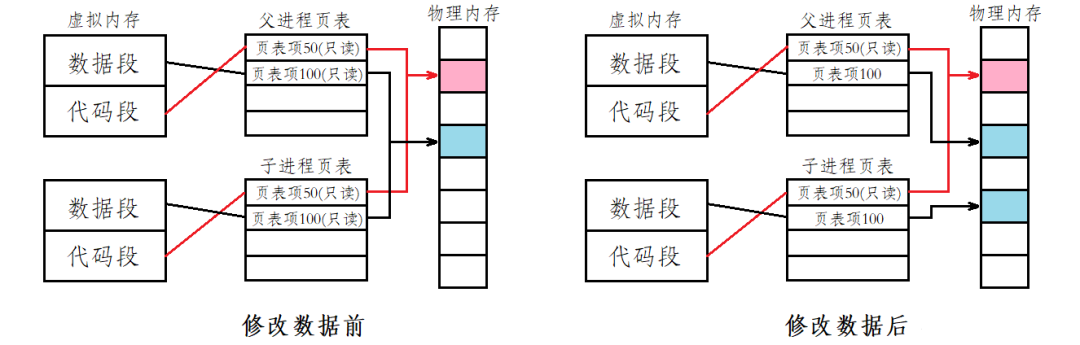
这种在需要进行数据修改时再进行拷贝的技术,称为写时拷贝技术。
1、为什么数据要进行写时拷贝?
进程具有独立性。多进程运行,需要独享各种资源,多进程运行期间互不干扰,不能让子进程的修改影响到父进程。
2、为什么不在创建子进程的时候就进行数据的拷贝?
子进程不一定会使用父进程的所有数据,并且在子进程不对数据进行写入的情况下,没有必要对数据进行拷贝,我们应该按需分配,在需要修改数据的时候再分配(延时分配),这样可以高效的使用内存空间。
3、代码会不会进行写时拷贝?
90%的情况下是不会的,但这并不代表代码不能进行写时拷贝,例如在进行进程替换的时候,则需要进行代码的写时拷贝。
fork常规用法
- 一个进程希望复制自己,使子进程同时执行不同的代码段。例如父进程等待客户端请求,生成子进程来处理请求。
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败的原因
fork函数创建子进程也可能会失败,有以下两种情况:
- 系统中有太多的进程,内存空间不足,子进程创建失败。
- 实际用户的进程数超过了限制,子进程创建失败。
二、进程终止
进程退出场景
进程退出只有三种情况:
- 代码运行完毕,结果正确。
- 代码运行完毕,结果不正确。
- 代码异常终止(进程崩溃)。
进程退出码
我们都知道main函数是代码的入口,但实际上main函数只是用户级别代码的入口,main函数也是被其他函数调用的,例如在VS2013当中main函数就是被一个名为__tmainCRTStartup的函数所调用,而__tmainCRTStartup函数又是通过加载器被操作系统所调用的,也就是说main函数是间接性被操作系统所调用的。
既然main函数是间接性被操作系统所调用的,那么当main函数调用结束后就应该给操作系统返回相应的退出信息,而这个所谓的退出信息就是以退出码的形式作为main函数的返回值返回,我们一般以0表示代码成功执行完毕,以非0表示代码执行过程中出现错误,这就是为什么我们都在main函数的最后返回0的原因。
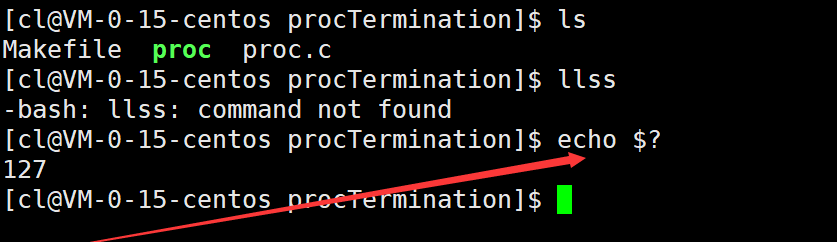
当我们的代码运行起来就变成了进程,当进程结束后main函数的返回值实际上就是该进程的进程退出码,我们可以使用echo $?命令查看最近一次进程退出的退出码信息。
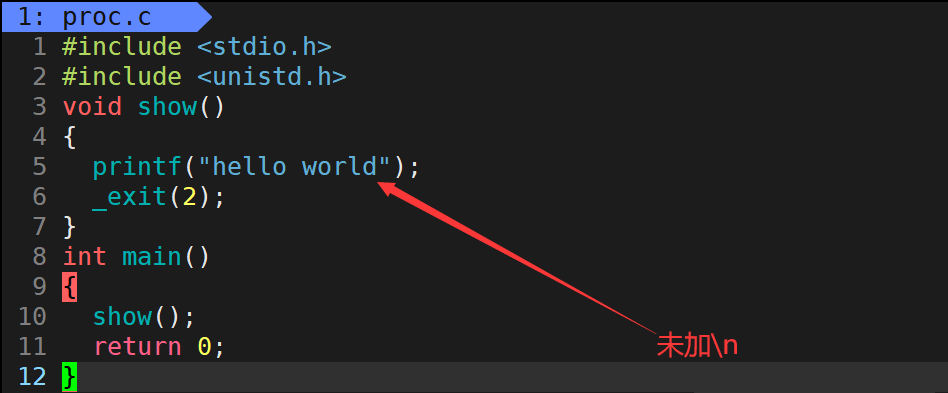
例如,对于下面这个简单的代码:
代码运行结束后,我们可以查看该进程的进程退出码。
[cl@VM-0-15-centos procTermination]$ echo $?
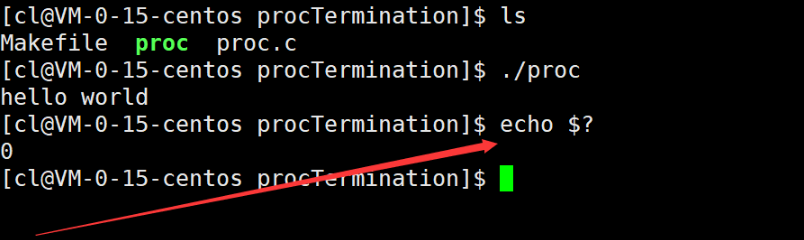
这时便可以确定main函数是顺利执行完毕了。
为什么以0表示代码执行成功,以非0表示代码执行错误?
因为代码执行成功只有一种情况,成功了就是成功了,而代码执行错误却有多种原因,例如内存空间不足、非法访问以及栈溢出等等,我们就可以用这些非0的数字分别表示代码执行错误的原因。
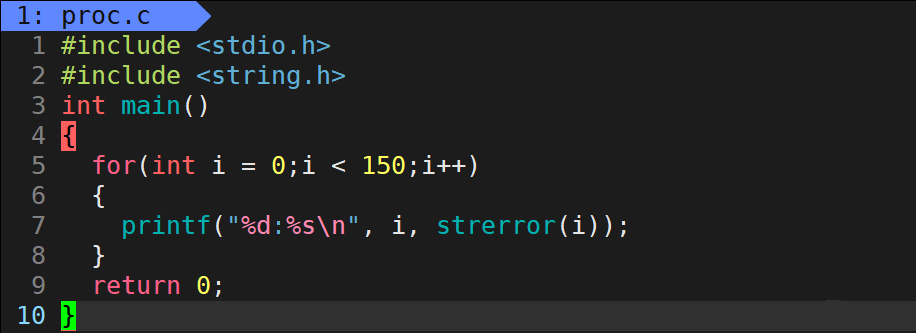
C语言当中的strerror函数可以通过错误码,获取该错误码在C语言当中对应的错误信息:
运行代码后我们就可以看到各个错误码所对应的错误信息:
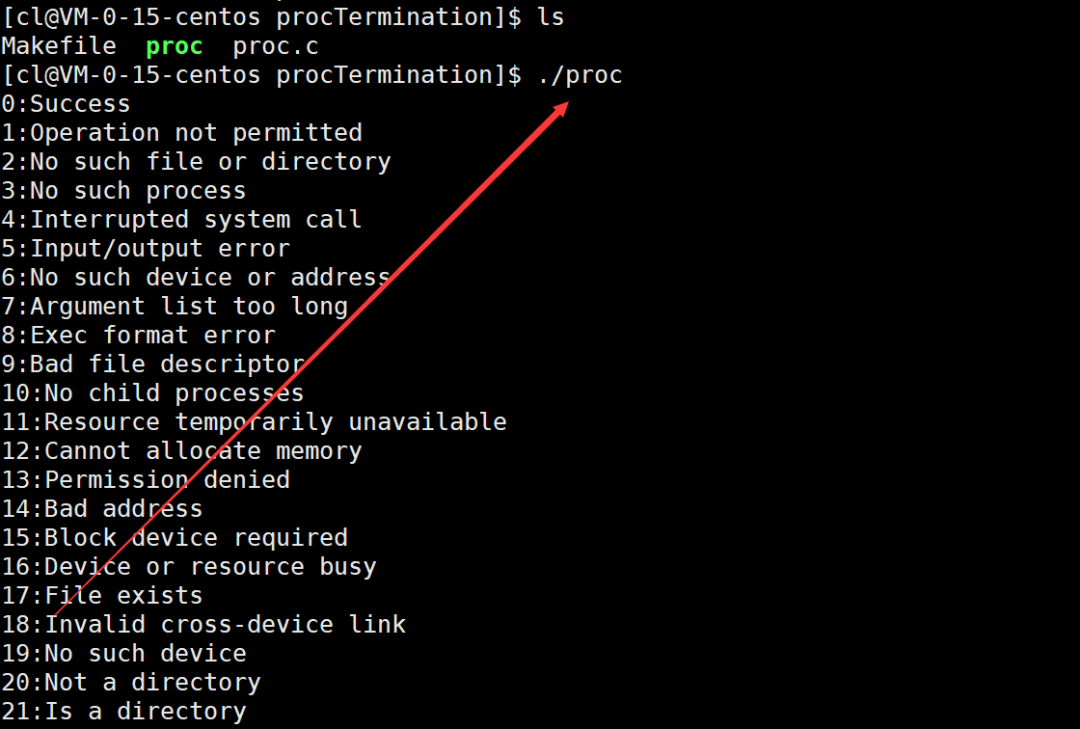
实际上Linux中的ls、pwd等命令都是可执行程序,使用这些命令后我们也可以查看其对应的退出码。
可以看到,这些命令成功执行后,其退出码也是0。
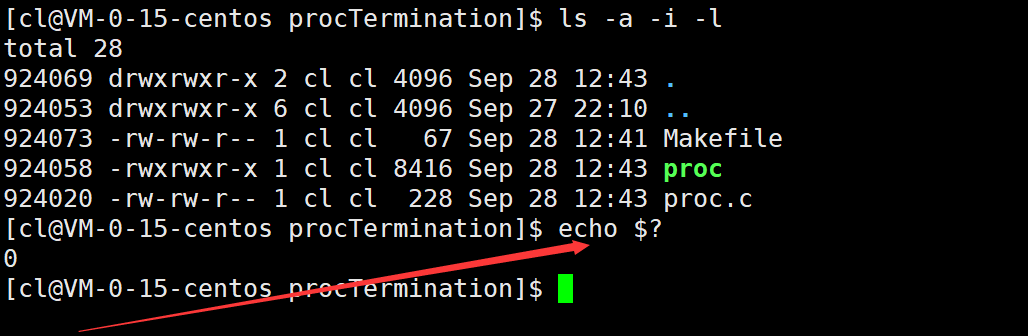
但是命令执行错误后,其退出码就是非0的数字,该数字具体代表某一错误信息。
注意: 退出码都有对应的字符串含义,帮助用户确认执行失败的原因,而这些退出码具体代表什么含义是人为规定的,不同环境下相同的退出码的字符串含义可能不同。
进程正常退出
return退出
在main函数中使用return退出进程是我们常用的方法。
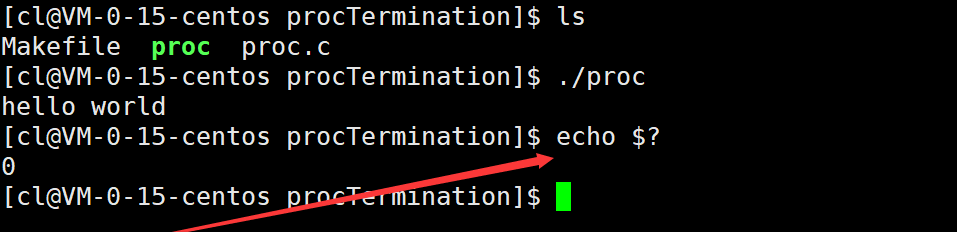
例如,在main函数最后使用return退出进程。
运行结果:
exit函数
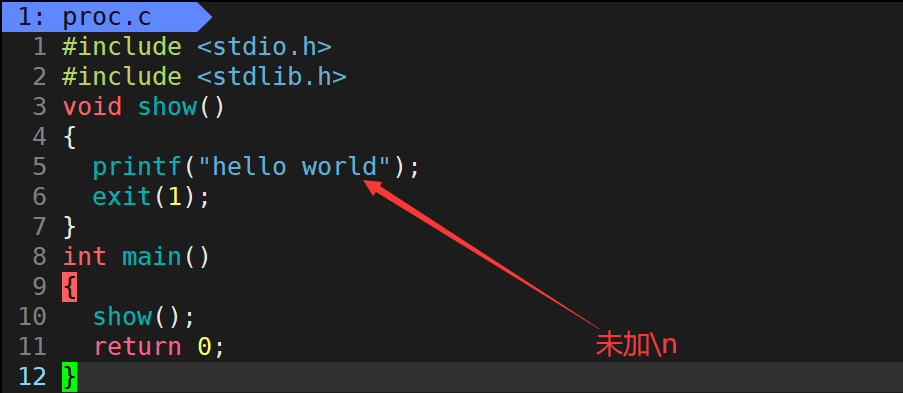
使用exit函数退出进程也是我们常用的方法,exit函数可以在代码中的任何地方退出进程,并且exit函数在退出进程前会做一系列工作:
- 执行用户通过atexit或on_exit定义的清理函数。
- 关闭所有打开的流,所有的缓存数据均被写入。
- 调用_exit函数终止进程。
例如,以下代码中exit终止进程前会将缓冲区当中的数据输出。
运行结果:
_exit函数
使用_exit函数退出进程的方法我们并不经常使用,_exit函数也可以在代码中的任何地方退出进程,但是_exit函数会直接终止进程,并不会在退出进程前会做任何收尾工作。
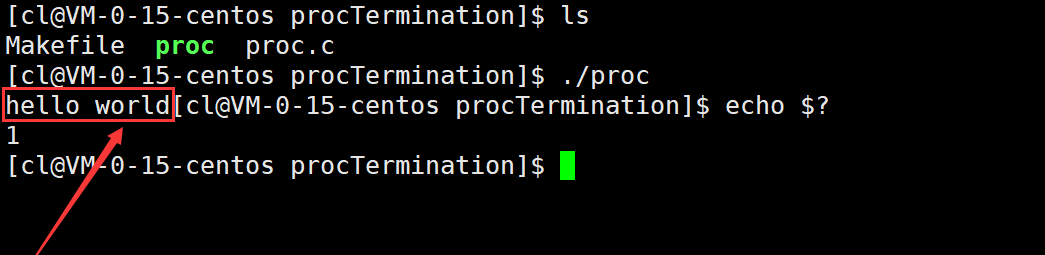
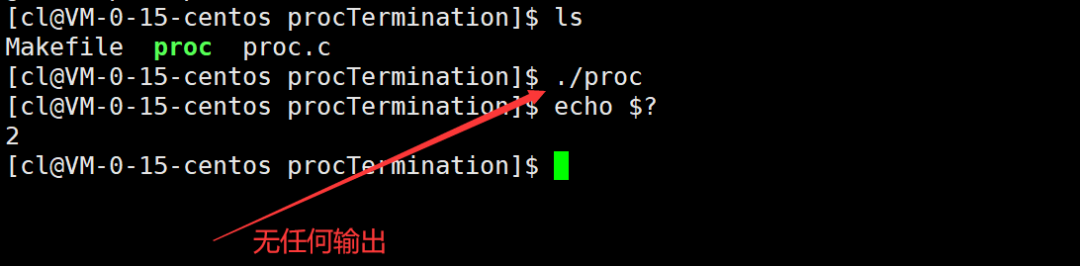
例如,以下代码中使用_exit终止进程,则缓冲区当中的数据将不会被输出。
运行结果:
return、exit和_exit之间的区别与联系
return、exit和_exit之间的区别
只有在main函数当中的return才能起到退出进程的作用,子函数当中return不能退出进程,而exit函数和_exit函数在代码中的任何地方使用都可以起到退出进程的作用。
使用exit函数退出进程前,exit函数会执行用户定义的清理函数、冲刷缓冲,关闭流等操作,然后再终止进程,而_exit函数会直接终止进程,不会做任何收尾工作。
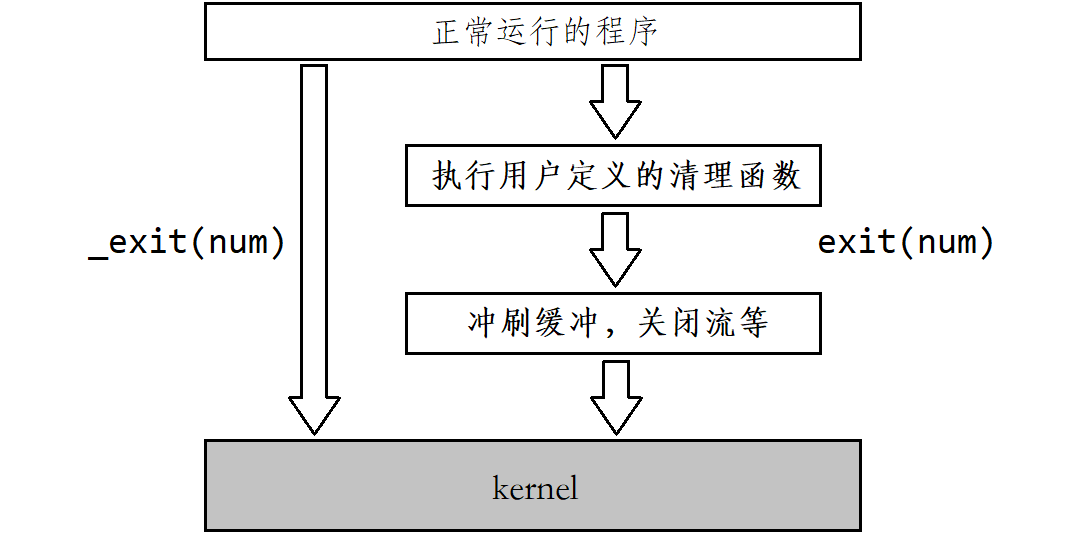
return、exit和_exit之间的联系
执行return num等同于执行exit(num),因为调用main函数运行结束后,会将main函数的返回值当做exit的参数来调用exit函数。

使用exit函数退出进程前,exit函数会先执行用户定义的清理函数、冲刷缓冲,关闭流等操作,然后再调用_exit函数终止进程。
进程异常退出
情况一:向进程发生信号导致进程异常退出。
例如,在进程运行过程中向进程发生kill -9信号使得进程异常退出,或是使用Ctrl+C使得进程异常退出等。
情况二:代码错误导致进程运行时异常退出。
例如,代码当中存在野指针问题使得进程运行时异常退出,或是出现除0的情况使得进程运行时异常退出等。
-
Linux
+关注
关注
87文章
11391浏览量
211768 -
PID
+关注
关注
37文章
1477浏览量
86541 -
函数
+关注
关注
3文章
4359浏览量
63488 -
数据结构
+关注
关注
3文章
573浏览量
40394 -
Fork
+关注
关注
0文章
14浏览量
3397
发布评论请先 登录
相关推荐
Linux中进程和线程的深度对比








 工商网监
工商网监
评论