 OpenAI最新突破性进展:语言模型可以解释语言模型中的神经元
OpenAI最新突破性进展:语言模型可以解释语言模型中的神经元
大家好,我是zenRRan。
OpenAI在昨天发布了一篇论文:《Language models can explain neurons in language models》,可谓是深度学习可解释性又向前迈了一大步!谁又能想到,使用GPT-4来解释模型的可解释性,用魔法打败魔法,666。

大致内容
使用 GPT-4 自动编写大型语言模型中神经元行为的解释,并对这些解释进行打分,并为 GPT-2 中的每个神经元发布了这些(不完美的)解释和分数的数据集。
介绍一下
语言模型变得更强大,部署更广泛,但我们对它们内部工作原理的理解仍然非常有限。例如,可能很难从它们的输出中检测到它们是使用有偏见的启发式方法还是进行胡编乱造。可解释性研究旨在通过查看模型内部来发现更多信息。
可解释性研究的一种简单方法是首先了解各个组件(神经元和注意力头)在做什么。传统上,这需要人类手动检查神经元,以确定它们代表数据的哪些特征。这个过程不能很好地扩展:很难将它应用于具有数百或数千亿个参数的神经网络。OpenAI提出了一个自动化过程,该过程使用 GPT-4 来生成神经元行为的自然语言解释并对其进行评分,并将其应用于另一种语言模型中的神经元。
这项工作是对齐研究方法的第三个支柱的一部分:希望使对齐研究工作本身自动化。这种方法的一个有前途的方面是它可以随着人工智能发展的步伐而扩展。随着未来的模型作为助手变得越来越智能和有用,我们会找到更好的解释。
具体如何工作的呢
他们的方法包括在每个神经元上运行 3 个步骤。
第 1 步:使用 GPT-4 生成解释
给定一个 GPT-2 神经元,通过向 GPT-4 显示相关文本序列和激活来生成对其行为的解释。
OpenAI一共举了12个例子,这里我就随便拿出几个代表性的吧。

漫威漫画的氛围
模型生成的解释:参考自电影、角色和娱乐。

similes,相似
模型生成的解释:比较和类比,常用“喜欢(like)”这个词。
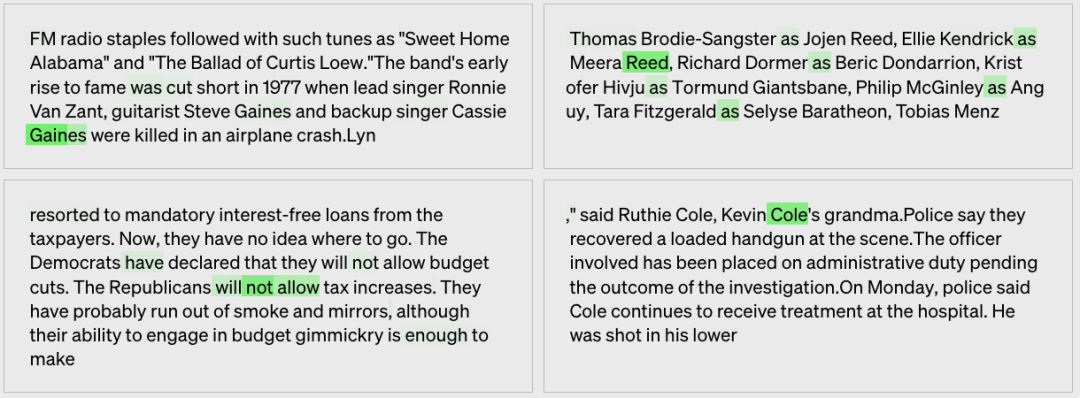
shared last names,姓氏
模型生成的解释:姓氏,它们一般跟在名字后面。
第 2 步:使用 GPT-4 进行模拟
再次使用 GPT-4 模拟为解释而激活的神经元会做什么。

漫威漫画的氛围
第 3 步:比较
根据模拟激活与真实激活的匹配程度对解释进行评分
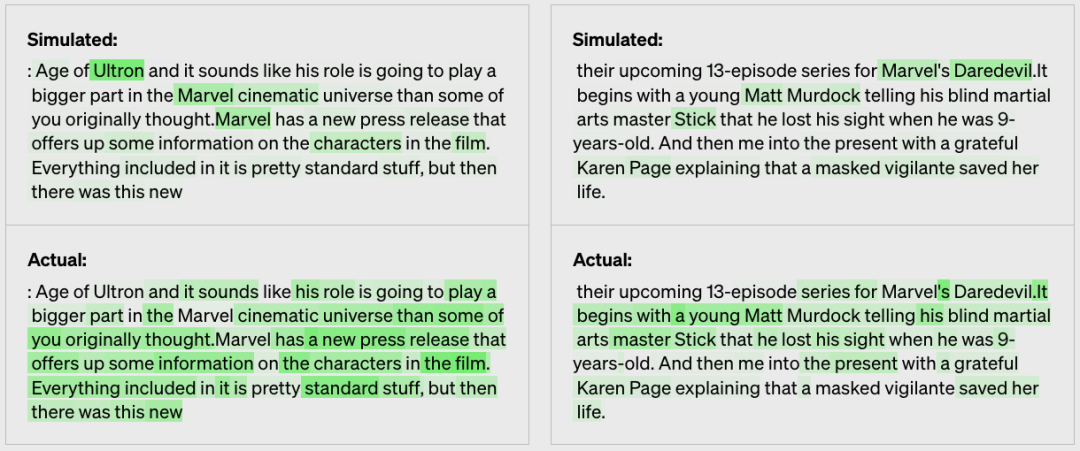
举例:漫威漫画的氛围
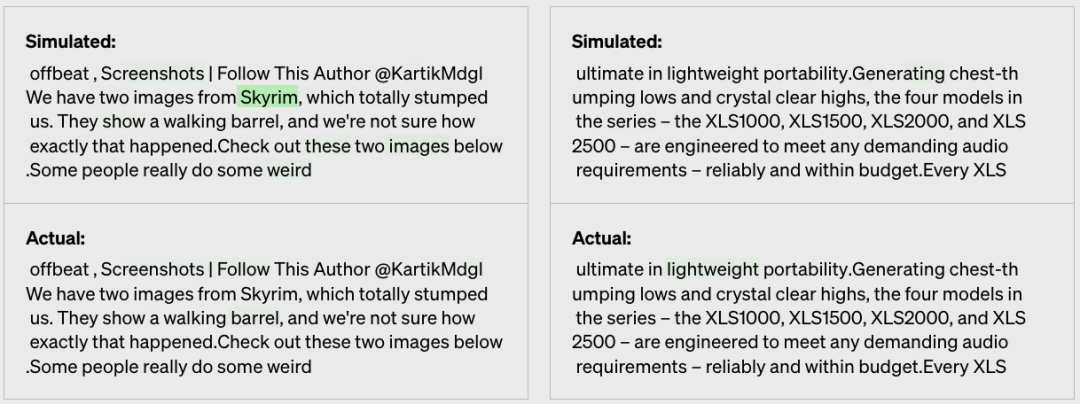
举例:漫威漫画的氛围
最终得出比较的分数为:0.34
发现了什么
使用OpenAI自己的评分方法,可以开始衡量技术对网络不同部分的工作情况,并尝试改进目前解释不力的部分的技术。例如,我们的技术对于较大的模型效果不佳,可能是因为后面的层更难解释。
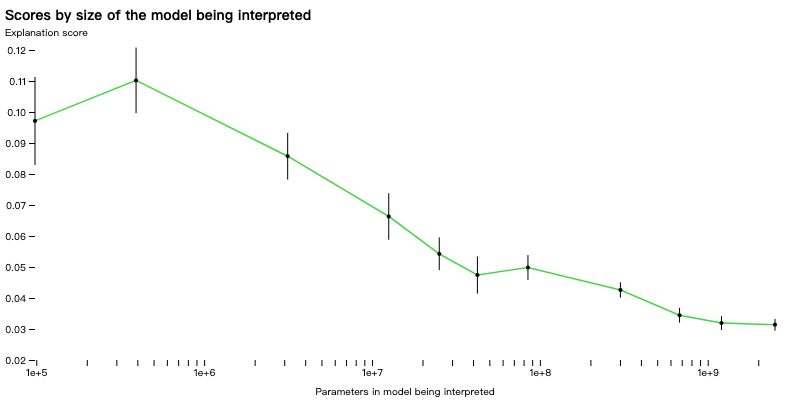
正在解释的模型中的参数量
尽管我们的绝大多数解释得分很低,但我们相信我们现在可以使用 ML 技术来进一步提高我们产生解释的能力。例如,我们发现我们可以通过以下方式提高分数:
迭代解释。我们可以通过要求 GPT-4 提出可能的反例,然后根据它们的激活修改解释来提高分数。
使用更大的模型来给出解释。随着解释器模型能力的提高,平均分数也会上升。然而,即使是 GPT-4 也给出了比人类更差的解释,这表明还有改进的余地。
更改已解释模型的架构。具有不同激活函数的训练模型提高了解释分数。
我们正在开源我们的数据集和可视化工具,用于 GPT-4 对 GPT-2 中所有 307,200 个神经元的书面解释,以及使用 OpenAI API 上公开可用的模型[1]进行解释和评分的代码。我们希望研究界能够开发新技术来生成更高分的解释,并开发更好的工具来使用解释来探索 GPT-2。
我们发现超过 1,000 个神经元的解释得分至少为 0.8,这意味着根据 GPT-4,它们解释了神经元的大部分顶级激活行为。大多数这些很好解释的神经元都不是很有趣。然而,也发现了许多 GPT-4 不理解的有趣神经元。希望随着解释的改进,能够快速发现对模型计算的有趣的定性理解。
神经元跨层激活,更高的层更抽象:

以Kat举例
展望
我们的方法目前有很多局限性[2],我们希望在未来的工作中能够解决这些问题。
我们专注于简短的自然语言解释,但神经元可能具有非常复杂的行为,无法简洁地描述。例如,神经元可以是高度多义的(代表许多不同的概念),或者可以代表人类不理解或无法用语言表达的单一概念。
我们希望最终自动找到并解释实现复杂行为的整个神经回路,神经元和注意力头一起工作。我们当前的方法仅将神经元行为解释为原始文本输入的函数,而没有说明其下游影响。例如,一个在句号上激活的神经元可以指示下一个单词应该以大写字母开头,或者递增一个句子计数器。
我们解释了神经元的行为,但没有试图解释产生这种行为的机制。这意味着即使是高分解释也可能在分布外的文本上表现很差,因为它们只是描述了相关性。
我们的整个过程是计算密集型的。
我们对我们方法的扩展和推广感到兴奋。最终,我们希望使用模型来形成、测试和迭代完全通用的假设,就像可解释性研究人员所做的那样。
最终,OpenAI希望将最大的模型解释为一种在部署前后检测对齐和安全问题的方法。然而,在这些技术能够使不诚实等行为浮出水面之前,我们还有很长的路要走。
审核编辑 :李倩
-
神经元
+关注
关注
1文章
363浏览量
18450 -
语言模型
+关注
关注
0文章
523浏览量
10277 -
OpenAI
+关注
关注
9文章
1087浏览量
6503
原文标题:OpenAI最新突破性进展:语言模型可以解释语言模型中的神经元
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【《大语言模型应用指南》阅读体验】+ 基础知识学习
【《大语言模型应用指南》阅读体验】+ 基础篇
人工神经元模型的基本构成要素
人工神经元模型的基本原理是什么
人工神经元模型由哪两部分组成
人工神经元模型的基本原理及应用
人工神经元模型的三要素是什么
基于神经网络的语言模型有哪些
名单公布!【书籍评测活动NO.34】大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程
【大语言模型:原理与工程实践】大语言模型的应用
【大语言模型:原理与工程实践】核心技术综述
【大语言模型:原理与工程实践】揭开大语言模型的面纱
大语言模型(LLMs)如何处理多语言输入问题






 工商网监
工商网监
评论