 Linux 性能优化总结!3
Linux 性能优化总结!3

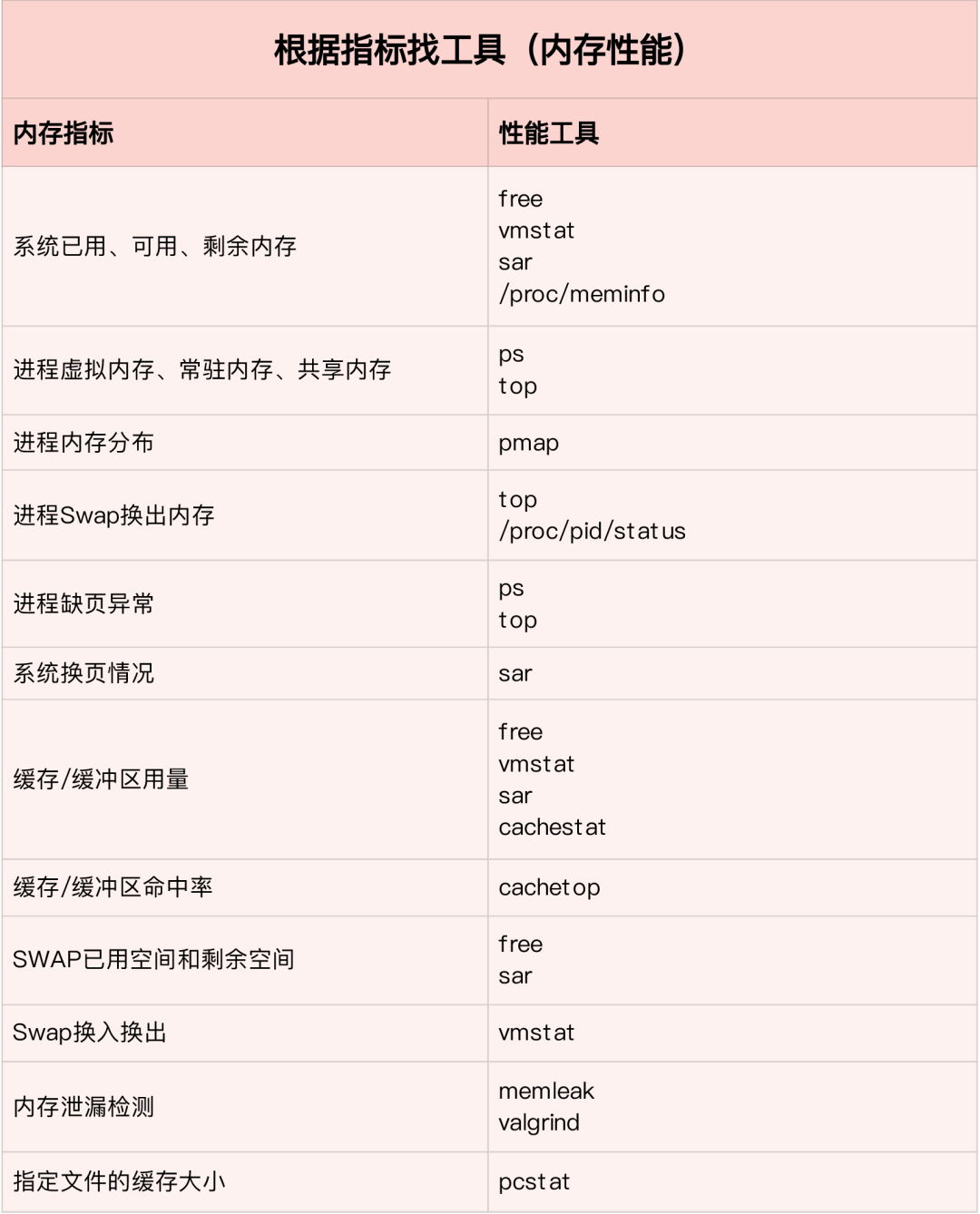
如何迅速分析内存的性能瓶颈
通常先运行几个覆盖面比较大的性能工具,如 free,top,vmstat,pidstat 等
- 先用 free 和 top 查看系统整体内存使用情况
- 再用 vmstat 和 pidstat,查看一段时间的趋势,从而判断内存问题的类型
- 最后进行详细分析,比如内存分配分析,缓存/缓冲区分析,具体进程的内存使用分析等
常见的优化思路:
- 最好禁止 Swap,若必须开启则尽量降低 swappiness 的值
- 减少内存的动态分配,如可以用内存池,HugePage 等
- 尽量使用缓存和缓冲区来访问数据。如用堆栈明确声明内存空间来存储需要缓存的数据,或者用 Redis 外部缓存组件来优化数据的访问
- cgroups 等方式来限制进程的内存使用情况,确保系统内存不被异常进程耗尽
- /proc/pid/oom_adj 调整核心应用的 oom_score,保证即使内存紧张核心应用也不会被OOM杀死
vmstat 使用详解
vmstat 命令是最常见的 Linux/Unix 监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的 CPU 使用率,内存使用,虚拟内存交换情况,IO读写情况。可以看到整个机器的 CPU,内存,IO 的使用情况,而不是单单看到各个进程的 CPU 使用率和内存使用率(使用场景不一样)。
vmstat 2procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0 0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0 0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0 0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0 0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0 0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0 1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0 1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0 1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0 1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0 0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0 0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0 1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0 0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0 0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0 1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0
# 结果说明- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- in 每秒CPU的中断次数,包括时间中断
- cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id 空闲CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
- wt 等待IO CPU时间pidstat 使用详解
pidstat 主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。
使用方法:
- pidstat –d interval times 统计各个进程的IO使用情况
- pidstat –u interval times 统计各个进程的CPU统计信息
- pidstat –r interval times 统计各个进程的内存使用信息
- pidstat -w interval times 统计各个进程的上下文切换
- p PID 指定PID
1、统计 IO 使用情况
pidstat -d 1 10
03:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-803:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun03:02:03 PM 997 7326 0.00 1904.95 918.81 java03:02:03 PM 997 8539 0.00 3.96 0.00 java03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent
03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-803:02:04 PM 997 7326 0.00 11156.00 1888.00 java03:02:04 PM 997 8539 0.00 4.00 0.00 java- UID
- PID
- kB_rd/s:每秒进程从磁盘读取的数据量 KB 单位 read from disk each second KB
- kB_wr/s:每秒进程向磁盘写的数据量 KB 单位 write to disk each second KB
- kB_ccwr/s:每秒进程向磁盘写入,但是被取消的数据量,This may occur when the task truncates some dirty pagecache.
- iodelay:Block I/O delay,measured in clock ticks
- Command:进程名 task name
2、统计 CPU 使用情况
# 统计CPUpidstat -u 1 1003:03:33 PM UID PID %usr %system %guest %CPU CPU Command03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansible- UID
- PID
- %usr: 进程在用户空间占用 cpu 的百分比
- %system: 进程在内核空间占用 CPU 百分比
- %guest: 进程在虚拟机占用 CPU 百分比
- %wait: 进程等待运行的百分比
- %CPU: 进程占用 CPU 百分比
- CPU: 处理进程的 CPU 编号
- Command: 进程名
3、统计内存使用情况
# 统计内存pidstat -r 1 10Average: UID PID minflt/s majflt/s VSZ RSS %MEM CommandAverage: 0 1 0.20 0.00 191256 3064 0.01 systemdAverage: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDunAverage: 0 6642 0.10 0.00 6301904 107680 0.33 javaAverage: 997 7326 10.89 0.00 13468904 8395848 26.04 javaAverage: 0 7795 348.15 0.00 108376 1233 0.00 pidstatAverage: 997 8539 0.50 0.00 8242256 2062228 6.40 javaAverage: 987 9518 0.20 0.00 6300944 1242924 3.85 javaAverage: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-serviceAverage: 984 15517 0.40 0.00 6386464 1464572 4.54 javaAverage: 0 16066 236.46 0.00 2678332 71020 0.22 cmagentAverage: 995 20955 0.30 0.00 6312520 1408040 4.37 javaAverage: 995 20956 0.20 0.00 6093764 1505028 4.67 javaAverage: 0 23936 0.10 0.00 5302416 110804 0.34 javaAverage: 0 24406 0.70 0.00 10211672 2361304 7.32 javaAverage: 0 26870 1.40 0.00 1470212 36084 0.11 promtail- UID
- PID
- Minflt/s : 每秒次缺页错误次数 (minor page faults),虚拟内存地址映射成物理内存地址产生的 page fault 次数
- Majflt/s : 每秒主缺页错误次数 (major page faults), 虚拟内存地址映射成物理内存地址时,相应 page 在 swap 中
- VSZ virtual memory usage : 该进程使用的虚拟内存 KB 单位
- RSS : 该进程使用的物理内存 KB 单位
- %MEM : 内存使用率
- Command : 该进程的命令 task name
4、查看具体进程使用情况
pidstat -T ALL -r -p 20955 1 1003:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java
03:12:16 PM UID PID minflt-nr majflt-nr Command03:12:17 PM 995 20955 0 0 java-End-
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
缓冲区
+关注
关注
0文章
37浏览量
9570 -
数据
+关注
关注
8文章
7361浏览量
95128 -
SWAP
+关注
关注
0文章
52浏览量
13743 -
堆栈
+关注
关注
0文章
184浏览量
20602 -
Redis
+关注
关注
0文章
395浏览量
12273
发布评论请先 登录
相关推荐
热点推荐
HBase性能优化方法总结
,不要满额配置地使用网络,否则在高负载时,会影响HBase应用系统的性能。3. 操作系统操作系统的选择应考虑是否支持HBase,通常情况下选择Linux操作系统。4. 本地文件系统本地Linu
发表于 04-20 17:16
Linux系统的性能优化策略
近年来,世界上许多大软件公司纷纷推出各种Linux服务器系统及Linux下的应用软件。目前,Linux 已可以与各种传统的商业操作系统分庭抗礼,在服务器市场,占据了相当大的份额。本文分别从磁盘调优,文件系统,内存管理以及编译
发表于 07-16 06:23
基于Linux的Socket网络编程的性能优化
基于Linux的Socket网络编程的性能优化
随着Intenet的日益发展和普及,网络在嵌入式系统中应用非常广泛,越来越多的嵌入式设备采用Linux操作系统。
发表于 10-22 20:48
•1315次阅读



Linux CPU的性能应该如何优化
在Linux系统中,由于成本的限制,往往会存在资源上的不足,例如 CPU、内存、网络、IO 性能。本文,就对 Linux 进程和 CPU 的原理进行分析,总结出 CPU
Linux神优化Zen3:性能高出15%
Intel、AMD相爱相杀50年,现在两家是打得不可开交,然后在某些领域两边可能还是天作之合。对Linux用户来说,AMD的Zen3处理器现在是最好的CPU,而最佳系统则是Intel的Clear

Linux 性能优化总结!2
大多数计算机用的主存都是动态随机访问内存(DRAM),只有内核才可以直接访问物理内存。Linux内核给每个进程提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样进程就可以很方便的访问内存(虚拟内存)。
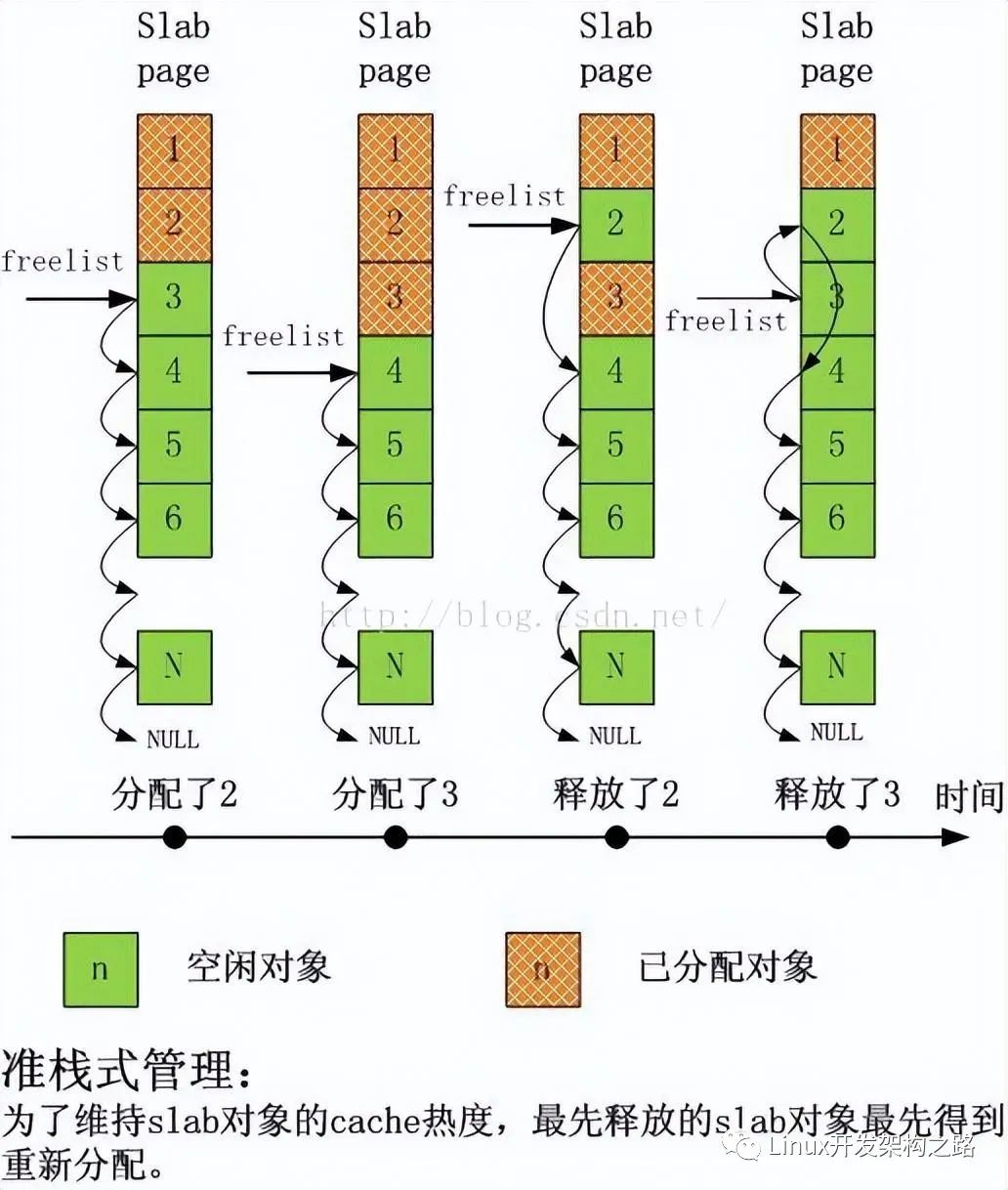
Linux内核slab性能优化的核心思想
今天分享一篇内存性能优化的文章,文章用了大量精美的图深入浅出地分析了Linux内核slab性能优化的核心思想,slab是
性能优化之路总结
针对老项目,去年做了许多降本增效的事情,其中发现最多的就是接口耗时过长的问题,就集中搞了一次接口性能优化。本文将给小伙伴们分享一下接口优化的通用方案。 一、接口优化方案
如何优化Linux服务器的性能
优化Linux服务器的性能是一个综合性的任务,涉及硬件、软件、配置、监控等多个方面。以下是一个详细的指南,旨在帮助系统管理员和运维人员提升Linux服务器的
Linux系统性能优化技巧
经过10年一线运维经验,我发现大多数工程师只掌握了Linux优化的冰山一角。今天分享的这些秘技,能让你的系统性能提升200%以上!



评论