 什么样的模型更适合zero-shot?
什么样的模型更适合zero-shot?
什么样的模型更适合zero-shot?
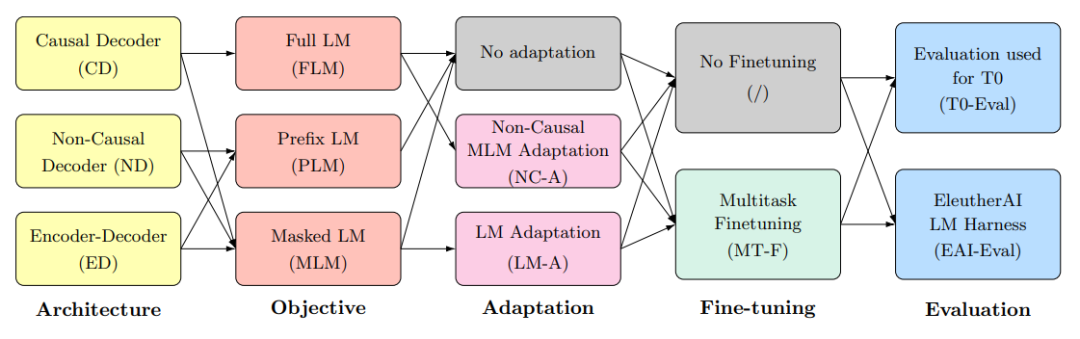
对于模型架构,不同的论文有不同的分发,不同的名称。我们不必纠结于称谓,在这里我们延续BigScience的概念来讨论,即:
- 架构:自回归、非自回归、编码器-解码器
- 目标:全语言模型、前缀语言模型、掩码语言模型
- 适配器:不添加适配器、将自回归模型用于掩码目标训练的适配器、将掩码为目标的模型转化为纯语言模型目标
- 是否经过多任务微调
- 评估数据集:EAI-Eval、T0-Eval
BigScience有两项重要的结论,但这两项结论是在控制预训练的预算的基础上的,而非控制参数量。如此实验编码器-解码器用了11B参数量,而纯解码器却是4.8B。
- 如果不经过多任务微调,自回归模型最好,掩码语言模型跟随机结果一样。
- 如果经过多任务微调,编码器-解码器掩码模型最好【这参数量都翻倍了,很难说不是参数量加倍导致的】。换个角度想,在多任务微调之后,自回归全语言模型在参数量不到编码器-解码器掩码模型一半,计算量还少10%的情况下,效果还能差不多。
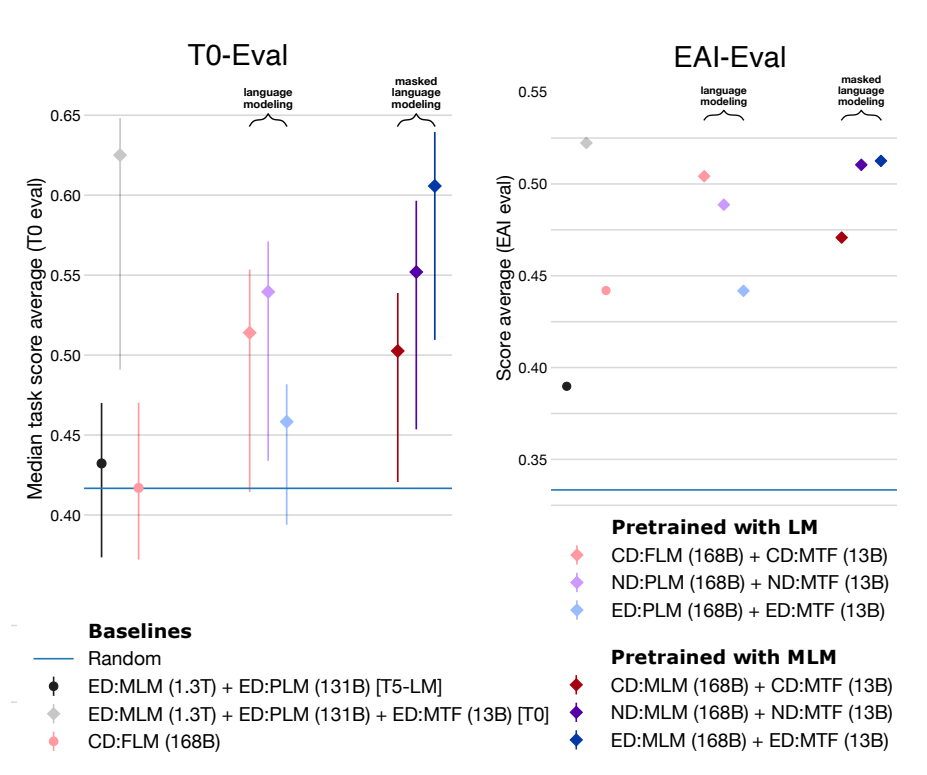
来自科学空间的对比实验【https://spaces.ac.cn/archives/9529】更是印证了这一点:
在同等参数量、同等推理成本下,Decoder-only架构很可能是最优选择。
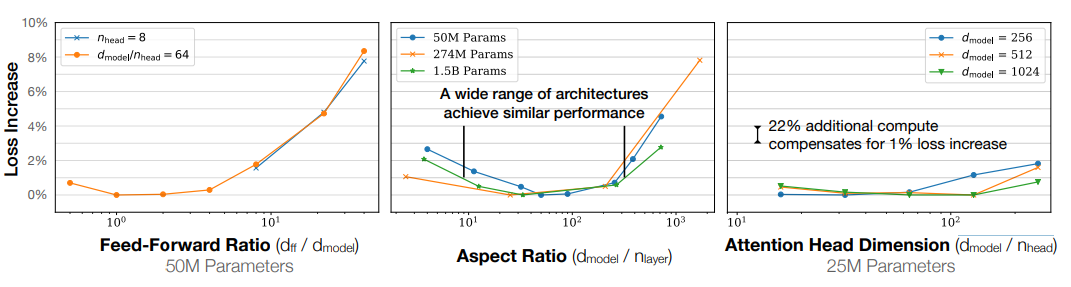
效果和模型形状有没有关系
在openAI的实验中,通过控制参数量,分别调整模型形状的三个指标前馈维度比、宽高比、注意力头维度,实验表明,模型形状对性能的依赖非常轻微。
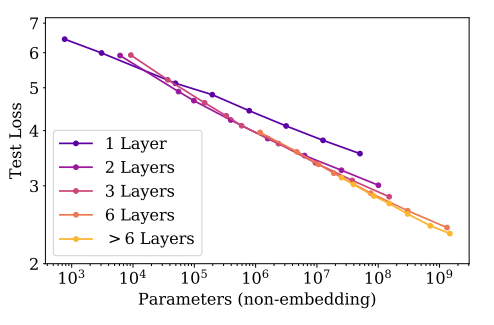
单独研究层数,排除嵌入层的影响,除了一层这种极端情况之外,同样参数下,不同的层数倾向于收敛于同样的损失。
到底需要多少数据训练
在GPT-3中参数数据比约为1:1.7,而Chinchilla是为1:20。然而GPT-3参数量是Chinchilla的2.5倍,下游任务却大范围地输给了Chinchilla。再看LLaMA就更离谱了约为1:77,只有13B参数量很多任务就超越了GPT-3。这是不是和咱公众号名字很符合:【无数据不智能】,海量高质量数据才是王道。
| Model | Parameters | Training Tokens |
|---|---|---|
| LaMDA (2022) | 137 Billion | 168 Billion |
| GPT-3 (2020) | 175 Billion | 300 Billion |
| Jurassic (2021) | 178 Billion | 300 Billion |
| Gopher (2021) | 280 Billion | 300 Billion |
| MT-NLG 530B (2022) | 530 Billion | 270 Billion |
| Chinchilla(202) | 70 Billion | 1.4 Trillion |
| LLaMA(202) | 13 Billion | 1.0 Trillion |
批次大小设置为多少好
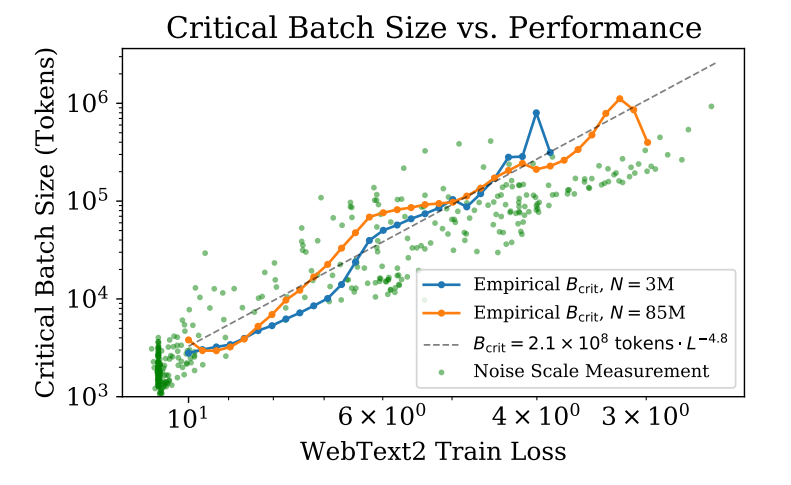
【Scaling Laws for Neural Language Models】实验中表明batch size和模型大小无关,只和想达到的loss有关(幂次关系),同时也受到噪声数据的影响。
学习率多大合适
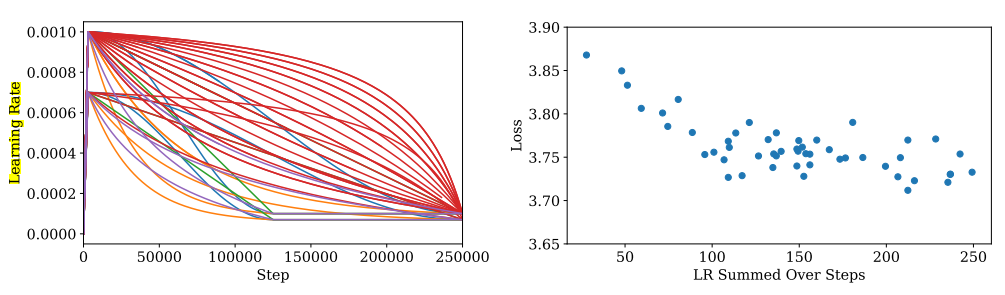
- 只要学习率不是太小,衰减不是太快,性能对学习率的依赖性并不强。
- 较大的模型需要较小的学习率来防止发散,而较小的模型可以容忍较大的学习率。
- 经验法则:LR(N) ≈ 0.003239 − 0.0001395log(N),N:模型参数量
参数量、数据量、训练时长和loss什么关系
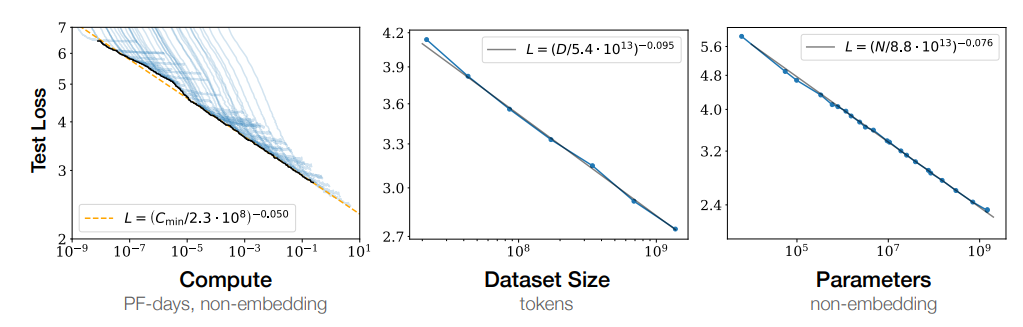
参数量、数据量、训练时长和loss都存在幂指数关系
审核编辑 :李倩
-
解码器
+关注
关注
9文章
1143浏览量
40742 -
编码器
+关注
关注
45文章
3643浏览量
134528 -
模型
+关注
关注
1文章
3244浏览量
48847
原文标题:引用
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于将 CLIP 用于下游few-shot图像分类的方案
震动环境下适合用什么样的液晶屏
请问GTR的双晶体管模型是什么样的?
NLP事件抽取综述之挑战与展望
Zero-shot-CoT是multi-task的方法
基于Zero-Shot的多语言抽取式文本摘要模型
介绍一个基于CLIP的zero-shot实例分割方法
从预训练语言模型看MLM预测任务
基于GLM-6B对话模型的实体属性抽取项目实现解析
大模型LLM领域,有哪些可以作为学术研究方向?

迈向多模态AGI之开放世界目标检测
基于通用的模型PADing解决三大分割任务

为什么叫shot?为什么shot比掩膜版尺寸小很多?

基于显式证据推理的few-shot关系抽取CoT





 工商网监
工商网监
评论