 AIGC需求大爆发,英伟达算力芯片已涨价近四成
AIGC需求大爆发,英伟达算力芯片已涨价近四成

电子发烧友网报道(文/吴子鹏)日前,有代理商透露,英伟达的A100价格从2022年12月份开始上涨,截至2023年4月上半月,5个月价格累计涨幅达到37.5%;在中国市场,A800价格从2022年12月份开始上涨,截至2023年4月上半月,5个月价格累计涨幅达20.0%。
目前,对于所有AI大模型而言,无论是推理还是训练,基本都是依赖英伟达的GPU芯片。其中,英伟达A100芯片是目前的主流,在大模型训练市场的市占比接近100%。
英伟达算力芯片量价齐升
根据此前的公开报道,OpenAI的GPT-3大模型参数规模已经达到1750亿,因此在训练过程中需要做大量的数据并行计算,这就是为什么AI 大模型都要哄抢GPGPU。
所谓的GPGPU又名通用算力GPU,能够帮助CPU进行非图形相关程序的运算——复杂的数值计算、物理模拟和数据分析等任务。GPGPU在进行相关运算时有几大突出的优势,高效并行性、高密集运算、超长流水线等。
那么,为什么只有英伟达有AI淘金浪潮“卖铲人”的称号呢?
主要原因有两点,其一是英伟达芯片的算力更高,比如英伟达的A100,这颗采用Ampere架构和7nm制程的芯片里晶体管数量达542亿颗,单芯片可提供的FP32峰值算力为19.5TFLOPS。如果是英伟达的H100 SXM,FP32峰值算力为67TFLOPS,提升明显。并且,无论是A100还是H100都能够提供包括FP64、TF32、FP32、FP16 和INT8在内的所有算力精度。
在高算力方面,我们都知道,先进芯片和先进算力之间并不是画等号的,在算力集群里,传输也是极为重要的。为了保障传输,英伟达给H100配备了可提供 900 GB/s GPU 间互连的第四代NVlink、可跨节点加速每个GPU通信的NVLINK Switch系统、PCIe 5.0,以保障高效的算力集群。即便是目前主流的A100,英伟达也是为其配备了2TB/s的内存带宽,以及NVIDIA NVLink、NVIDIA NVSwitch、PCIe 4.0,用以保障传出。
其二是生态的优势。英伟达长期占据GPGPU的头把交椅,并在此过程中持续完善自己的生态。在算力利用的过程中,无论是学习、运算还是开发,往往都需要一个统一的开发架构,优秀的架构才能尽可能释放GPGPU的算力。在这方面,公开数据显示,英伟达的CUDA占据了全球大概80%以上的市场。其他公司做的基本都是对标CUDA,比如OpenAI的开发架构Triton,业界往往认为其是简化版的CUDA。目前,市场上很多芯片只能从理论算力上去对标英伟达,宣称能够达到英伟达某款芯片的几成,然而在实际应用中由于软件生态的缺失,是要进一步打折扣的。
算力和生态的优势让行业界对英伟达的A100和A800趋之若鹜。有代理商爆料称,目前英伟达主流算力芯片不仅价格走高,同时交货周期也被拉长,之前拿货周期大约为一个月,现在基本都需要三个月或更长。甚至,部分新订单“可能要到12月才能交付”。
产业苦英伟达久矣
目前,英伟达的GPGPU可以说就是AI大模型部署算力的标准。有专家曾表示,做好AI大模型的算力最低门槛是1万枚英伟达A100芯片。TrendForce研究则显示,以A100的算力为基础,GPT-3.5大模型需要高达2万枚GPU,未来商业化后可能需要超过3万枚。
业界还预估,国内大概只有3万块的英伟达A100芯片存量,其余用于AI大模型的都是新购进的A800特供版。因此,目前国内部分公司已经开始在内部做出限制,除AI大模型相关业务外,其余业务不允许使用A100或者A800提供的算力。
业界一边在尽力去追求英伟达的高端算力芯片,同时对于价格不断走高,且供货周期持续延长的英伟达芯片也是怨声载道。
因此,目前行业内不断有声音出现,要替代英伟达的相关芯片。
比如谷歌第二代TPU,在一些数据吞吐测试中,这款芯片已经能够和英伟达GPGPU相当。另外有分析师指出,由于一些公司买不到英伟达的高端GPGPU,因此选择将模型做小,然后选择AMD公司的CPU或者Cerebras的WSE来进行部署,进而促进了垂直领域和AI大模型的结合。
在国内,也已经有一些公司在推出方案,尝试在AI大模型领域取代英伟达的芯片。
后记
根据相关统计数据,英伟达A100芯片已经贡献目前全球数据中心和算力中心业务的50%,成为该公司的摇钱树。在国内市场,几天前的报道指出,A800芯片在国内售价被炒到超过10万元/颗,而且是低配的版本。然而,AIGC时代里,算力就是王道,因此算力芯片便物以稀为贵。
-
英伟达
+关注
关注
23文章
4124浏览量
99742 -
AIGC
+关注
关注
1文章
393浏览量
3282
发布评论请先 登录
英伟达失守中国区!推理需求爆发,国产GPU抢滩上市

国产算力出海元年开启

GPU不是AI的唯一解:英伟达用Groq LPU证明,推理赛道需要“另一条腿”


AI算力需求的爆发加速国产晶振替代进程
英伟达Rubin GPU采用钻石铜散热,解决芯片散热难题

HBM3E反常涨价20%,AI算力竞赛重塑存储芯片市场格局

英伟达 Q3 狂揽 308 亿
英伟达最新B30A芯片曝光:算力角逐中的新变数
英伟达被约谈!“后门”风险阴影下,人脸识别终端为何选国产芯片

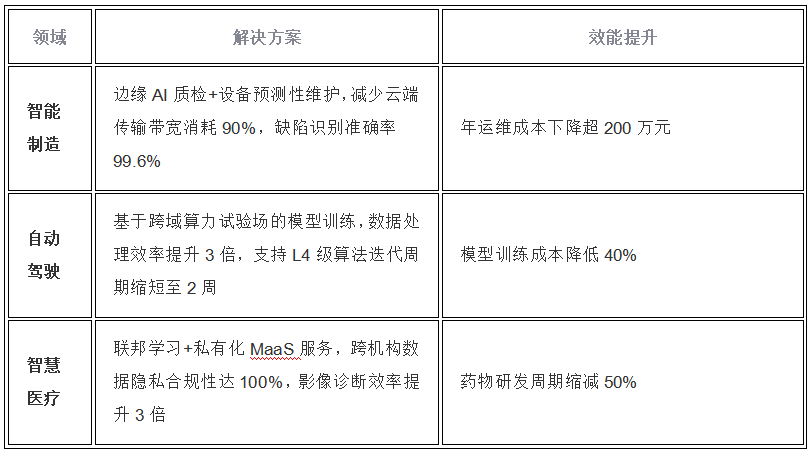
AIGC算力基础设施技术架构与行业实践



评论