 ChatGPT从入门到深入
ChatGPT从入门到深入
ChatGPT从入门到深入(持续更新中)
循环记忆输入
Recurrent Memory Transformer (RMT)
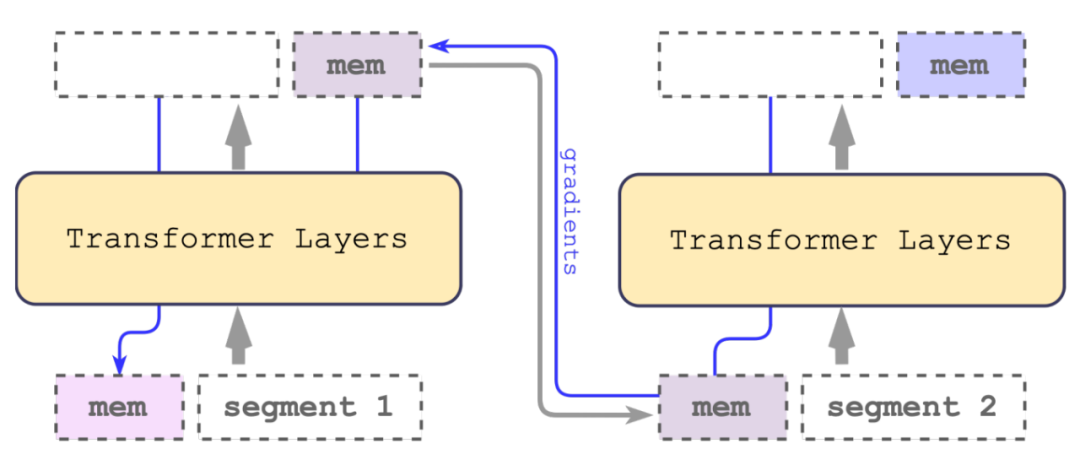
总体思想:将长文本分段之后得到嵌入向量与记忆向量拼接,得到新的记忆向量之后与下一段再循环输入transformer。
注意:此论文实验结果在bert-base-cased(encoder-only上进行实验)
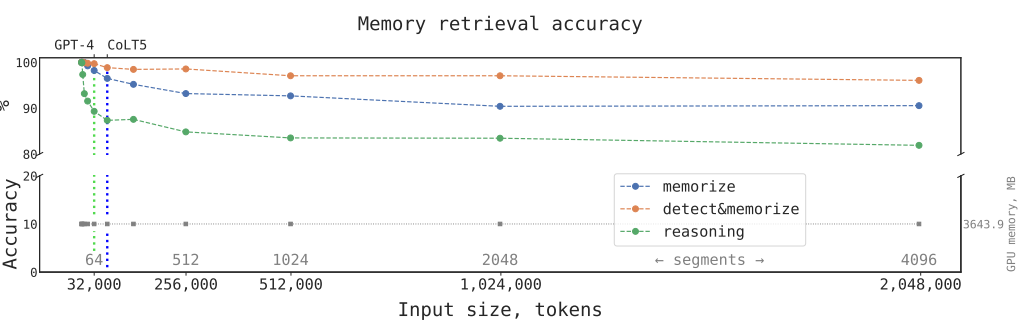
CoLT5达到64K,GPT-4达到32K长度,而RMT在实验结果中长度加到4096个分段2048000词汇,效果依然强劲。
用提示词
Self-Controlled Memory (SCM)
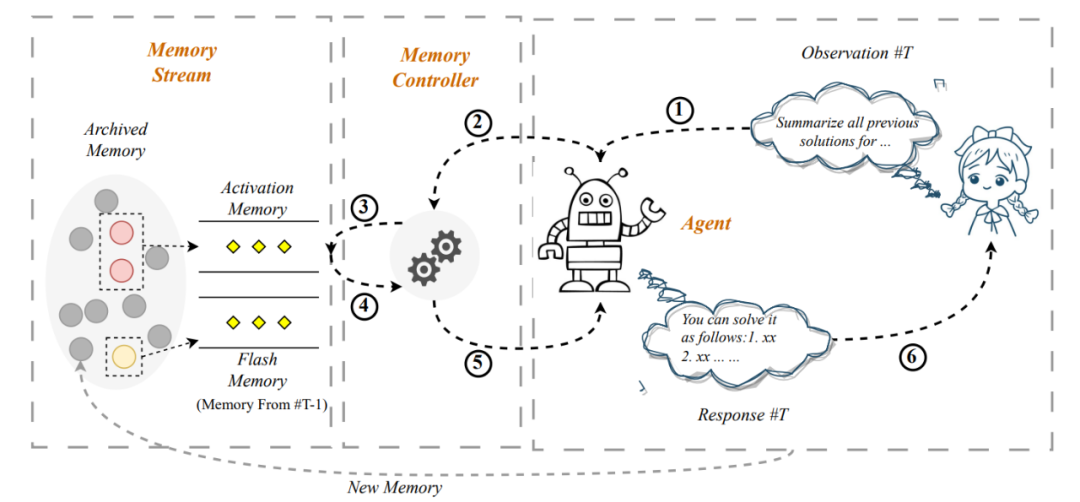
如上图所示,此方法号称可以将输入延申至无限长,具体流程为:
-
用户输入
-
判断是否需要从历史会话中获得记忆,提示词如下:
给定一个用户指令,判断执行该指令是否需要历史信 息或者上文的信息,或者需要回忆对话内容,只需要 回答是(A)或者否(B),不需要解释信息: 指令:[用户输入] -
如果需要获取记忆,通过相关性(余弦相似度)、近期性分数相加对历史记忆进行排序
-
将记忆摘要
以下是用户和人工智能助手的一段对话,请分 别用一句话写出用户摘要、助手摘要,分段列 出,要求尽可能保留用户问题和助手回答的关 键信息。 对话内容: 用户:[用户输入] 助手:[系统回复] 摘要: -
将记忆和输入拼接输入模型
以下是用户和人工智能助手的对话,请根据历史 对话内容,回答用户当前问题: 相关历史对话: [历史轮对话内容] 上一轮对话: [上一轮对话内容] ### 用户:[用户问题] 助手: -
回复
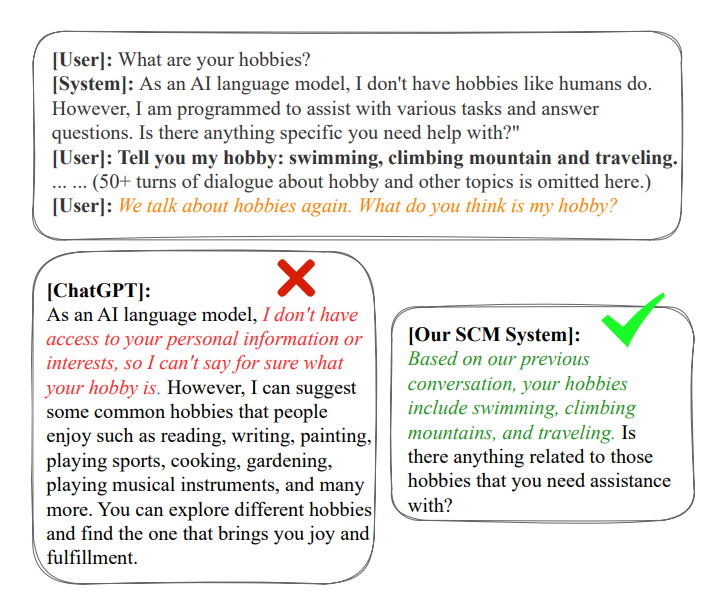
注意:此论文中只进行了定性分析,没有定量实验。以下是效果图:
词汇压缩
VIP-token centric compression (Vcc)
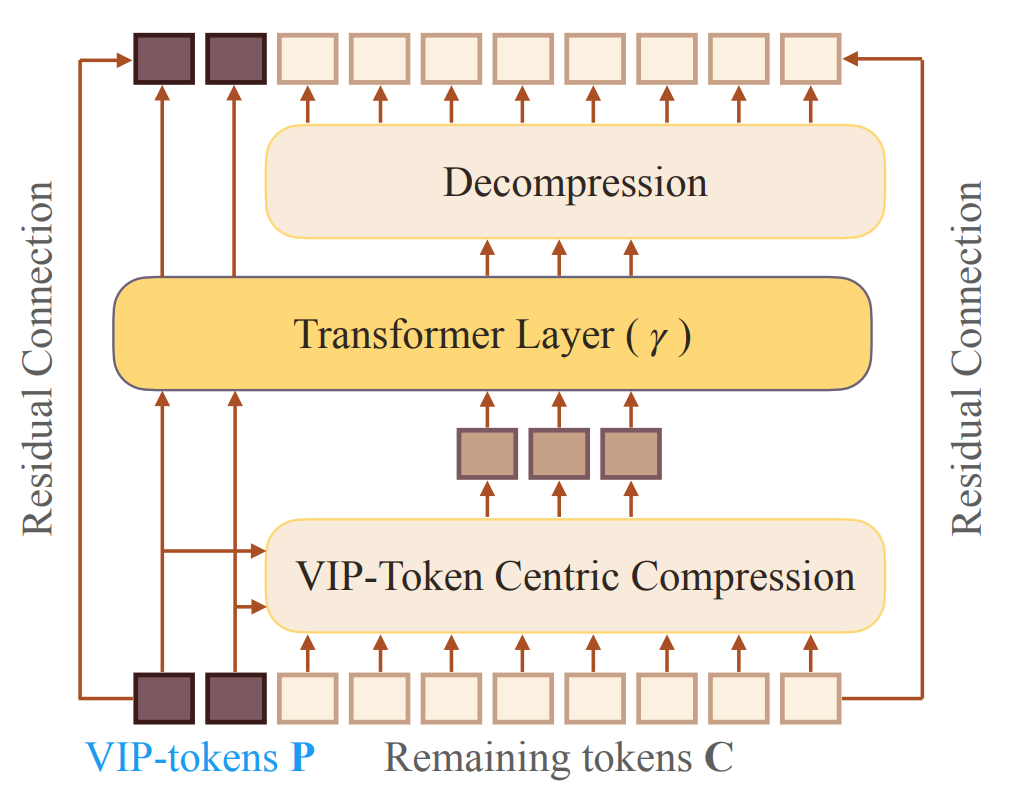
该方法使得模型输入延申至128K,并在Encoder-Only、Encoder-Decoder两种模型架构上都进行了实验。
一句话描述思想:使模型输入长度独立于文本长度。
具体一点:
- 将当前问句视为vip-token
- 利用当前问句与历史记忆的关系,压缩历史记忆到模型输入长度,无论历史记忆有多长
- transformer层输出之后再进行解压缩
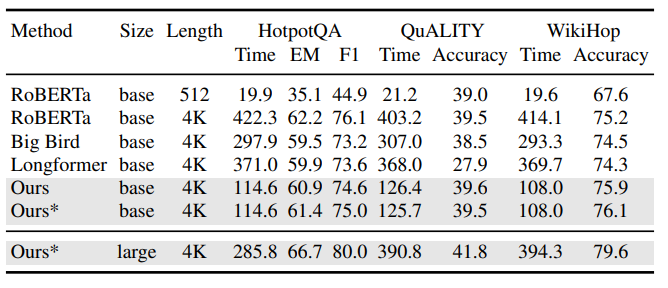
Encoder-Only架构表现:
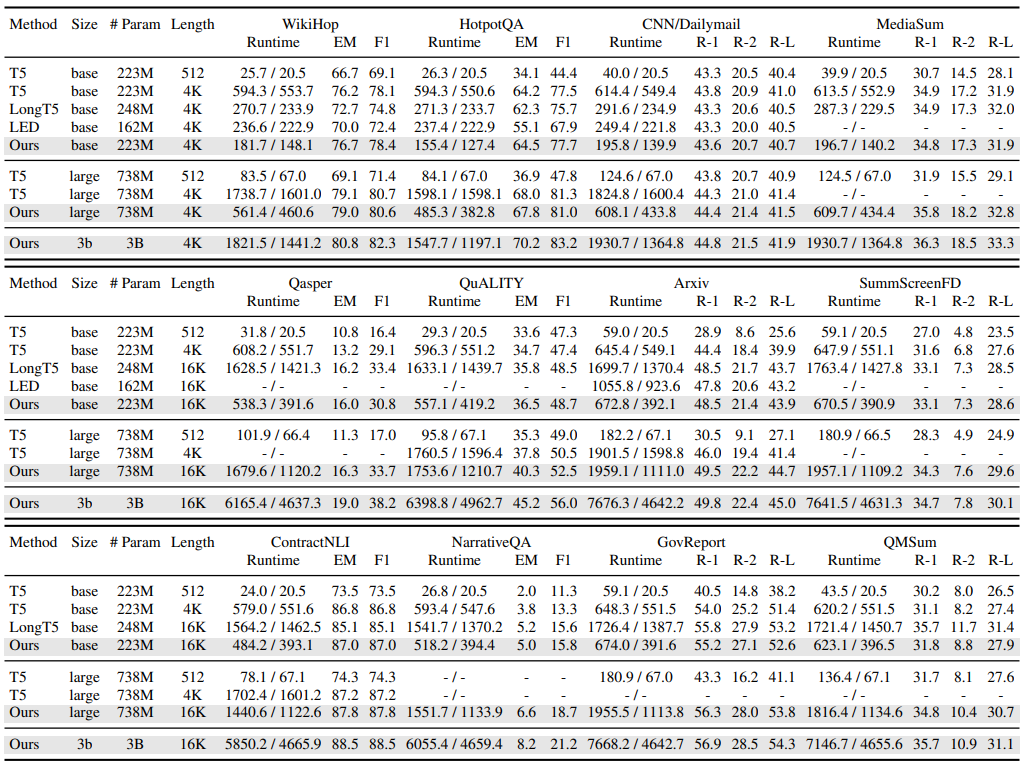
Encoder-Decoder表现:
检索+交叉注意力
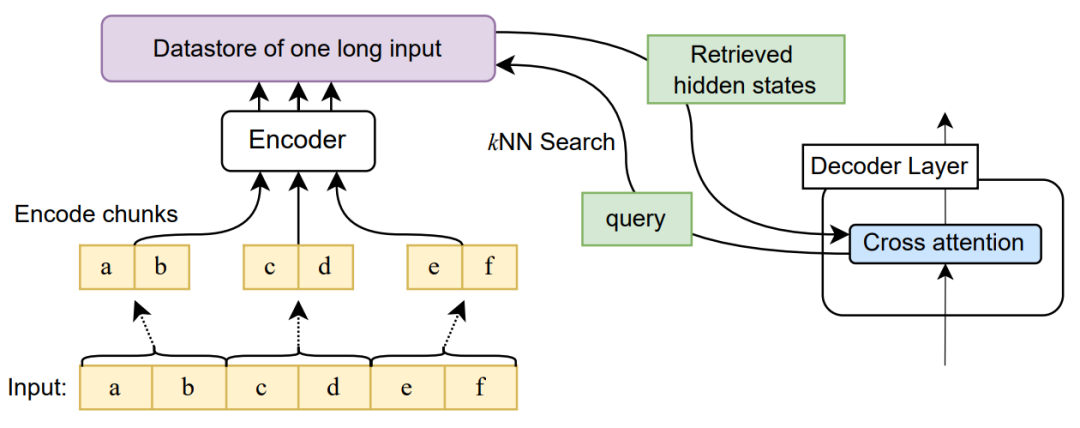
此方法只试用于Encoder-Decoder架构,其也称可以将输入长度延申至无限长。
思路如下:
- 将长文本分成多个部分,将每一段进行编码
- 利用query KNN检索长文本topN
- 解码器对相关段落编码后的隐藏状态进行交叉注意力
- 得到输出
可以看到此方法在长文本摘要任务上都取得了优异的结果
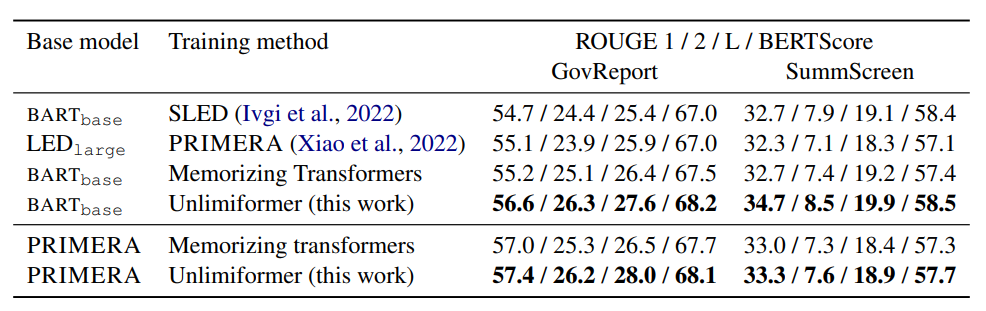
累加
简单介绍一下ALiBi:
- 不再输入层保留位置向量
- 而在每层注入线性的偏移量,注意力分数从:
变成了:
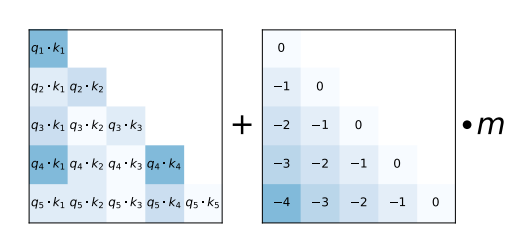
可以看到ALiBi比Sinusoidal、Rotary、T5 Bias在长距离输入上效果都要好得多。
mosaicml/mpt-7b模型利用ALiBi将输入长度扩展至了84k,核心的思想为一下几行代码:
all_hidden_states=()ifoutput_hidden_stateselseNone
for(b_idx,block)inenumerate(self.blocks):
ifoutput_hidden_states:
assertall_hidden_statesisnotNone
all_hidden_states=all_hidden_states+(x,)
past_key_value=past_key_values[b_idx]ifpast_key_valuesisnotNoneelseNone
(x,past_key_value)=block(x,past_key_value=past_key_value,attn_bias=attn_bias,attention_mask=attention_mask,is_causal=self.is_causal)
ifpast_key_valuesisnotNone:
past_key_values[b_idx]=past_key_value
即MPT会对上次得到隐藏状态与本次的输入进行相加。
审核编辑 :李倩
-
人工智能
+关注
关注
1800文章
48094浏览量
242228 -
ChatGPT
+关注
关注
29文章
1579浏览量
8304
原文标题:引用
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论